AtCoderのABCで詰まった時の思考(解法)のヒント(助け)
Aru
Aru's テクログ(Aruaru0)

pandasのデータフレームで行抽出を行う方法は複数ありますが、query()メソッドは直感的に記述しやすく便利です。ただ、速度面が気になりましたので、ベンチマークを行い検証してみました。この記事では、巨大なデータフレームを作成し、query()を使った行抽出と他の手法の速度を比較します。
結果、query()が同等または若干高速なことを確認できました。また、numexprライブラリをインストールすることで、さらにパフォーマンスが向上することもわかりました。queryを使った行抽出は記述がわかりやすく読みやすいので、パフォーマンスが同等以上なら積極的に利用すべきだと感じました。
実験用のデータフレームは、scikit-learnのmake_classificationを使って作成しました。

自分で乱数を使って作成しても良かったですが、手軽なのでこちらを利用しました。なお、make_classificationで作成したデータセットは、実際にクラス分類問題のサンプルとして利用可能です
実験用データフレームの作り方はこちらを参照してください

こちらについては、特に説明しません。この機能を使って10列×1,000万行のデータを作成しました。
1,000万行のデータを作成した理由は、小さなデータセットをループさせて計測すると、結果として実際に使う場合より遅く見えてしまうことがあるからです(小さなデータセットで速度が遅くても、実際に使うサイズのデータセットでは逆転することがよくあります)。
1億行のデータを作成しようとしましたが、メモリが足りなくてクラッシュしました。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
LOOP = 100
X, y = make_classification(n_samples=10000000, #1000万行のデータを生成
n_features=10,
n_informative=6,
n_classes=5,
random_state=42)
df = pd.DataFrame(X)
df['Y'] = y
df.columns = ['col_X' + str(i) for i in range(1, 11)] + ['col_Y']
df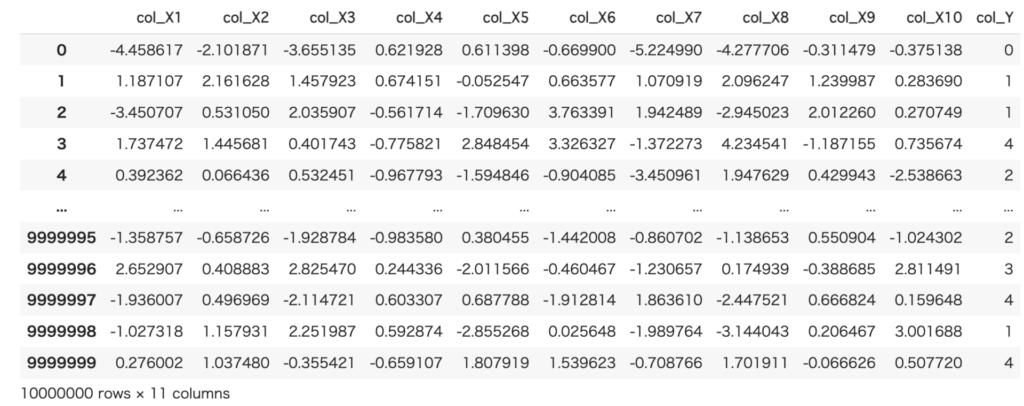
時間計測は、以下のようなコードで行っています。
「実行したい処理を記述」の部分に、抽出するコードを挿入しています。
import time
start = time.time() # 現在時刻(処理開始前)を取得
# 実行したい処理を記述
end = time.time() # 現在時刻(処理完了後)を取得
time_diff = end - start # 処理完了後の時刻から処理開始前の時刻を減算する
print(time_diff) # 処理にかかった時間データを使用具体例は以下の通りです
1000万行のデータフレームを用意しましたが、思ったより処理時間が短かったのでLOOP回繰り返して測定するようにしました。なお、LOOP=100です。
start = time.time()
for _ in range(LOOP):
sel = df[df['col_X1'] > 0]
end = time.time()
time_diff = end - start
print(time_diff, "sec.")
display(sel)ここでは、複数の行抽出のパターンについて、それぞれベンチマークを行ってみまました。
大小比較による行の抽出です。queryを使わないバージョンと、queryを使ったバージョン、queryの閾値を変数で指定したバージョンの3つで処理時間を確認しました。
なお、qureyを使った方が書き方がシンプルになり、後で読みやすいです。
① queryを使わない記述
sel = df[df['col_X1'] > 0]② queryを使った記述
sel = df.query('col_X1 > 0')文字列をquery中に入れる場合は、全体をシングルクオート'で囲んだ場合は、文字列はダブルクオート"で囲めばOKです。逆にダブルクオート"で囲んだ場合はシングルクオート'で囲みます
例: df.query('name = "taro"')③ queryを使った記述(変数で閾値を設定)
val = 0
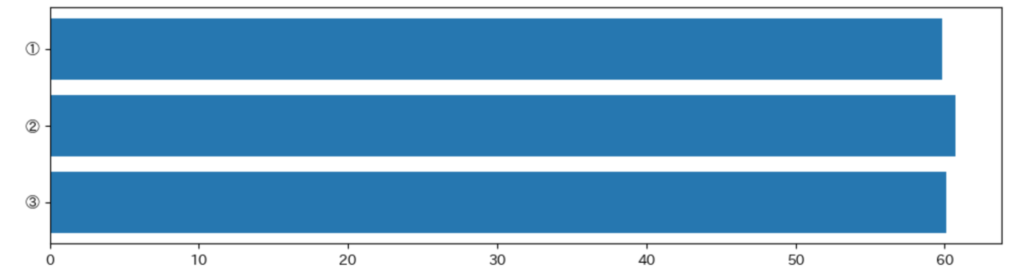
sel = df.query('col_X1 > @val')処理時間は以下になります。3つのコード、ほぼ時間差はない感じです。
| ① | 59.810264587402344 sec. |
| ② | 60.742764711380005 sec. |
| ③ | 60.072065591812134 sec. |
今回、Google Colabで計測しましたが、Google Colabは接続毎に割り当てられるCPUのスペックにかなりばらつきがある感じです。というのも、再接続して実行すると数秒単位で処理時間が変化しました。
ただ、queryを使わない場合も、queryを使う場合も同じように変わるので比較には問題ありません
グラフは短いほど高速です。
inを使って、特定の値の行を抽出するサンプルです。queryを使わない場合はisinを使います。queryの場合は、pythonの普通の構文に近い記述になります。
① queryを使わない記述
sel = df[df['col_Y'].isin([0,1])]② queryを使った記述
sel = df.query('col_Y in [0,1]')結果、queryの方が若干遅い結果となりました。
| ① | 61.545966148376465 sec. |
| ② | 71.81479215621948 sec. |

