Mel Spectrogram|音声データを画像(二次元データ)として深層学習する方法
Aru
Aru's テクログ(Aruaru0)

YOLO v8(YOLO v9)を使って、独自のカスタムデータ(オリジナルデータ)で物体検出(Object detection)の学習と推論を実践してみました。本記事では、データセットをYOLOフォーマットに変換する手順を説明し、変換したデータを使ってYOLOv8およびYOLOv9でモデルの学習と推論を行う方法について解説します。

YOLOv8は、Ultralytics社が開発した物体検出モデルです。YOLOv8では、物体検出タスク以外にも、セグメンテーション、姿勢推定などのタスクも行うことが可能です。
2023年1月にYOLOv8が公開され、翌年の1月(2024年1月)には、YOLOv8.2が公開されました。YOLOモデルの進化は本当に早いと感じています

これまで、YOLOv5を活用していましたが、YOLOv8が新たに登場したので、キャッチアップを兼ねてYOLOv8を使ったカスタムデータに対する学習・推論という一連の流れをPythonでやってみました。
カスタムデータに対する学習の場合、学習するデータセットが必要となりますが、この記事では、kaggleにあるCar Object Detectionデータセットを利用します。
また、サンプル学習・推論コードはデータセットを直接利用できるkaggle Notebookで作成しています。
コードのリンクはここ(YOLOv8)になります。

最初はGoogle Colabでサンプルコードをつくろうかと思いましたが、データセットの転送などの処理が余計にかかるのでkaggle notebookにしました。

注意点としては、Kaggleのアカウント持っていないかたはデータセットはアクセスできないかもしれません。
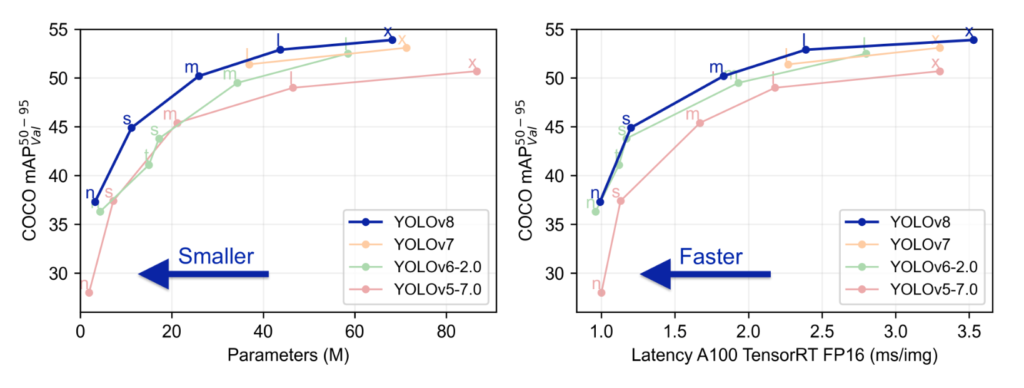
以下は、YOLOv8の性能を示したグラフです。これをみると、以前のモデルと比べて性能は高く、速度も早いといいことづくめです。
前バージョンのYOLOv5とこれだけ差があるというのは正直、驚きです。
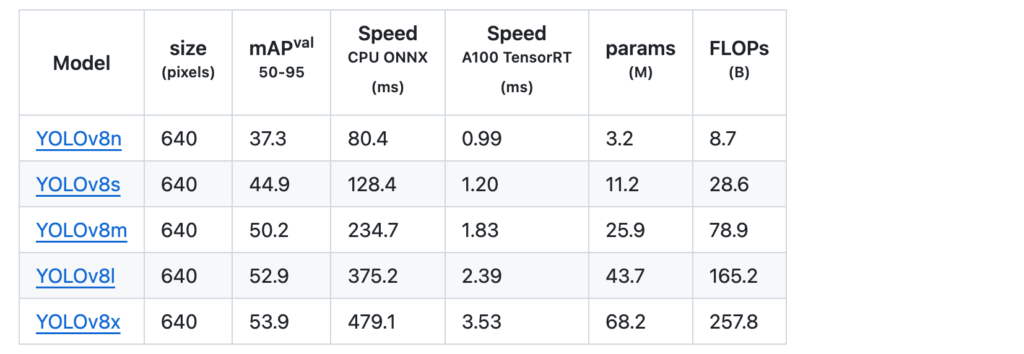
モデルの精度は以下の表の通りです。
2024年1月に公開されたYOLOv8.1では、OBB(Oriented Bounding Box)に対応しました。OBBは回転したバウンディングボックスのことです(縦横水平垂直ではなく、斜め角度の枠などを表現可能です)。OBBに対応したことで、より正確なBounding Boxが必要なシーンにも、YOLOv8つかえるようになり、応用範囲がグッと広がりました。
2024年4月に公開されたYOLOv8.2ではYOLOv8-Worldがサポートされました。YOLO-Worldは、2024年に発表された最新の物体検知モデルであり、ゼロショット(学習せずにあらゆる物体を検知できる)という特徴があります(こちらの使い方も近いうちに調べてみたいと思います。)
独自データに対するアノテーション(枠付け)のやり方については、以下の記事を参考にしてください


Ultralytics社のYOLOモデルでは、YOLOv9もサポートしています。YOLOv8とほぼ同じコードでYOLOv9での学習・推論も可能です(記事中では変更点のみ記載しています)。
以下は、YOLOv9関連のリンクになります。
論文:https://arxiv.org/abs/2402.13616
github: https://github.com/WongKinYiu/yolov9
YOLOv9では新しいアーキテクチャの提案によりこれまで以上の性能を実現しています。興味がある方は論文を参照してくさだい。
