
データの不均衡をオーバーサンプリングで解消するSMOTEの解説と実装例
Aru
Aru's テクログ(Aruaru0)
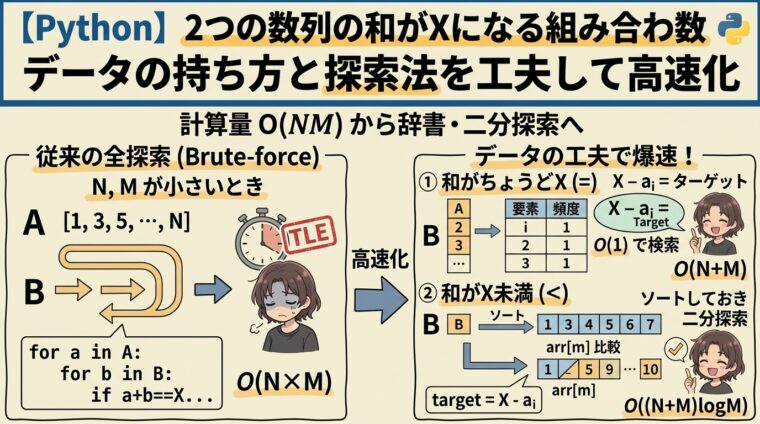
競技プログラミング(AtCoderなど)で頻出する、計算量を意識したアルゴリズムの基礎を解説します。今回は、2つの数列から1つずつ値を選び、その和が特定の条件を満たす組み合わせの数を求める問題を題材にします。
他の記事では変数を変形して計算量を落とす方法を紹介しましたが、今回は「データ構造(辞書)」や「二分探索」を使って探索自体を高速化する典型的なテクニックを段階的に見ていきます。
今回の問題は、長さ $N$ の数列 $A$ と長さ $M$ の数列 $B$ が与えられたときに、$A$ の要素 $a_i$ と $B$の要素 $b_j$ の和が特定の数 $X$ になるような組み合わせの数を求めるというものです。
長さ $N$ の数列 $A = (a_1, a_2, …, a_N)$ と、長さ $M$ の数列 $B = (b_1, b_2, …, b_M)$ があります。 $1 \le a_i, b_j \le 10^9$ の範囲の値が与えられるとき、$a_i + b_j = X$ を満たす整数の組 $(i, j)$ がいくつあるかを求めてください。
前回の問題と同様に、与えられる $N, M$ の大きさ(制約)によって、適切な解法を選択する必要があります。
まずは一番わかりやすい素直な解法です。 $N$ と $M$ が小さい場合(例えば $N, M \le 1000$ 程度)であれば、2重ループですべての組み合わせを探索する愚直な実装で問題ありません。
まずは愚直解を書いてみることは非常に重要です。テストケースの検証や、複雑なアルゴリズムを実装した際のバグ探し(検算)の強力な味方になります。
# O(N * M) の解法(愚直解)
count = 0
for a in A:
for b in B:
if a + b == X:
count += 1
直感的に理解しやすいコードですが、計算量は $O(N \times M)$ となります。
$N$ と $M$ が大きくなると2重ループでは処理時間が長くなります。
例えば $N, M = 10^5$ の場合、ループ回数は $10^{10}$ 回となり、実行時間制限(TLE)に引っかかってしまいます。
そこで、$a_i + b_j = X$ という式を以下のように変形してみます。
$$b_j = X – a_i$$
これはつまり、「$A$ の要素 $a_i$ を一つ固定したとき、数列 $B$ の中に $X – a_i$ という値がいくつあるか?」を探せば良いということです。
数列 $B$ を毎回ループで探すと時間がかかるため、あらかじめ $B$ の各要素の出現回数を「辞書(dict)」に記録しておきます。Pythonの辞書は、キーを指定して値を取り出す操作を平均 $O(1)$ で行えます。
# O(N + M) の解法
from collections import defaultdict
# Bの要素の出現回数を記録する辞書を作成
b_counts = defaultdict(int)
for b in B:
b_counts[b] += 1
count = 0
for a in A:
target = X - a
# 辞書を使って target が B にいくつ含まれているかを O(1) で取得
count += b_counts[target]
これにより、数列 $B$ の要素をカウントするのに $O(M)$、数列 $A$ をループして調べるのに $O(N)$ しかかからず、全体の計算量を $O(N + M)$ まで劇的に削減できます。 $N, M = 10^5$ の場合でもループは数十万回で済むため、余裕で実行時間制限に間に合います。
ここまでは「合計がぴったり $X$ になる場合」を考えてきました。
もし問題が「$a_i + b_j < X$ となる組み合わせはいくつあるか?」 だった場合はどうでしょうか。
先ほどの「辞書」を使った方法は「完全一致(=)」を探すのには非常に強力ですが、「特定の範囲(<)」を探すのには向いていません。
このような場合は、「二分探索」 を用います。手順は以下のようになります。

Pythonには bisect という便利な標準ライブラリがありますが、今回はアルゴリズムの理解を深めるために、あえて二分探索を自作してみます。
# O(M log M + N log M) の解法(二分探索)
# 二分探索を行うための関数
# ソート済みの配列 arr において、target 未満の要素がいくつあるかを返す
def lower_bound(arr, target):
l, r = -1, len(arr)
# l+1=r になったら終了
while l+1 != r :
# 中央の要素
m = (l+r)//2
# 中央の要素がtarget以上なら、中央の要素をrに設定
if arr[m] >= target :
r = m
# 中央の要素がtarget未満なら、中央の要素をlに設定
else :
l = m
# l+1=r が targetより小さい個数になる
return r
# 1. Bをあらかじめソートする (O(M log M))
sorted_B = sorted(B)
count = 0
# 2. Aの各要素について、条件を満たすBの要素数を二分探索で探す
for a in A:
target = X - a
# target より小さい B の要素数を足す (O(log M))
count += lower_bound(sorted_B, target)数列 $B$ のソートに $O(M \log M)$、数列 $A$ の各要素に対する二分探索に $O(N \log M)$ かかるため、全体の計算量は $O((N+M) \log M)$ となります。 辞書を使った解法($O(N+M)$)より少しだけ時間はかかりますが、$N, M = 10^5$ 程度であれば十分高速に動作し、大小比較(不等号)の条件に柔軟に対応できるのが最大の強みです。
今回は2つの数列の組み合わせを題材に、条件や制約に合わせてアルゴリズムを選択するプロセスを紹介しました。
計算量を減らすアプローチは「数学的に計算式で解く」「適切なデータ構造を使う」「探索アルゴリズムを変える」など様々です。問題の条件(=なのか<なのか)によって、辞書と二分探索を適切に使い分けます。




