
GradCamをPyTorchのforward/backward hookで実装し、判断根拠を可視化する【初級 深層学習講座】
Aru
Aru's テクログ(Aruaru0)
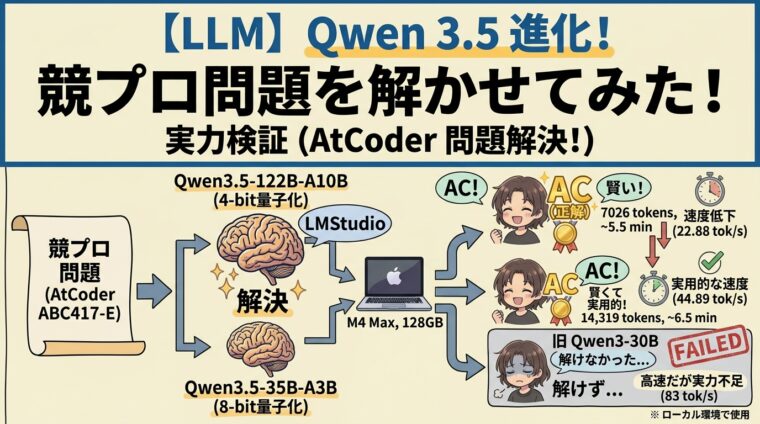
ローカルで実行可能なLLM「Qwen3」が1年ぶり(9ヶ月ぶり?)にアップデートされ、Qwen3.5が発表されました。この記事では、AtCoderの問題をQwen3.5で解いた結果を紹介します。
Qwen3.5は中国のアリババが公開したオープンソースの大規模言語モデルです。今回は、27B, 35B-A3B, 122B-A10B, 397B-A17Bというモデルが発表されました。
昨年度発表されたQwen3-30B-A3Bが割といい感じで、OpenAIのgpt-oss 20B, 120Bが発表されるまではメインのローカルLLMとして使っていましたが、新しく発表されたのでこちらを早速試してみました。
ベンチマークをみると、Qwen3.5-397B-A17BはGPT5.2, Claude Opus 4.5, Gemini 3 Proと比較しても遜色ないスコアのようです。
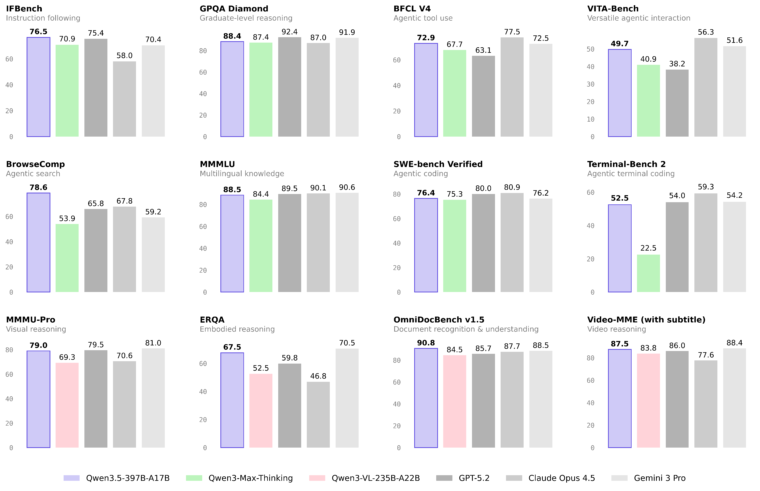
ただ、パラメータが400GB超えとなり、ローカルで手軽に動かせるサイズではありません。
以下は、ミドルサイズ(122B-A10Bと、27B, 35B-A3B)のベンチマーク結果ですが、こちらもまずまずの性能が出ているようです。
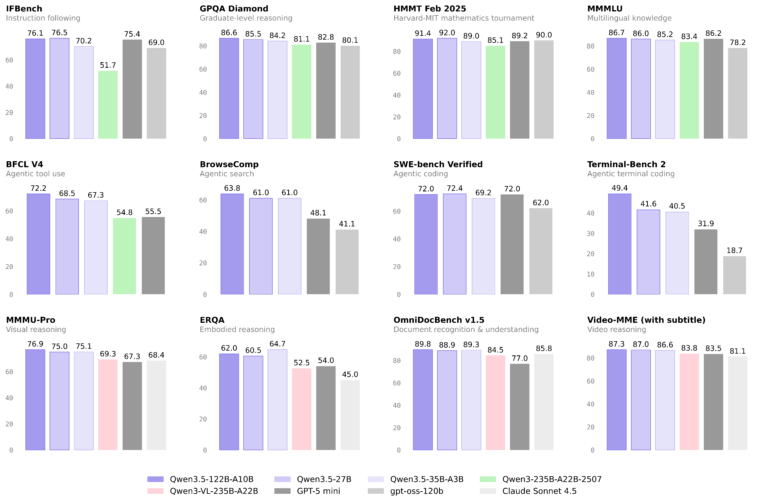
ということで、早速ダンロードして使ってみました。今回評価したのはQwen3.5-122B-A10Bと、Qwen3.5-35B-A3Bになります。
動作環境は、Qwen3-30B-A3Bをテストした時と同じ以下の環境になります。

