
Object Detection with YOLOv8: Training and Inference on Custom Data
Aru
Aru's テクログ(Aruaru0)

Are you curious about the capabilities of using M1/M2/M3 Macs for deep learning?
In this article, we benchmark the YOLOv8 on MacBook models equipped with M1 Pro and M2 to explore their performance in the realm of deep learning.
During the evaluation of YOLOv8, I noticed that YOLOv8 inherently supports Apple’s M1/M2 chips. With PyTorch having long adapted to Apple Silicon, I’ve been conducting various benchmarks. However, until now, I hadn’t explored benchmarking for object detection models.
So, I conducted benchmarks to assess its performance during object detection training using YOLOv8.
First, let’s set up a Python environment using Miniconda. If you are installing Miniconda on Apple Silicon via the command line, execute the following command:
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh
sh Miniconda3-latest-MacOSX-arm64.shI referred to the following page for this method.
After installation, restart the terminal or execute “source ~/.zshrc” to ensure that the conda command can be executed.
Once you confirm that the conda command can be executed, create a virtual environment for YOLOv8.

By creating a virtual environment, you can avoid cluttering the Python environment with YOLOv8 installation. Additionally, it provides an easy way to clean up by allowing simple removal of the virtual environment.
Execute the following commands to create a virtual environment named ‘yolov8’, switch to the created virtual environment ‘yolov8’, and install YOLOv8 in the switched environment:
conda create -n yolov8 python=3.11 ⏎
conda activate yolov8 ⏎
pip install ultralytics ⏎Run the following command to start Python from the command line and confirm if the GPU is available.
If torch.backends.mps.is_available() returns True, the GPU is recognized.
> python
Python 3.11.4 (main, Jul 5 2023, 08:40:20) [Clang 14.0.6 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.backends.mps.is_available()
True
>>>The environment used for the experiment this time is a MacBook Air M2 2022 with 16GB of memory. It is a compact-sized laptop that is easy to carry, and if it can handle machine learning tasks effectively, it would offer significant advantages.
MacBook Air M2 2022スペック
Additionally, I tried running it on a MacBook Pro M1 16-inch 2021 with 16GB of memory.
MacBook Pro M1 16インチ 2021スペック

The execution log for M1 Pro has been added at the end.
The data was prepared using the Car Object Detection dataset available on Kaggle. Since the dataset is not formatted for YOLOv8, it needs to be converted.
Please refer to the this article for the conversion code.
Regarding the dataset, you can download the output of the following Kaggle notebook and copy the “datasets” folder to the root of your working directory.
https://www.kaggle.com/code/aruaru0/yolov8-car-object-detection/output
Create the YOLOv8 data file named dataset.yaml. The contents of the file should include the path to the data, the number of classes, and the class names. Once created, place it in the root of your working directory.
# Path
path: ./cars
train: images/train
val: images/valid
# Classes
nc: 1
names: ['car']First, run YOLOv8 on CPU. For now, set the number of epochs to 10 and the batch size to 8.
The argument with device="cpu" represents the parameter for CPU configuration.
from ultralytics import YOLO
import time
if __name__ == "__main__":
model = YOLO('yolov8n.pt')
start = time.time()
model.train(data="dataset.yaml", epochs=10, batch=8, pretrained=True, device="cpu")
end = time.time()
print(f"{end-start}sec.")Here is a partial excerpt from the execution log. The processing time is around 60 seconds per epoch, and it took approximately 630 seconds for the entire 10 epochs. Even with the smallest YOLOv8 model, it seems feasible to train on CPU for this number of images.
<span class="jinr-d--font-size d--fontsize-11px">Transferred 319/355 items from pretrained weights
train: Scanning /Users/tadanori/tmp/m1test/datasets/cars/labels/train.cache... 284 images, 0 backgrounds, 0 corrupt: 100%|██████████| 284/284 [00:00<?, ?it/s]
val: Scanning /Users/tadanori/tmp/m1test/datasets/cars/labels/valid.cache... 71 images, 0 backgrounds, 0 corrupt: 100%|██████████| 71/71 [00:00<?, ?it/s]
Plotting labels to runs/detect/train53/labels.jpg...
