
Pandasのlocとilocの違いと使い分けを詳しく解説|Python
Aru
Aru's テクログ(Aruaru0)
PyCaretは、機械学習のモデル選択のための強力なツールです。本記事では、PyCaretを使用して、クラス分類タスクにおけるモデル選択の自動化方法について解説します。PyCaretを利用すると、複数のモデルの比較・検討を簡単に行うことが可能です。また、複数のモデルをアンサンブルする機能を利用することでより高精度な予測モデルの検討を行うことが可能です。
他のタスク(Regression(回帰)・Time Series (時系列)・Clustering(クラスタリング)・Anomaly Detection(異常検知)の各タスクを行う方法については、以下の記事も参考にしてください。
TabPFNというTransformerベースの機械学習ライブラリに興味があれば以下の記事も読んでみてください。

PyCaretは、Pythonでの機械学習を効率化できるオープンソースのライブラリです。PyCaretを使うことで、データの前処理、特徴量エンジニアリング、モデル選択、ハイパーパラメータチューニング、モデル評価などのタスクを自動、または簡単に行うことでできます。
PyCaretを利用すると、scikit-learn、XGBoost、LightGBM、CatBoostといったモデルの評価も一括して行えるので、初心者だけでなく、データサイエンティストや機械学習エンジニアが初期検討の段階で複数モデルを評価する時間を短縮できます。
私の場合、PyCaretはkaggleのコンペの初手の検討手段として利用することが多いです。
以下、PyCaretの使い方などについて解説します。
なお、Google Colab用のコードをここに用意しましたので活用してください。
インストールは簡単です。以下のコマンドでインストールできます。
pip install pycaretscikit-learn、XGBoost、LightGBM、CatBoostなどでの評価も同時に行いたい場合には、これらも同時にインストールしておきます。