私はYOLOv9の論文をまだ読めていません。どこかで読みたいとは思いますが、どちらかというと使い方に興味があったりします。しかし、物体検知もまだまだ性能向上ができるということに驚きです。
YOLOv9cモデルを学習するコードのリンクはこちらです
オリジナルデータとして、kaggleのCar Object Detectionデータセットを利用して学習を行ってみました。このデータは車両にアノテーションしたデータセットになります。
車両検出をYOLO-NASでも行ってみました。YOLO-NASによる物体検出についてはこちらの記事を参考にしてください

YOLOv8のインストールは簡単です。
Kaggle NotebookやGoogle Colabの場合は、Python(3.8以上)とPyTorch(1.8以上)がインストールされているので、以下のコマンドを実行すればインストールは完了します。
Kaggleノートブックの場合は、インターネット接続を許可しておく必要があります。
# install yolov8
!pip install ultralyticsYOLOと、必要なライブラリをインポートします(コード作成にあたり、追加・削除を繰り返しているので、最終的に必要なくなったライブラリも含まれているかもしれません)
from ultralytics import YOLO
import os
import random
import shutil
import numpy as np
import pandas as pd
import cv2
import yaml
import matplotlib.pyplot as plt
import glob
from sklearn.model_selection import train_test_split既に、YOLOフォーマットでアノテーションされたデータがある場合は、yamlファイルの作成から始めることができます。本記事の学習(トレーニング)からスタートしてください。
先に説明した通りこの記事ではkaggleのCar Object Detectionデータセットを利用します。
このデータセットには、テスト用の画像フォルダと、トレーニング用の画像フォルダがあり、またトレーニング画像のアノテーションデータがcsvファイル形式で格納されています
このデータセットはYOLO向けのデータセットではないため、そのままではYOLOv8に入力できません。
このため、フォーマット変換が必要となります
自前のデータセットがYOLOのフォーマットの場合は、この変換はスキップしてください
まず、各種ディレクトリの設定を行います。TRAINは訓練用の画像データ、TESTは評価用の画像データの位置です。
DIR = "/kaggle/working/datasets/cars/"
IMAGES = DIR +"images/"
LABELS = DIR +"labels/"
TRAIN = "/kaggle/input/car-object-detection/data/training_images"
TEST = "/kaggle/input/car-object-detection/data/testing_images"まず、CSVファイルを読み込みます。
df = pd.read_csv("/kaggle/input/car-object-detection/data/train_solution_bounding_boxes (1).csv")
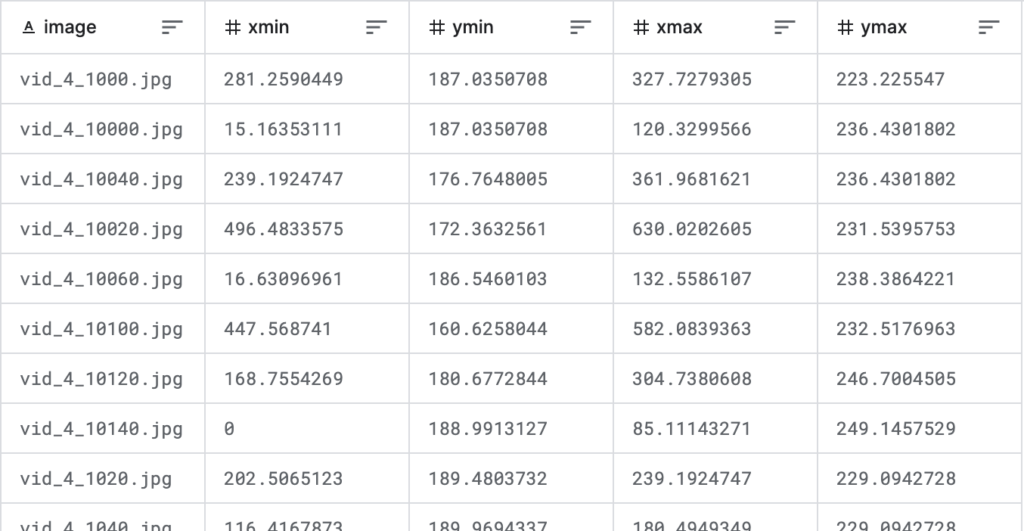
dfこのファイルは、各行はファイル名+枠情報になっていて、1ファイルに複数枠ある場合は、同じファイル名が複数行続く構成になっています(下図)。