複数条件で行抽出するサンプルです
andで抽出行を絞り込むサンプルです。queryを使わないで複数条件で抽出する場合、()で各条件を囲むなど少し面倒です。条件が複雑になるとqueryが書きやすいです。
① queryを使わない記述
sel = df[(df['col_X1'] > 0) & (df['col_X2'] < 0) & (df['col_X3'] > 0) & (df['col_X4'] < 0.1) & (df['col_X5'] > 1)]② queryを使った記述
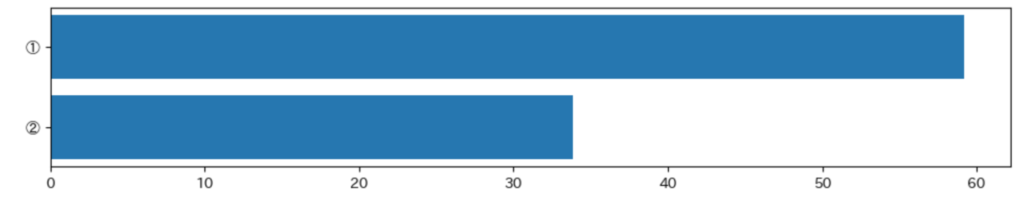
sel = df.query('col_X1 > 0 and col_X2 < 0 and col_X3 > 0 and col_X4 < 0.1 and col_X5 > 1')処理時間は、queryの方が高速でした。
| ① | 59.21204209327698 sec. |
| ② | 33.86676096916199 sec. |
orで行を抽出するサンプルです。
① queryを使わない記述
sel = df[(df['col_X1'] > 0) | (df['col_X2'] < 0)]② queryを使った記述
sel = df.query('col_X1 > 0 or col_X2 < 0')or条件の場合は、ほぼ変わらない結果となりました。queryではandはかなり高速でしたが、orでは挙動が異なりました。
| ① | 80.70227718353271 sec. |
| ② | 83.11294507980347 sec. |

queryは、engineという引数でpythonまたは、numexprのどちらを利用するか設定することができます。なお、engineが指定されていない場合は、numexprが利用可能ならnumexprを利用します。
numexprライブラリをインストールして、処理速度を確認してみます。
!pip install numexprcolab環境にインストールしようとしたら、以下のようなメッセージが表示されました。デフォルトでnumexprはインストールされているようです。

エンジンを切り替えて測定を行ってみました。
① engine=”python”
sel = df.query('col_X1 > 0 and col_X2 < 0 and col_X3 > 0 and col_X4 < 0.1 and col_X5 > 1', engine="python")② engine=”numexpr”
sel = df.query('col_X1 > 0 and col_X2 < 0 and col_X3 > 0 and col_X4 < 0.1 and col_X5 > 1', engine="numexpr")結果は、numexprを使った方が倍くらい高速でした。
| ① | 79.83801794052124 sec. |
| ② | 45.22269654273987 sec. |

Pandasで行抽出に便利はqueryについて、ベンチマークを行ってみました。結果は、numexprがインストールされている場合は、queryを使っても速度的には同等か、より高速という結果が得られました。
queryを使うと、書きやすいし、読みやすいので積極的に使ってもよいかなという印象です。
実は、queryは遅いと思い込んでいました。今回ベンチマークを測ってみて高速なことがわかりました。