pip install scikit-learn
pip install xgboost
pip install lightgbm
pip install catboost以下、Google Colabのノートブックに沿って説明していきます。インストール方法は説明しましたが、Colabでは以下のコードでインストールします。なお、sklernは最初から入っていますので、省略してもOKです。
!pip install pycaret
!pip install scikit-learn
!pip install xgboost
!pip install lightgbm
!pip install catboostPyCaretの利用するライブラリをインポートをしておきます。今回は、分類を行いたいと思いますので、classificationを読み込みます。また、説明に組み込みデータセットを使いたいと思うので、get_dataも読み込んでおきます。
from pycaret.datasets import get_data
from pycaret.classification import *PyCaretでは、以下の5つのタスクが可能です。私は、このうち分類と回帰しか使ったことがありませんが、どちらも似た感じで使えたので、おそらくどれも似た感じで使えるのではないかと思います。
| タスク名 | 説明 |
| Classification(分類) | データをクラス分けするタスク |
| Regression(回帰) | 回帰予測を行うタスク |
| Time Series (時系列) | 時系列データに対する予測を行うタスク |
| Clustering(クラスタリング) | グループ分割するタスク |
| Anomaly Detection(異常検知) | 異常値を検知するタスク |
PyCaretに組み込まれているデータセット一覧は以下で調べることができます。