まず、訓練と評価用にファイル分割するためにunique()で一意なファイル名を取り出し、train_test_split関数を使って2つに分離します。
訓練:評価の比率は8:2のとしました。
files = list(df.image.unique())
files_train, files_valid = train_test_split(files, test_size = 0.2)上記で、どの行が訓練データになって、どの行が評価データになるかを決めました。
次は、データセット用のフォルダを作成し、そこにファイルを配置していきます。
まず、YOLOv8形式で、ファイルを置くためのフォルダを作成します(exist_ok=Trueとしているので、フォルダが存在していてもエラーになりません)。
# make directories
os.makedirs(IMAGES+"train", exist_ok=True)
os.makedirs(LABELS+"train", exist_ok=True)
os.makedirs(IMAGES+"valid", exist_ok=True)
os.makedirs(LABELS+"valid", exist_ok=True)次に、各画像ファイルを、訓練(train)または評価(valid)のフォルダにコピーしていきます。
各画像ファイルがどちらのフォルダに割り振られるかは、”if fname in ...“の部分で判定しています。
train_filename = set(files_train)
valid_filename = set(files_valid)
for file in glob.glob(TRAIN+"/*"):
fname =os.path.basename(file)
if fname in train_filename:
shutil.copy(file, IMAGES+"train")
elif fname in valid_filename:
shutil.copy(file, IMAGES+"valid")次に、アノテーションデータを格納したテキスト(.txt)ファイルを作成していきます。
アノテーションデータは、CSVデータの情報から生成します。
具体的にはCSVファイルの情報をYOLOv8の情報(クラスID, X中心、Y中心、W、H)のフォーマットに変換し、画像ファイルと同名のテキストファイルに格納していきます。
なお、元のデータは676×380のサイズでの(xmin, ymin)-(xmax, ymax)という座標になっていますが、これを(クラスID, X中心、Y中心、W、H)に変換すると同時に、スケールも0.0〜1.0に変換する必要があります。
YOLOのフォーマットでは、アノテーションデータは以下のフォーマットになります(xy座標と幅は、画像の幅、高さを1とした値(0~1)になります)
クラスID Xの中心 Yの中心 W H
クラスID Xの中心 Yの中心 W H
クラスID Xの中心 Yの中心 W H
: (オブジェクトの数だけ繰り返し)
for _, row in df.iterrows():
image_file = row['image']
class_id = "0"
x = row['xmin']
y = row['ymin']
width = row['xmax'] - row['xmin']
height = row['ymax'] - row['ymin']
x_center = x + (width / 2)
y_center = y + (height / 2)
x_center /= 676
y_center /= 380
width /= 676
height /= 380
if image_file in train_filename:
