



ESPnet2を使った日本語音声認識(Speech To Text)の手順解説
Aru
Aru's テクログ(Aruaru0)

物体検出のアノテーションは、時間と手間のかかる作業です。しかし、工夫すれば作業効率を大幅にアップさせることができます。この記事では、「アノテーション作業を楽にする方法」として、枠を新たにつけるのではなく、自動で付加された枠を修正する半自動アノテーション手法を提案します。
※この記事のやり方は、YOLOv8以外にも応用することができます。
具体的には、以下の手順でアノテーションを行うことで作業量を減らします。
物体検出のアノテーション作業ってかなり面倒です。
私も、labelImgというツールを使ってアノテーションしていますが、画像を一枚一枚確認しながら枠とラベル名をつけていく作業は、枚数が増えるとかなり大変だと感じています。
もっと効率の良いツールがないかといくつかのツールを試してみましたが、どれも似たり寄ったり。結局、軽くてシンプルなlabelImgを使い続けています。
動画の場合、連続したフレームで似たような画像が続くため、前のフレームの結果を参照して作業を楽にすることができます。この機能を持つツールもあるのですが、動画から学習データを作る場合、「連続した画像=似た画像→学習データとしてどうなの?」となり、全てのフレームを学習データとして使うことは少ないかと思います。実際には、フレームを間引いて学習させるので、枠の移動量が大きくなり、この機能はあまり役に立ちません。
とにかく、枠をつける作業は大変です。
「なるべく楽をしたい」ということで考えた方法が今回の記事の内容になります。
ざっくりとした流れです。
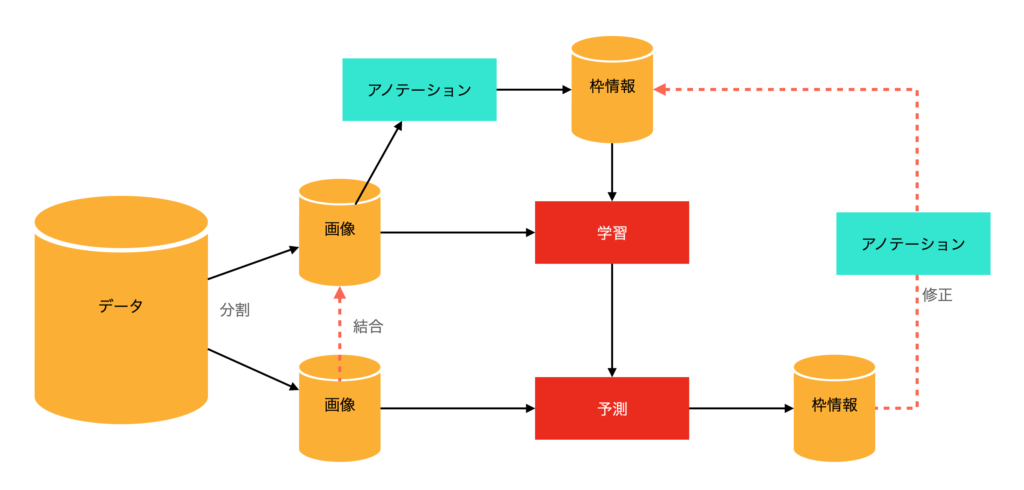
まず、データを学習用とそれ以外に分割します。学習用はまずは少ない枚数です。ここで少ない枚数に対してアノテーション(labelImg)を行ってYOLOv8で学習します。次に学習したモデルで学習に使わなかった画像の物体検出を行い、枠情報を生成します。この予測結果をアノテーションツールで修正することで学習データを新たに作成する、これが手順になります。
数が多い場合は、データを変えて②③④を繰り返すと、精度が上がっていって修正が少なくなっていくので手間を減らすには良いかもしれません。ただ、学習時間がかかります。
上記の方法では、「正しい位置に枠がついた画像については、アノテーションツールでの確認だけで済む」ため作業量はかなり少なくなります。また、少しずれ位置に枠がついていた場合も、新規に枠をつけるよりは作業量は少ないです。結果、作業量が大幅に削減できます。
実際やってみるとわかりますが、かなり楽なのでぜひ試してみてください。