# 用意されているデータセット一覧を表示
all = get_data('index')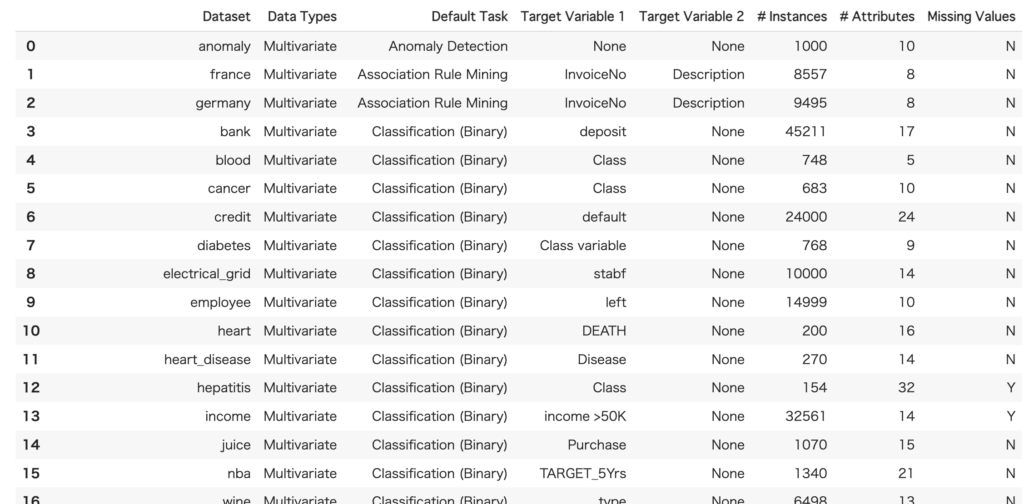
今回は、この中から5番目のcancerを使ってみたいと思います。データを読み込むには以下のコードを実行します。
df = get_data('cancer')
len(df)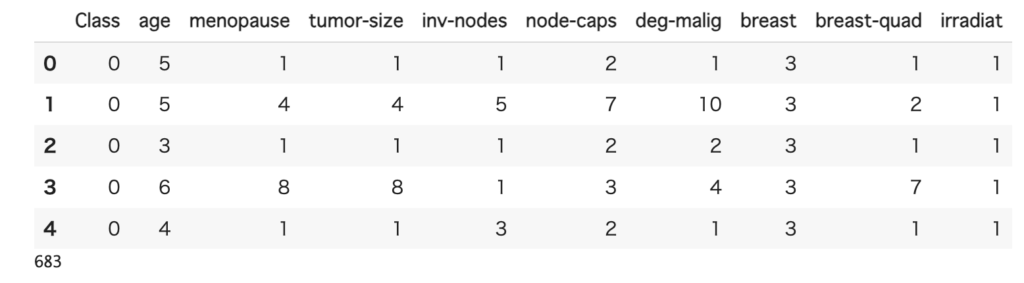
データ数は683で、全部で10列のデータです。Classが予測したい分類(0 or 1)で、残りが予測に利用できる説明変数になります。

用意したコードでは、簡単なEDA(Explanatory Data Analysis)を行なっていますので、そちらも参考に。EDAを見ると、それなりに識別できそうなデータです。
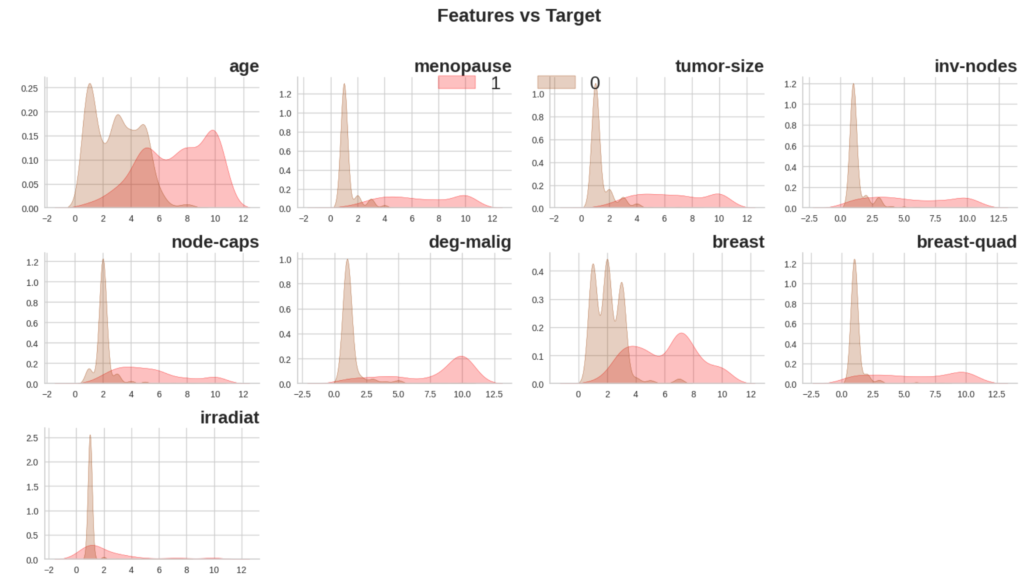
データは、訓練用と評価用の2つに分けておきます。
train, test = df[:600], df[600:]セットアップは簡単です。
seed = 42
clf = setup(data=train, target = 'Class', session_id=seed, fix_imbalance=True) setupで設定できるパラメータのうち、よく使うものです。今回のデータでは、予測したいのはClassで、EDAからクラス0とクラス1が均等ではなかったので、fix_imbalanceも設定しています。
| パラメータ名 | 説明 |
| data | データを設定 |
| target | 目的変数を設定 |
| ignore_features | 無視する列をリストで設定 |
| session_id | 乱数のシード |
| fix_imbalance | 不均等なデータの補正を行う |
| remove_outliers | 外れ値除去 |
設定は以下のようになります。Fix imbalanceがTrueになっています。