annotation_file = os.path.join(LABELS) + "train/" + image_file.replace('.jpg', '.txt')
else:
annotation_file = os.path.join(LABELS) + "valid/" + image_file.replace('.jpg', '.txt')
with open(annotation_file, 'a') as ann_file:
ann_file.write(f"{class_id} {x_center} {y_center} {width} {height}\n")下図は、フォーマット変換のイメージ図です。dfの内容を解析し、YOLOフォーマットに変換し、対応するtextファイルに書き出します。open(annotation_file, 'a')と追加モードでファイルをopenしているので、同じ画像に対する枠情報は1つのファイルに追記されることになります。
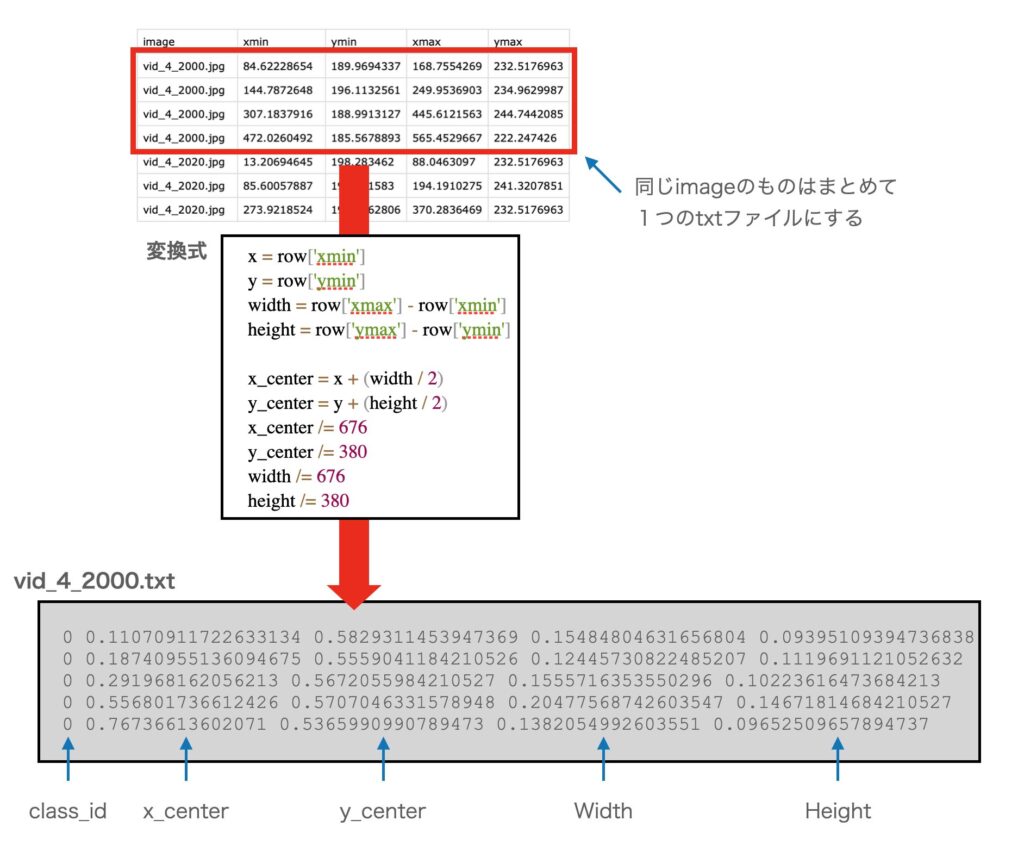
コンバートの内容を図にまとめると以下のようになります

変換後のフォルダ構成は以下のようになり、imagesには画像ファイル(*.jpg)が、labelsには画像に対応するアノテーションデータ(*.txt)が格納される形になります。
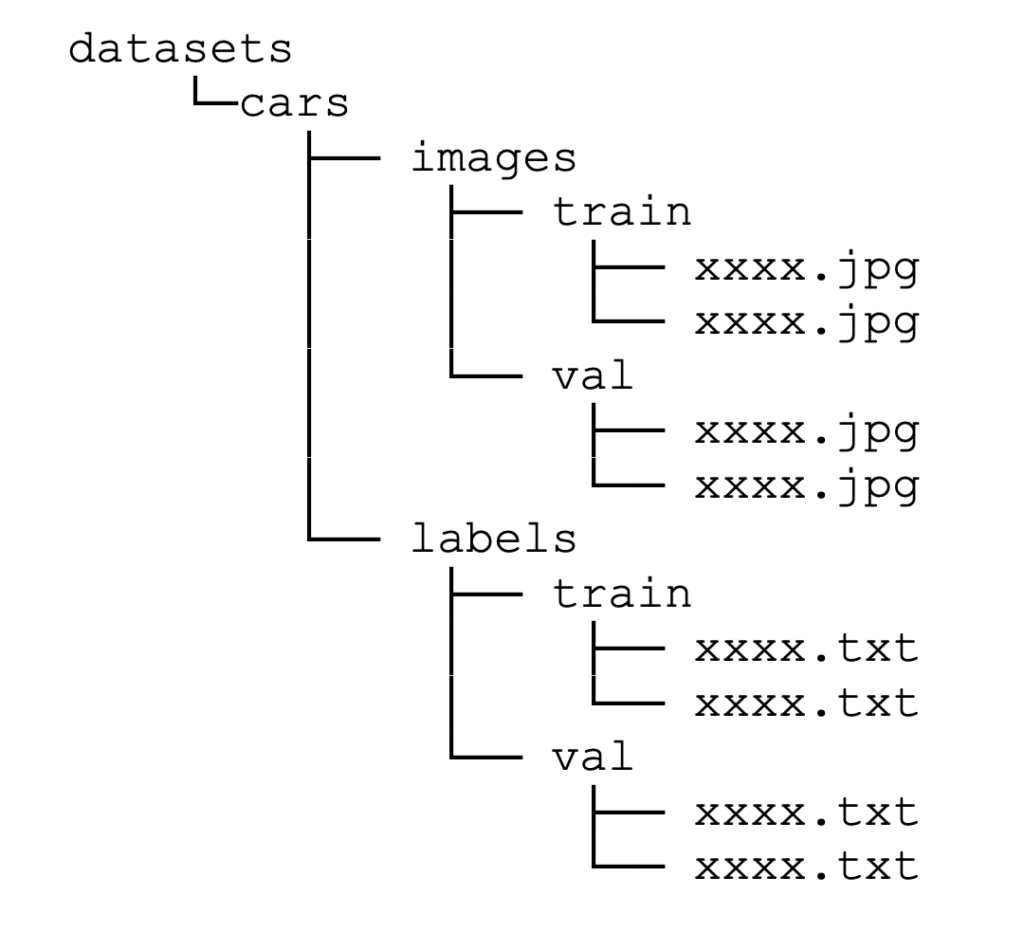
以上で、データセットの準備は完了です。
YOLOで学習させる場合は、このフォーマットに変換する必要があるのでフォーマットの形式は覚えておくと良いと思います。また、有名なデータフォーマットについては、コンバーターなどが用意されていることもありますので、それを使っても良いかと思います。
独自のデータにラベルをつけて学習させたい方は、アノテーションを行う必要があります。アノテーションの方法については以下の記事を参考にしてください。labelimgは機能は少ないけど手軽で、LabelStudioは高機能ですが使い始めるまでの設定が少し複雑です。ちょっとしたアノテーションはlabelimgをおすすめします。

既に、YOLOフォーマットでアノテーションされたデータがある場合は、yamlファイルの作成から始めることができます。labelImgなどを使ってアノテーションした場合は、ここからスタートしてください。
トレーニングのために、yamlファイル(設定ファイル)を作成します。
なお、yamlファイルの設定は、フォルダ構成は以下のような構成になっていることをが前提となります。
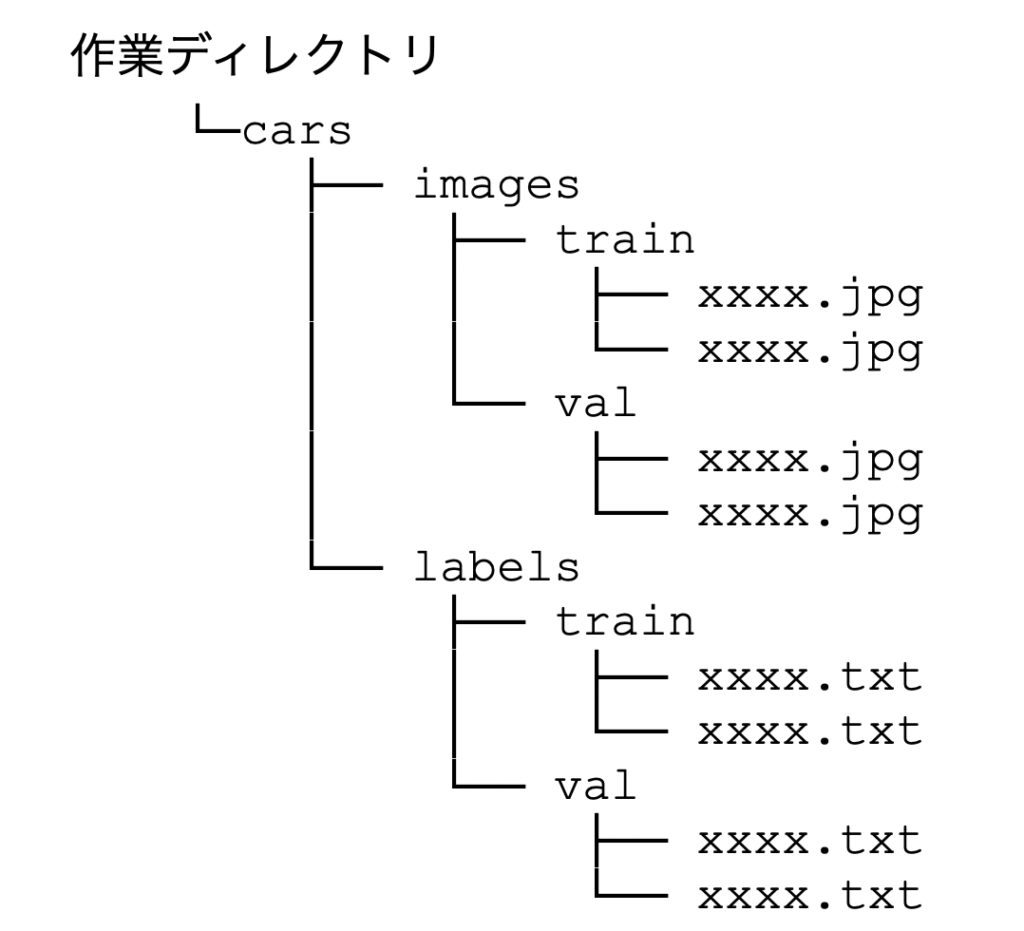
kaggle notebook / jupyter notebookでは以下のように%%writefileで記述することで、セルの内容をyamlファイルとして書き出すことが可能です。
%%writefile dataset.yaml
# Path
path: ./cars
train: images/train
val: images/valid
# Classes
nc: 1
names: ['car']学習中にwandbへアクセスしようとするので、以下のコードでwandbを停止させています。アカウントを持っている場合は、接続して、実験記録を保存させることで学習の記録ができます
# disable wandb
import wandb
wandb.init(mode="disabled")yamlファイルとデータセットが準備できたので、いよいよ訓練の実行です。
以下のコードを実行して、あとは、訓練が終了するまで待ちます。
model = YOLO('yolov8n.pt')