optimizer: AdamW(lr=0.002, momentum=0.9) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs/detect/train53
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 0G 1.415 2.612 1.143 5 640: 100%|██████████| 36/36 [00:47<00:00, 1.33s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:06<00:00, 1.35s/it]
all 71 100 0.0046 0.98 0.0113 0.00679
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/10 0G 1.348 1.832 1.171 6 640: 100%|██████████| 36/36 [00:47<00:00, 1.31s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:06<00:00, 1.35s/it]
all 71 100 1 0.125 0.927 0.581
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/10 0G 1.377 1.75 1.163 8 640: 100%|██████████| 36/36 [00:46<00:00, 1.30s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:06<00:00, 1.34s/it]
all 71 100 0.958 0.916 0.982 0.614
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/10 0G 1.299 1.453 1.155 8 640: 100%|██████████| 36/36 [00:47<00:00, 1.33s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:07<00:00, 1.52s/it]
all 71 100 0.99 0.945 0.987 0.639
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/10 0G 1.304 1.371 1.15 8 640: 100%|██████████| 36/36 [00:57<00:00, 1.58s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.67s/it]
all 71 100 0.97 0.95 0.987 0.6
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/10 0G 1.268 1.321 1.15 4 640: 100%|██████████| 36/36 [00:55<00:00, 1.55s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.61s/it]
all 71 100 0.988 0.96 0.972 0.624
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/10 0G 1.234 1.197 1.099 8 640: 100%|██████████| 36/36 [00:56<00:00, 1.56s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.66s/it]
all 71 100 0.99 0.96 0.986 0.604
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/10 0G 1.236 1.128 1.119 4 640: 100%|██████████| 36/36 [00:57<00:00, 1.60s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.67s/it]
all 71 100 1 0.962 0.992 0.638
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/10 0G 1.195 1.025 1.106 4 640: 100%|██████████| 36/36 [00:58<00:00, 1.63s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.74s/it]
all 71 100 1 0.958 0.986 0.645
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 0G 1.171 0.9713 1.087 8 640: 100%|██████████| 36/36 [01:00<00:00, 1.68s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.80s/it]
all 71 100 1 0.96 0.989 0.658
10 epochs completed in 0.172 hours.
Optimizer stripped from runs/detect/train53/weights/last.pt, 6.2MB
Optimizer stripped from runs/detect/train53/weights/best.pt, 6.2MB
Validating runs/detect/train53/weights/best.pt...
Ultralytics YOLOv8.0.138 🚀 Python-3.11.4 torch-2.0.1 CPU (Apple M2)
Model summary (fused): 168 layers, 3005843 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.62s/it]
all 71 100 1 0.96 0.989 0.658
Speed: 0.3ms preprocess, 103.2ms inference, 0.0ms loss, 1.4ms postprocess per image
Results saved to runs/detect/train53
630.5438086986542sec.To train on GPU, simply change the ‘device‘ in the code to ‘mps‘.
from ultralytics import YOLO
import time
if __name__ == "__main__":
model = YOLO('yolov8n.pt')
start = time.time()
model.train(data="dataset.yaml", epochs=10, batch=8, pretrained=True, device="mps")
end = time.time()
print(f"{end-start}sec.")The execution on GPU took approximately 30 seconds per epoch and a total of 330 seconds. This is roughly half the processing time compared to CPU, confirming the effectiveness of GPU acceleration.
Transferred 319/355 items from pretrained weights
train: Scanning /Users/tadanori/tmp/m1test/datasets/cars/labels/train.cache... 284 images, 0 backgrounds, 0 corrupt: 100%|██████████| 284/284 [00:00<?, ?it/s]
val: Scanning /Users/tadanori/tmp/m1test/datasets/cars/labels/valid.cache... 71 images, 0 backgrounds, 0 corrupt: 100%|██████████| 71/71 [00:00<?, ?it/s]
Plotting labels to runs/detect/train54/labels.jpg...