YOLOv8を利用していますが、アノテーションのサポートとして利用しているだけなので、他の検出モデル用のアノテーションにもここで書いたテクニックを使うことは可能です。
その場合は、アノテーション結果をYOLOフォーマットからターゲットのモデルの入力フォーマットに変換する必要があります。
以下、アノテーションデータの作成をYOLOv8と、labelImgを使って行う場合のそれぞれのツールの使い方について説明します。
python環境が入っていれば以下のコマンドを実行するだけでインストールされます。yoloコマンドが入っていればインストール完了です。
pip install ultralyticsインストールされていれば、yoloコマンドを実行すると以下のように出力されます。
> yolo
Arguments received: ['yolo']. Ultralytics 'yolo' commands use the following syntax:
yolo TASK MODE ARGS
Where TASK (optional) is one of ('detect', 'segment', 'classify', 'pose')
MODE (required) is one of ('train', 'val', 'predict', 'export', 'track', 'benchmark')
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
See all ARGS at https://docs.ultralytics.com/usage/cfg or with 'yolo cfg'
1. Train a detection model for 10 epochs with an initial learning_rate of 0.01
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
2. Predict a YouTube video using a pretrained segmentation model at image size 320:
yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
3. Val a pretrained detection model at batch-size 1 and image size 640:
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
4. Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
5. Run special commands:
yolo help
yolo checks
yolo version
yolo settings
yolo copy-cfg
yolo cfg
Docs: https://docs.ultralytics.com
Community: https://community.ultralytics.com
GitHub: https://github.com/ultralytics/ultralytics使い方の詳細は以下のリンクを参照してください
ドキュメント: https://docs.ultralytics.com/
CLIの使い方:https://docs.ultralytics.com/usage/cli/
オプションの説明:https://docs.ultralytics.com/usage/cfg/
学習済みモデルをyolo8n.pt、データセットの定義をdataset.yamlとして準備している場合、以下のコマンドで学習できます。なお、epochsとimgszは適当に変更してください。とりあえず、ここでは公式のページと同じ値で設定しました。
初期の学習モデルは、YOLOv8の公式ページにありますので、そちらをダウンロードしてください。
yolo detect train data=dataset.yaml model=yolov8n.pt epochs=100 imgsz=640GPUで実行されない場合は、device=0などのオプションをつけてください。ちなみに、m1 Macの場合は、device="mps"とするとGPU処理になります。
dataset.yamlは例えば、以下のようになります。パスは、相対パスの場合、datasets以下のフォルダになるようです。パス(path)設定がうまくできない場合は、絶対パスで指定してみてください。
# Path
path: ./cats
train: images/train
val: images/valid
# Classes
nc: 1
names: ['cat']trainはトレーニング画像、valは検証用の画像です。./catsフォルダの構成は以下のようになります。コマンドでは指定していませんが、学習にはlabelsフォルダに画像に対応したアノテーションデータが必要となります(画像データがtest.jpgだとすると、labelsにはYOLOフォーマットのtest.txtが必要となります)。
./cats/images
/train
/valid
/ labels
/train
/valid上記のサンプルのyamlファイルでは、クラス数ncは1、クラス名はcatになります。2クラスでdog, catの場合は、以下のようになります。
nc: 2
names: ['dog', 'cat']実行すると結果がruns/detect/trainxxフォルダに記録されます(xxは、train2, train3のように数字が入ります)。
ここでは、画像データがsampleフォルダにある前提で説明します。推論を行う場合は以下のコマンドを実行します。モデルは、トレーニングした結果のモデルを指定してください。yolov8で学習を行った場合は、./runs/detect/train/weights/best.ptが学習結果のモデルです(何度も実行した場合は、trainxxと番号がついています)。save_txt=Trueを設定することでYOLO形式で結果が保存されます。
結果は、run/detect/predictフォルダにlabelsという形で保存されます。
yolo detect predict model=モデル source='sample' save_txt=True推定をアノテーションに利用する場合は、結果画像は必要ありませんので、save=Falseと指定すれば出力データがテキストだけになり、ディスク容量を節約できます。この場合のコマンドは以下の通りです。
yolo detect predict model=モデル source='sample' save_txt=True save=False画像が./sampleに、推論した出力が./runs/detect/predict/labelsにある場合で説明します。
まず、classes.txtを作る必要があります。labelImg起動時のコマンドラインのオプションで指定できるはずですが、自分の環境ではなぜかうまく動作しません。./runs/detect/predict/labelsフォルダに置くのが確実みたいですので、このフォルダにclasses.txtを作成して配置します。
classes.txtは、クラス名を羅列したファイルになります。nc=1, names=[‘cat’]で学習させたので、クラス名はcatだけになります。この場合、classes.txtは以下のように1行だけになります。
catファイルが準備できたら、以下のコマンドでlabelimgを立ち上げます。
labelImg ./sample ./runs/detect/predict/labels/classes.txt ./runs/detect/predict/labelsこれで、labelImgが立ち上がりますので、結果を見ながら必要な箇所の修正をしていきます。修正の前に、「自動で保存する」をチェックしておくと楽かもしれません。
修正が完了したらlabelImgを終了し、画像とラベルを、学習用のデータとして追加します。
なお、新しくラベル付したデータは、全てtrain加えても、train/validに分割して加えても良いです
何度も繰り返す場合は、修正が必要だったものだけtrainデータに加えるというやり方もありです。修正が必要だったということは、そのデータに対して学習できていないということです。なので、学習に加えればバリエーションの増加が期待できます。一方、修正が必要ないものは既存の学習データで既に習得済みと考えることもできます

学習データセットを変えると、学習結果も変化するので、修正が必要だったやつだけ入れるのが正解かどうかはわからないです。ここはやっぱり試行錯誤かなと思います。
アノテーションの大変さを少しでも減らす方法として、一部だけアノテーションして学習・推論し、推論結果の間違いを修正して再び学習させるという方法について説明しました。
ツールによっては、これをサポートしているものもあるのですが、モデルが固定されていたり、モデルは入れ替えられても手順が面倒だったりします。
ここで紹介したやり方は、自身の作成したモデルの出力を使うので、どんなモデルでも行うことができますし応用性が高いと思います。
大量のアノテーションに疲れている人は、ぜひトライしてみてください。