model.train(data="dataset.yaml", epochs=100, batch=8)今回は、データセットを、yoloフォーマットにコンバートしたりしたので説明が長くなっていますが、yolov8の学習コードは、実質2行だけです。データがもともとyoloフォーマットであれば、yamlファイルを作成して、以下の2行を実行するだけでOKです。
YOLOv8では、以下のモデルが用意されています。今回は、一番小さいyolov8nモデルを選びました。
モデルサイズはn→s→m→l→xの順番で大きくなり、サイズが大きくなるほど処理時間が大きくなります。公式のデータでは、YOLOv8nは、A100 TensorRT使用で0.99msとかなり高速です。この通りなら、1秒(1000ms)に1000枚以上処理できることになります。また、CPUでも80.4msと秒15枚程度処理できることになります。
この部分を変更するだけでYOLOv9モデルを使うことができます。具体的には、下記のようにモデル名を書き換えるだけです。
model = YOLO('yolov9c.pt')
model.train(data="dataset.yaml", epochs=100, batch=8)YOLOv9モデルとしては下記のようになっています。現在のところ、利用できるのはyolov9c.ptと yolov9e.ptの2つです。軽めのYOLOv9sなども使ってみたいところです。
| モデル | サイズ (ピクセル) | mAPval 50-95 | mAPval 50 | params (M) | FLOPs (B) |
|---|---|---|---|---|---|
| YOLOv9t | 640 | 38.3 | 53.1 | 2.0 | 7.7 |
| YOLOv9s | 640 | 46.8 | 63.4 | 7.2 | 26.7 |
| YOLOv9m | 640 | 51.4 | 68.1 | 20.1 | 76.8 |
| YOLOv9c | 640 | 53.0 | 70.2 | 25.5 | 102.8 |
| YOLOv9e | 640 | 55.6 | 72.8 | 58.1 | 192.5 |
train)の引数についてtrainに指定できる引数は多数あります。
ざっと、引数一覧を眺めてみましたが、引数だけでかなりのチューニングが可能です。
例えば、スケジューラを切り替えたり、ラベルスムージングのON/OFFができたりと、ハイパーパラメータの細かな調整が可能です。
以下が引数の一覧になります
| 引数 | 例 | 説明 |
|---|---|---|
model | None | モデル名またはモデルファイルへのパス, i.e. yolov8n.pt, yolov8n.yaml |
data | None | データファイルへのパス(xxxx.yamlファイル) |
epochs | 100 | EPOCH数 |
patience | 50 | 性能改善しないときに、早期打ち切りするまでのEPOCH数( Early Stopping) |
batch | 16 | バッチサイズ(-1で自動) |
imgsz | 640 | 入力の画像サイズ(整数 または w, h) |
save | True | 訓練中の予測結果とチェックポイントを保存 |
save_period | -1 | チェックポイントの間隔(EPOCH数、-1の場合は無効) |
cache | False | キャッシュあり・なし |
device | None | デバイス GPUの場合、device=cudaの場合は0,1,2,3。マルチCPUの場合は[0,1]など CPUの場合、device=’cpu’。 M1/M2Macの場合、device=’mps’が利用可能 |
workers | 8 | ワーカースレッドの数 |