optimizer: AdamW(lr=0.002, momentum=0.9) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs/detect/train54
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 0G 1.375 2.962 1.052 6 640: 100%|██████████| 36/36 [00:28<00:00, 1.27it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:06<00:00, 1.36s/it]
all 71 100 0.0046 0.98 0.841 0.404
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/10 0G 1.262 2.398 1.034 7 640: 100%|██████████| 36/36 [00:25<00:00, 1.39it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 2.16it/s]
all 71 100 0.826 0.714 0.857 0.408
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/10 0G 1.317 2.273 1.059 3 640: 100%|██████████| 36/36 [00:24<00:00, 1.46it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 1.89it/s]
all 71 100 0.89 0.888 0.923 0.484
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/10 0G 1.261 2.128 1.022 4 640: 100%|██████████| 36/36 [00:28<00:00, 1.28it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 2.06it/s]
all 71 100 0.905 0.86 0.931 0.431
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/10 0G 1.278 2.011 1.022 7 640: 100%|██████████| 36/36 [00:28<00:00, 1.26it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 2.22it/s]
all 71 100 0.818 0.88 0.887 0.461
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/10 0G 1.24 1.933 1.009 3 640: 100%|██████████| 36/36 [00:27<00:00, 1.31it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 2.05it/s]
all 71 100 0.843 0.9 0.912 0.466
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/10 0G 1.268 1.835 1.009 7 640: 100%|██████████| 36/36 [00:29<00:00, 1.24it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 2.00it/s]
all 71 100 0.94 0.96 0.971 0.587
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/10 0G 1.207 1.751 0.9709 6 640: 100%|██████████| 36/36 [00:28<00:00, 1.26it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 2.07it/s]
all 71 100 0.952 0.94 0.978 0.558
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/10 0G 1.143 1.718 0.9495 8 640: 100%|██████████| 36/36 [00:26<00:00, 1.37it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 2.07it/s]
all 71 100 0.96 0.951 0.98 0.577
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 0G 1.149 1.607 0.9572 5 640: 100%|██████████| 36/36 [00:27<00:00, 1.32it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:04<00:00, 1.08it/s]
all 71 100 0.97 0.957 0.983 0.608
10 epochs completed in 0.089 hours.
Optimizer stripped from runs/detect/train54/weights/last.pt, 6.2MB
Optimizer stripped from runs/detect/train54/weights/best.pt, 6.2MB
Validating runs/detect/train54/weights/best.pt...
Ultralytics YOLOv8.0.138 🚀 Python-3.11.4 torch-2.0.1 MPS (Apple M2)
Model summary (fused): 168 layers, 3005843 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 1.70it/s]
all 71 100 0.97 0.957 0.983 0.605
Speed: 0.5ms preprocess, 19.7ms inference, 0.0ms loss, 1.9ms postprocess per image
Results saved to runs/detect/train54
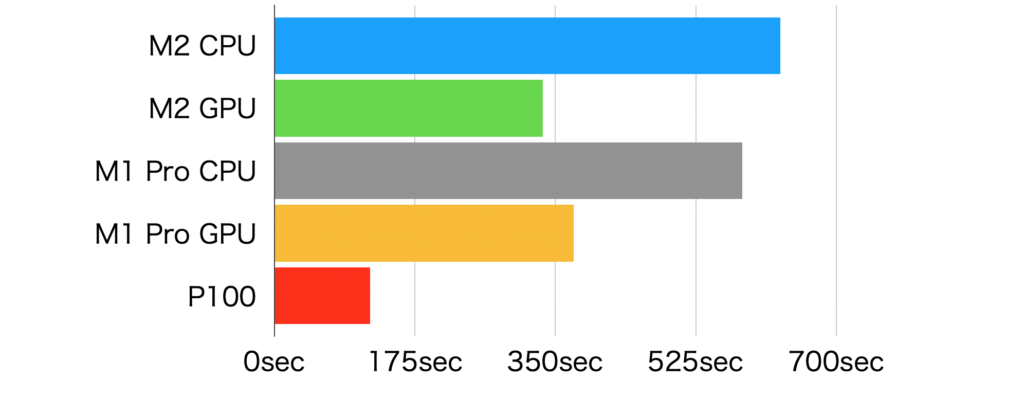
334.40202498435974sec.</span>Conducted benchmarking during training with YOLOv8 optimized for Apple Silicon. It appears that utilizing the GPU on the MacBook Air can result in approximately twice the speed. While the M2 CPU is relatively fast even compared to Intel CPUs, the advantage of achieving twice the speed in training on a laptop could be noteworthy.
Surprisingly, the GPU processing time for M1 Pro was slower than M2. Considering that M1 Pro has twice the number of GPU cores, one might expect it to be faster. However, the results showed that M2 had a shorter processing time.
On the other hand, regarding CPU execution, M1 Pro was faster than M2. This could be attributed to the difference in the number of CPU cores.