不均衡データのリバランスにはSMOTEが使われているようです。

Pycaretの前処理によって変換されたデータフレームを確認したい場合は、以下のコマンドを使います
get_config('X_transformed')前処理に関しては別の記事にしていますのでそちらを参考にしてください。
とりあえず、各モデルで予測して比較してみます。以下のコードで、さまざまなモデルの比較ができます。
best = compare_models()結果は、以下のように表示されます。今回の場合はknnが最も結果が良かったようです。
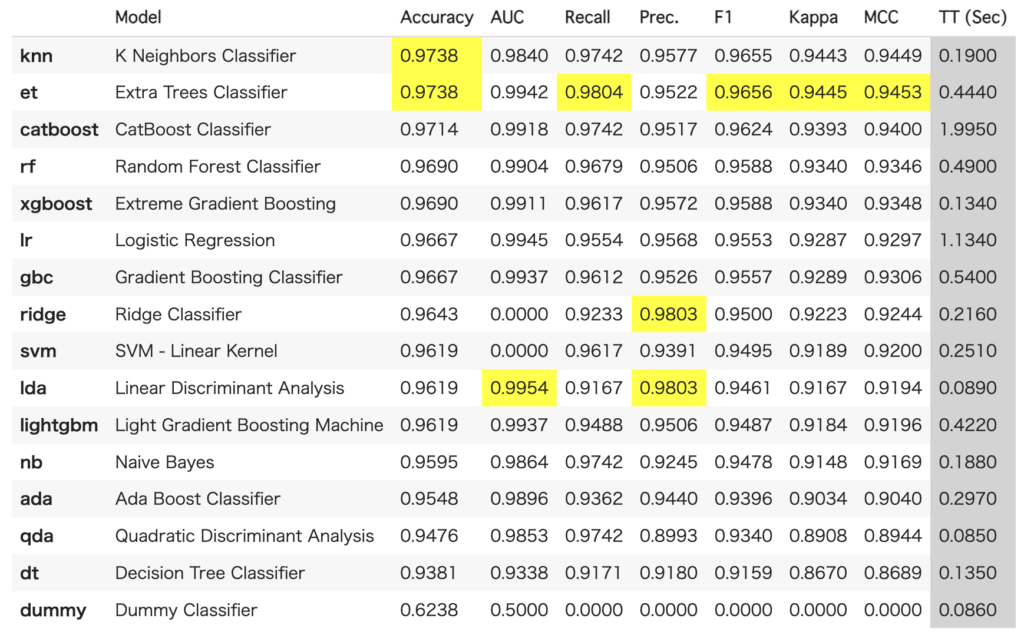
なお、bestには、最も良かったモデルが格納されます。
どのスコア順に並べるか、また、ベストだけでなく、上位n個を返すといった設定も可能です。この場合は、以下のようにします。
以下では、ソートをF1スコアで、上位3モデルを返しています。
best = compare_models(sort='F1', n_select=3)先ほどとは異なり、F1でソートされていることがわかります。
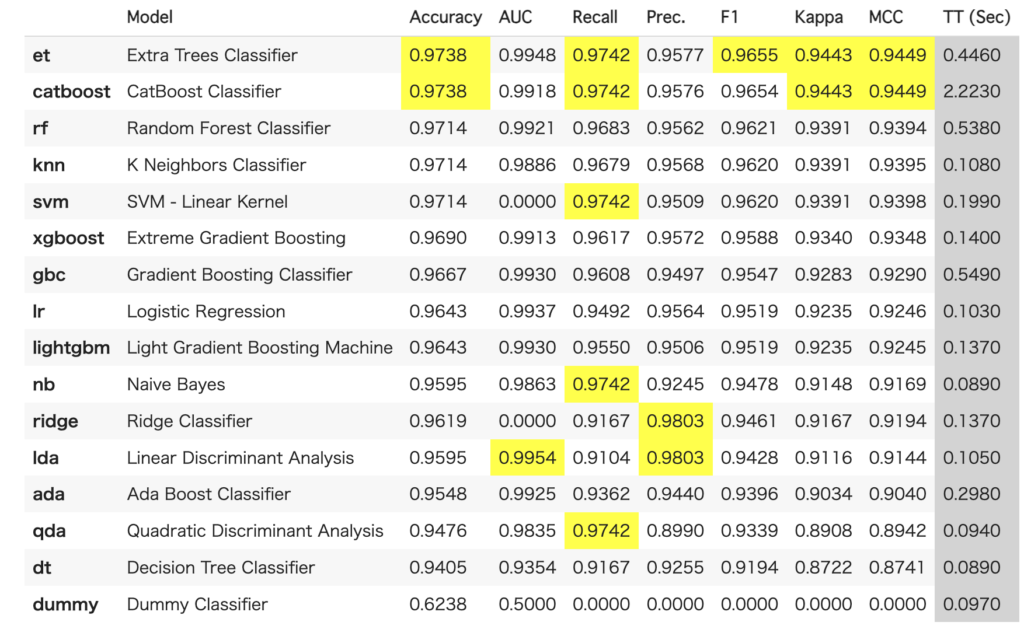
特定のモデルだけ比較したい場合は、以下のようにincludeを使って指定できます。
compare_models(sort = 'F1', include = ['lightgbm', 'xgboost', 'catboost'])なお、モデル一覧はmodels()で表示するとができます。
以上のように、とりあえず色々なモデルを一斉に評価するは非常に簡単です。とりあえず、まずはPyCaretを使って試してみるというのはアリかと思います。
PyCaretではモデルの最適化も可能です。以下はlightGBMのモデルを作り、最適化を行う例です。tuned_lgbにはパラメータが最適化されたモデルが格納されます。
lgb = create_model('lightgbm')