project | None | プロジェクト名 |
name | None | 実験名 |
exist_ok | False | 同じ実験がある場合、記録を上書きするかどうか |
pretrained | False | トレーニング済みモデルを利用するかどうか |
optimizer | 'auto' | オプティマイザ SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto |
verbose | False | 詳細出力をするかどうか |
seed | 0 | 乱数のシード |
deterministic | True | deterministicモードを有効にするかどうか。再現性に影響 |
single_cls | False | マルチクラスデータをシングルクラスとして訓練するかどうか |
rect | False | rectangular training with each batch collated for minimum padding |
cos_lr | False | コサインスケジューラを使用するかどうか |
close_mosaic | 0 | (int) 最終EPOCHではモザイクオーグメンテーションを無効にする |
resume | False | 訓練を最後のチェックポイントから再開する |
amp | True | Automatic Mixed Precision (AMP) を使うかどうか |
fraction | 1.0 | 訓練に使うデータセットの割合 (デフォルトは全部(1.0)) |
profile | False | profile ONNX and TensorRT speeds during training for loggers |
lr0 | 0.01 | 初期の学習率 |
lrf | 0.01 | 最後の学習率 |
momentum | 0.937 | SGD momentum/Adam beta1 |
weight_decay | 0.0005 | optimizer weight decay 5e-4 |
warmup_epochs | 3.0 | ウォームアップEPOCH数 |
warmup_momentum | 0.8 | ウォームアップ時の初期momentum |
warmup_bias_lr | 0.1 | ウォームアップ時の初期lr |
box | 7.5 | box lossのgain |
cls | 0.5 | cls(クラス) lossのgain (scale with pixels) |
dfl | 1.5 | dfl lossの gain |
pose | 12.0 | pose loss のgain (pose-only) |
kobj | 2.0 | keypoint obj lossの gain (pose-only) |
label_smoothing | 0.0 | ラベルスムージング |
nbs | 64 | nominal batch size |
overlap_mask | True | masks should overlap during training (segment train only) |
mask_ratio | 4 | mask downsample ratio (segment train only) |
dropout | 0.0 | ドロップアウト率 (classify train only) |
val | True | 訓練中に検証を行うかどうかのフラグ |
一部の説明は日本語にするのが難しかったので英語のままです
わからないパラメータは、りあえずはデフォルトのままでと良いと思います。
YOLOv5と同様に、結果のグラフが画像として格納されています。