It’s possible that training a larger model of YOLOv8 could yield different results, and the improved performance on GPU with M2 might become more pronounced.
I also measured the results of training on a P100 (an Nvidia GPU provided on Kaggle).
Even though it’s a slightly older GPU, it’s significantly faster, being approximately 6 times faster than the CPU and around 3 times faster than the GPU on the M2.
The straightforward impression is that it doesn’t quite match the training speed achieved with the Nvidia GPU.
| DEVICE | Processing time(sec.) | |
| M2 | device=”cpu” | 630.54 sec. |
| device=”mps” | 334.40 sec. | |
| M1Pro | device=”cpu” | 582.68 sec. |
| device=”mps” | 372.99 sec. | |
| 参考:GPU=P100(kaggle notebook) | 119 sec. | |
Using M2 Ultra with 76 GPU cores might catch up to the P100, but considering the cost, it might be more straightforward to invest in an Nvidia GPU.
Nevertheless, the convenience of easily conducting training on an entry-level laptop is significant. It can be quite useful for running small pieces of code, engaging in deep learning studies, and other similar tasks.
The newly released Mac with M3 seems to have significantly improved GPU performance. However, based on the benchmarks so far, it appears that it may not match up to Nvidia GPUs. If you’re serious about deep learning, purchasing a PC with an Nvidia GPU might be a better choice.
Certainly, for small-scale training, it seems to have reached a level where it’s feasible. If you already own a Mac and want to do some deep learning training, utilizing it can be a good option.
Here is the execution log for M1 Pro.
Transferred 319/355 items from pretrained weights
Freezing layer 'model.22.dfl.conv.weight'
train: Scanning /Users/tadanori/tmp/yolov8/datasets/cars/labels/train.cache... 284 images, 0 backgrounds, 0 corrupt: 100%|██████████| 284/284 [00:00<?, ?it/s]
val: Scanning /Users/tadanori/tmp/yolov8/datasets/cars/labels/valid.cache... 71 images, 0 backgrounds, 0 corrupt: 100%|██████████| 71/71 [00:00<?, ?it/s]
Plotting labels to runs/detect/train4/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.002, momentum=0.9) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs/detect/train4
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 0G 1.414 2.611 1.143 5 640: 100%|██████████| 36/36 [00:49<00:00, 1.36s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.66s/it]
all 71 100 0.0046 0.98 0.0113 0.00683
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/10 0G 1.347 1.816 1.173 6 640: 100%|██████████| 36/36 [00:48<00:00, 1.35s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.63s/it]
all 71 100 1 0.284 0.956 0.586
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/10 0G 1.375 1.765 1.164 8 640: 100%|██████████| 36/36 [00:49<00:00, 1.38s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.69s/it]
all 71 100 0.968 0.92 0.983 0.622
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/10 0G 1.317 1.602 1.147 8 640: 100%|██████████| 36/36 [00:48<00:00, 1.35s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.65s/it]
all 71 100 0.968 0.94 0.97 0.598
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/10 0G 1.321 1.419 1.145 8 640: 100%|██████████| 36/36 [00:48<00:00, 1.35s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.66s/it]
all 71 100 0.968 0.91 0.987 0.573
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/10 0G 1.27 1.321 1.143 4 640: 100%|██████████| 36/36 [00:48<00:00, 1.35s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.64s/it]
all 71 100 0.978 0.95 0.986 0.621
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/10 0G 1.276 1.261 1.088 8 640: 100%|██████████| 36/36 [00:48<00:00, 1.34s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.67s/it]
all 71 100 0.98 0.96 0.986 0.609
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/10 0G 1.244 1.134 1.109 4 640: 100%|██████████| 36/36 [00:48<00:00, 1.34s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.65s/it]
all 71 100 0.971 0.97 0.99 0.642
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/10 0G 1.193 1.052 1.097 4 640: 100%|██████████| 36/36 [00:47<00:00, 1.33s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.66s/it]
all 71 100 0.989 0.93 0.987 0.654
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 0G 1.157 0.9957 1.081 8 640: 100%|██████████| 36/36 [00:48<00:00, 1.34s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:08<00:00, 1.65s/it]
all 71 100 0.971 0.95 0.988 0.642
10 epochs completed in 0.158 hours.