27Bは除外しましたが、個人的にMoEモデルの方が高速だからです。
なお、Qwen3.5-122B-A10Bは4bit量子化、Qwen3.5-35B-A3Bは8bit量子化を利用しました。
| モデル名 | 量子化 | サイズ |
| Qwen3.5-122B-A10B | 4bit | 70.2GB |
| Qwen3.5-35B-A3B | 8bit | 37.8GB |
それぞれの速度は以下になります。
| モデル名 | トークン/秒 | ファーストトークンまで |
| Qwen3.5-122B-A10B | 22.88 tok/s | 0.91s |
| Qwen3.5-35B-A3B | 44.89 tok/s | 0.45s |
| Qwen3-30B-A3B(参考) | 83.25 tok/sec | 0.07s |
| gpt-oss-20b(参考) | 81.40 tok/sec | 0.68s |
| gpt-oss-120b(参考) | 52.00 tok/sec | 0.40s |
Qwen3-30B-A3Bが83.25tok/secだったので、Qwen3.5-35B-A3Bでも、これに比べると半分程度の速度になっています。同じ規模のモデルですが、少し遅くなっているようです。
とはいえ、実用的な速度です。
Qwen3.5-122B-A10Bは、似たサイズのgpt-oss-120bと比べても遅いです。
今回も、前回も同じくAtCoder ABC417-E問題を解かせてみます。他のモデルの結果は以下にあります。

今回の結果です。どちらもThinkingモードです。
どちらも問題なく正解することができました。
Qwen3-30B-A3Bでは解けなかった問題なので、Qwen3.5-122B-A10Bだけではなく、Qwen3.5-35B-A3Bもかなり性能向上したことがわかります。
このレベルの問題が解けるならQwen3.5-35B-A3Bでも、ちょっとした関数を作ったりといった普段使いには問題ないかもしれません。
Qwen3.5シリーズが出たので、手持ちのノートPCで動かせるモデルを試してみました。Qwen3と比較して確実に賢くなっている印象です。ただ、速度的にはかなり低下しています。
個人的には、40tok/sくらいは使えるレベルだと思っています。35Bクラスだとメモリに常に常駐させておいても問題ないので、日頃使うモデルとしては、Qwen3.5-35B-A3Bは十分な性能を小さなモデルで実現したと思います。最近はgpt-oss-20bを使っていましたが、こちらメインになりそうです。

gpt-oss-120bやqwen3.5-122B-A10Bなどは確かに賢いですが、128GBのメモリで常に常駐させるには少し大きすぎです。40Bクラスくらいがちょうど良いサイズだと感じます。