格納されている場所は、./runs/detect/train/results.pngです。以下のコードで、これを表示しています。
from IPython.display import Image
Image("/kaggle/working/runs/detect/train/results.png")これをみると、lossが順調に減っていて学習が進んでいることが分かります。metrics/mAP50-95のグラフ(右下)をみるとEPOCH数を増やせばまだ学習が進みそうですが、その左横のmAP50のグラフをみると、10回を超えたあたりで既に学習できている雰囲気もあります。
とりあえず、EPOCH100回で学習ができてそうなことが確認できました。
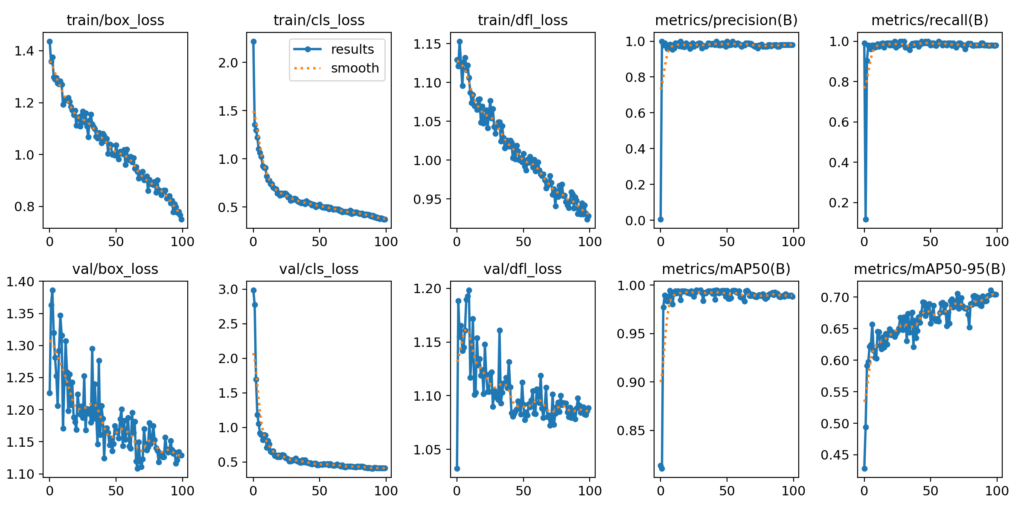
事前学習のデータに車が含まれているので、すでにある程度学習していたようです。
推論コードも非常にシンプルです。
まず、学習結果を読み込んだモデル(model)を作り、引数に画像ファイルを指定して呼び出しすだけでOKです。
以下がコードになります。このコードでは画像ファイルは、学習に利用していないtesting_imagesフォルダを指定しました。また、save=Trueにして結果画像をファイルとして保存するように設定しています。
また、conf=0.2, iou=0.5で検出の閾値を設定しています(confはクラスの確らしさ、iouは枠の確らしさです)。
model = YOLO('./runs/detect/train/weights/last.pt')
ret = model("/kaggle/input/car-object-detection/data/testing_images",save=True, conf=0.2, iou=0.5)結果画像は、./runs/detect/predict/に格納されています。これをみると、正しく予測ができてそうです。

YOLOv8の結果の可視化は、supervisonを利用すると便利です。詳細は以下の記事を参考にしてください。

推論側もかなりのパラメータを指定可能です。
オプションのうち、意味がよく理解できないものは解釈ミスを防ぐために英語のままにしています。
| 引数 | 例 | 説明 |
|---|---|---|
source | 'ultralytics/assets' | ソース画像/映像データのディレクトリ |
conf | 0.25 | 検出するオブジェクトの閾値 |
iou | 0.7 | NMSの交差判定のIoUの閾値 |
half | False | FP16を利用するかどうかのフラグ |
device | None | 実行するデバイス。GPU(cuda) = 0/1/2/3または”cpu” |
show | False | 結果を表示(可能な場合) |
save | False | 結果画像を保存するかどうか |
save_txt | False | 結果をテキストファイルで保存するかどうか |
save_conf | False | 結果に信頼度スコアを含めて保存するかどうか |
save_crop | False | 結果に切り取った画像を含めて保存するかどうか |
hide_labels | False | ラベルを隠す(非表示にする) |
hide_conf | False | 信頼度スコアを隠す(非表示にする) |
max_det | 300 | 最大検出数 |
vid_stride | False | video frame-rate stride |
line_width | None | バウンディングボックスのライン幅。Noneの場合は画像サイズに合わせて自動調整 |