Optimizer stripped from runs/detect/train4/weights/last.pt, 6.2MB
Optimizer stripped from runs/detect/train4/weights/best.pt, 6.2MB
Validating runs/detect/train4/weights/best.pt...
Ultralytics YOLOv8.0.208 🚀 Python-3.11.5 torch-2.1.0 CPU (Apple M1 Pro)
Model summary (fused): 168 layers, 3005843 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:07<00:00, 1.60s/it]
all 71 100 0.989 0.931 0.987 0.654
Speed: 0.8ms preprocess, 106.1ms inference, 0.0ms loss, 0.9ms postprocess per image
Results saved to runs/detect/train4
582.6759631633759sec.Transferred 319/355 items from pretrained weights
Freezing layer 'model.22.dfl.conv.weight'
train: Scanning /Users/tadanori/tmp/yolov8/datasets/cars/labels/train.cache... 284 images, 0 backgrounds, 0 corrupt: 100%|██████████| 284/284 [00:00<?, ?it/s]
val: Scanning /Users/tadanori/tmp/yolov8/datasets/cars/labels/valid.cache... 71 images, 0 backgrounds, 0 corrupt: 100%|██████████| 71/71 [00:00<?, ?it/s]
Plotting labels to runs/detect/train6/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.002, momentum=0.9) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs/detect/train6
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 0G 1.337 3.056 1.098 5 640: 100%|██████████| 36/36 [00:27<00:00, 1.30it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:09<00:00, 1.96s/it]
all 71 100 0.00263 0.56 0.0741 0.0188
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/10 0G 1.345 2.391 1.098 6 640: 100%|██████████| 36/36 [00:23<00:00, 1.55it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:01<00:00, 3.24it/s]
all 71 100 0.201 0.173 0.0829 0.0309
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/10 0G 1.287 2.299 1.064 8 640: 100%|██████████| 36/36 [00:28<00:00, 1.27it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:01<00:00, 3.22it/s]
all 71 100 0.221 0.29 0.106 0.0463
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/10 0G 1.273 2.164 1.042 8 640: 100%|██████████| 36/36 [00:28<00:00, 1.26it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:01<00:00, 3.32it/s]
all 71 100 0.229 0.27 0.114 0.0464
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/10 0G 1.294 2.094 1.049 8 640: 100%|██████████| 36/36 [00:30<00:00, 1.20it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:02<00:00, 1.96it/s]
all 71 100 0.344 0.289 0.146 0.065
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/10 0G 1.201 2.03 1.042 4 640: 100%|██████████| 36/36 [00:31<00:00, 1.14it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:01<00:00, 3.09it/s]
all 71 100 0.269 0.32 0.127 0.0509
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/10 0G 1.235 1.865 0.9928 8 640: 100%|██████████| 36/36 [00:29<00:00, 1.21it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:01<00:00, 3.26it/s]
all 71 100 0.276 0.33 0.115 0.0499
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/10 0G 1.186 1.749 0.983 4 640: 100%|██████████| 36/36 [00:30<00:00, 1.19it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:01<00:00, 3.05it/s]
all 71 100 0.294 0.31 0.122 0.0532
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/10 0G 1.146 1.661 0.9614 4 640: 100%|██████████| 36/36 [00:39<00:00, 1.09s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:01<00:00, 3.04it/s]
all 71 100 0.33 0.33 0.13 0.0595
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 0G 1.138 1.64 0.9573 8 640: 100%|██████████| 36/36 [00:39<00:00, 1.09s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:01<00:00, 3.25it/s]
all 71 100 0.335 0.32 0.129 0.0623
10 epochs completed in 0.094 hours.
Optimizer stripped from runs/detect/train6/weights/last.pt, 6.2MB
Optimizer stripped from runs/detect/train6/weights/best.pt, 6.2MB
Validating runs/detect/train6/weights/best.pt...
Ultralytics YOLOv8.0.208 🚀 Python-3.11.5 torch-2.1.0 MPS (Apple M1 Pro)
Model summary (fused): 168 layers, 3005843 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 5/5 [00:14<00:00, 2.86s/it]
all 71 100 0.343 0.287 0.146 0.0653
Speed: 2.0ms preprocess, 47.9ms inference, 0.0ms loss, 2.1ms postprocess per image
Results saved to runs/detect/train6
372.99035024642944sec.