tuned_lgb = tune_model(lgb)下の表は、上が最適化前、下が最適化後です。スコアが向上しているのが確認できます。
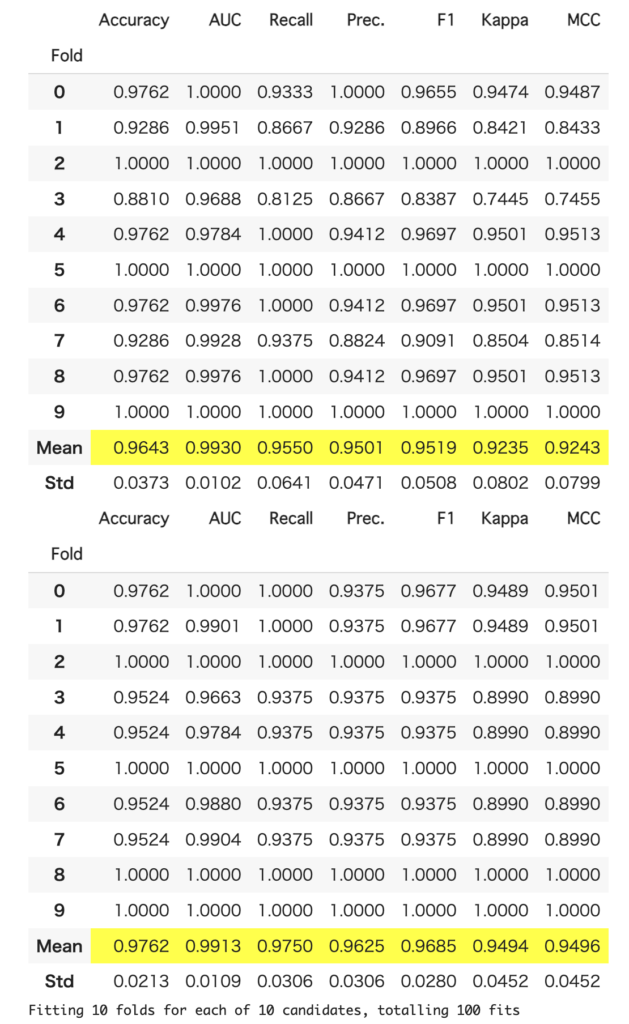
tune_modelには、n_iterなど、設定できるパラメータがいくつかあります。詳しくはここを参考にしてください。よく使うのは、繰り返し回数を設定するn_iterと、最適化の対象とする指標(Accuracy, r2とか)を設定するoptimizeでしょうか。
最適化手法も変更できます。例えば、optunaを使いたい場合には、
search_library = 'optuna'
をtune_modelの引数に追加します
ちなみに、最適化したパラメータは、以下のコードで確認することができます。PyCaretで最適化まで行い、そのパラメータを取り出して直接(lightGBMなどを)使う時などに重宝しますので覚えておくと良いです。
tuned_lgb.get_all_params()PyCaretではモデルのブレンドも簡単にできます。先ほど比較した上位3モデルのブレンドしたい場合は以下のようにします。
blend = blend_models(estimator_list = best)ブレンドした結果も、以下のように表示されます。
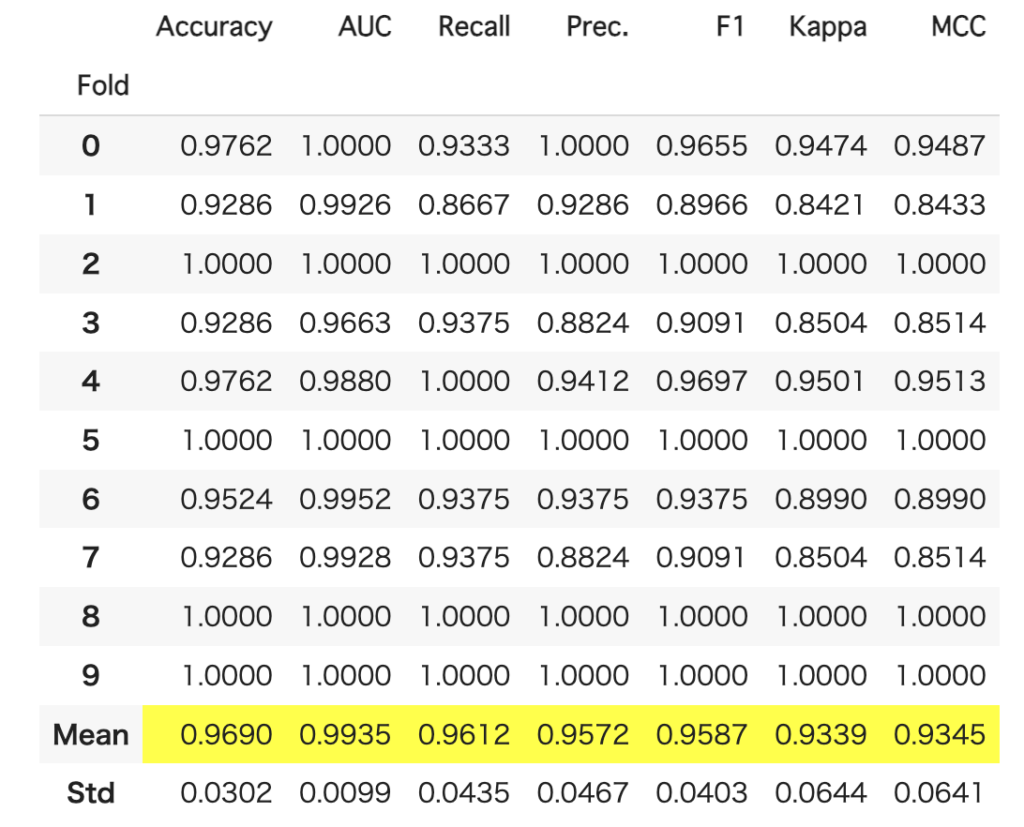
ここまでは、データを分割してトレーニングを行っていました。最後に、全データを使って訓練します。PyCaretでは、これをファイナライズと呼びます。処理自体は以下のように関数を呼び出すだけです。
finalized_model = finalize_model(blend)ファイナライズしたモデルを使って予測を行いたい場合、predict_modelを使います。なお、予測自体はファイナライズを行う前のモデルでも行うことができます。
pred = predict_model(finalized_model, data=test[test.columns[1:]])