visualize | False | モデルの特徴を可視化するかどうか |
augment | False | データ拡張を予測で利用するかどうか |
agnostic_nms | False | class-agnostic NMS |
retina_masks | False | 高解像度のセグメンテーションマスクを利用するかどうか |
classes | None | filter results by class, i.e. class=0, or class=[0,2,3] |
boxes | True | セグメンテーションに枠を表示するかどうか |
ソース(source)として設定できるのは以下になります。これをみるとYoutubeやrtspから直接入力することができるようです。
| ソース名 | 例 | データ型 | コメント |
|---|---|---|---|
| image | 'image.jpg' | str or Path | 単一の画像ファイル |
| URL | 'https://ultralytics.com/images/bus.jpg' | str | 画像のURL |
| screenshot | 'screen' | str | スクリーンショットのキャプチャ |
| PIL | Image.open('im.jpg') | PIL.Image | RGB画像(Height、Width, Channel)フォーマット |
| OpenCV | cv2.imread('im.jpg') | np.ndarray of uint8 (0-255) | BGR画像(Height、Width, Channel)フォーマット |
| numpy | np.zeros((640,1280,3)) | np.ndarray of uint8 (0-255) | BGR画像(Height、Width, Channel)フォーマット |
| torch | torch.zeros(16,3,320,640) | torch.Tensor of float32 (0.0-1.0) | RGB画像(Batch, Channel, Height, Width)フォーマット |
| CSV | 'sources.csv' | str or Path | 画像、ビデオ、またはディレクトリへのパスを含むCSVファイル |
| video | 'video.mp4' | str or Path | MP4、AVIなどのビデオファイル |
| directory | 'path/' | str or Path | 画像または動画を含むディレクトリへのパス |
| glob | 'path/*.jpg' | str | ワイルドカードなどを含んだ画像ファイル名 (*.jpgなど) |
| YouTube | 'https://youtu.be/Zgi9g1ksQHc' | str | YoutubeのURL |
| stream | 'rtsp://example.com/media.mp4' | str | RTSP, RTMPのURLやIPアドレス(WebカメラなどのRTSPアドレス) |
とりあえず、YOLOv8を駆け足で使ってみました。個人的にはYOLOv5より洗練された気がします。学習に設定できるパラメータも全部確認できていませんが、かなり細かく設定できるみたいです。
当分は、これを使いそうです。PythonからはYOLOという名前で呼ぶ感じになっているので、今後はこのインターフェースで統一されるんですかね?
なお、YOLOv8では物体追跡(Tracking)、セグメンテーション(Segmentation)可能です。また、YOLOv8.2からゼロショットでの物体検出も可能になりました。これらについては以下の記事を参考にしてください。