pred結果が末尾2列に追加されています。
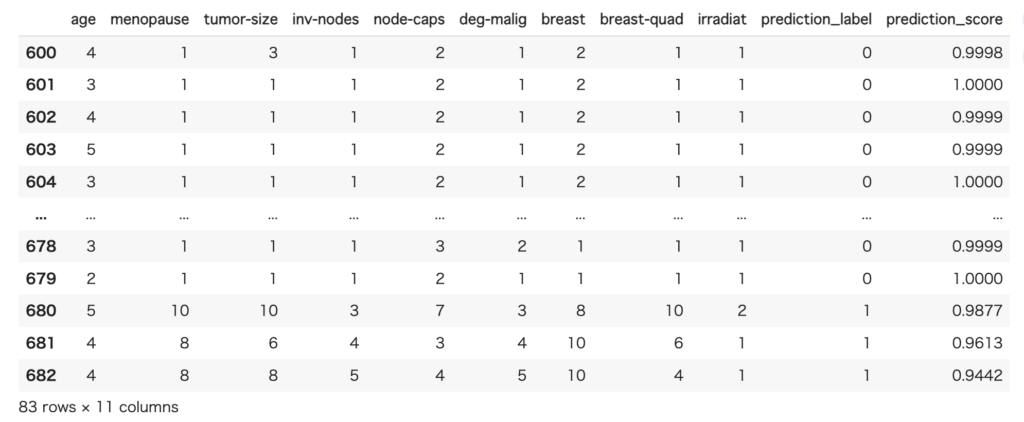
予測精度を確認してみます。それなりに、ちゃんと予測できてそうです。
from sklearn.metrics import *
confusion_matrix(test.Class, pred.prediction_label)
accuracy_score(test.Class, pred.prediction_label)0.9879518072289156ちなみに、クラス0のスコア、クラス1のスコアを出したい場合には、raw_score=Trueを追加します。
predict_model(finalized_model, data=test[test.columns[1:]], raw_score=True)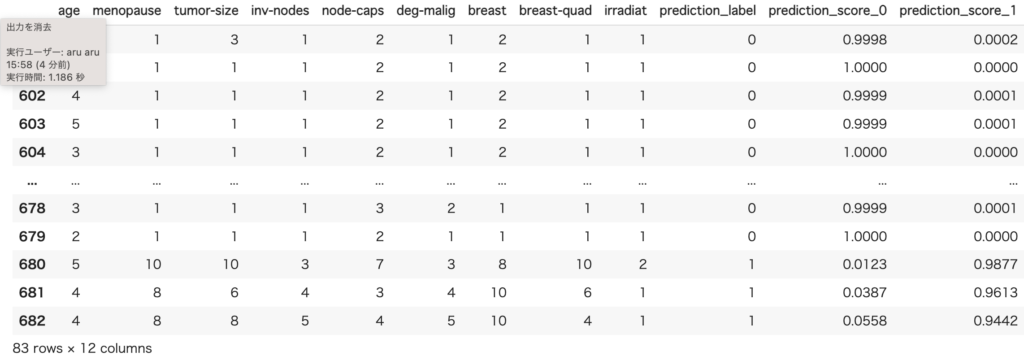
モデルの保存と読み込みも簡単です。モデルの保存はsave_modelを使います。保存したいモデルと、ファイル名を指定することでファイルに保存できます。
save_model(finalized_model, "models")保存したモデルを読み込むには、load_modelを使います。読み込んだモデルは、予測などの関数を呼び出して使うことができます。
loaded = load_model("models")PyCaretで評価、モデル選定、学習、モデルの保存ができますので、これだけで機械学習の予測モデルを使うことができます。
PyCaretは初心者にとっては強力な機械学習のツールです。また、熟練者でも初期検討で利用すると便利だと思います。私の場合は、EDAと一緒にサクッと結果を見たい時などに、PyCaretを利用しています。
巷ではノーコードが流行っていますが、PyCaretから始めた方が、自分で前処理などのコードを書いていくなどステップアップする場合は、良いと思います。



