
大規模言語モデル(LLM)パラメータ「temperature, top_k, top_p」について【初級 深層学習講座】
ラベル平滑化(Label Smoothing)とは?アルゴリズムとPytorchでの実装方法【初級 深層学習講座】

Aru
ラベル平滑化(Label Smoothing)とは、モデルの精度を向上させるために使われるテクニックの1つで、クラス分類タスクで効果を発揮します。この記事では、「ラベル平滑化とは何か?」について、基本的な概念とアルゴリズムについて、PyTorchでの実装例を使って解説します。
ラベル平滑化(label smoothingとは)
ラベル平滑化(Label Smoothing)は、機械学習や深層学習において、モデルの性能を向上させるために使われるテクニックの一つです。
ラベル平滑化の目的は、学習時の過剰適合(overfitting)の抑制です。
以下、具体的にどのような操作を行うかを解説します。
通常のクラス分類タスクの学習では、正解ラベルを1として学習を行います。具体的には、正解ラベルには1を、他のクラスには0を確信度として与えて学習させます(下図右)。
ラベル平滑化では、正解ラベルの確信度を少し下げ、その代わりに他のラベルの確信度をある程度与えて学習を行います。
下図(左)は、ラベル平滑化を行なった例です。ラベル平滑化では、正解ラベルの値を1から0.9のように少し下げ、残りの0.1を他のラベルに割り振ります。
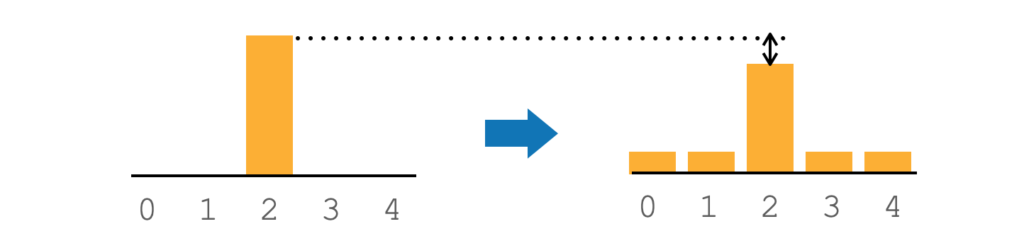
ラベル平滑化では、このように少しだけ確信度を下げることでモデルがデータに過度に適合するのを防ぎ、一般化能力を高めます。
具体的な計算
以下、ラベル平滑化の具体的な計算手順について解説します。
正解ラベルがgt = [0,0,1,0,0]で与えられているとすると、ラベルスムージングは以下の式で表すことができます。
$$
gt = gt * (1-\epsilon) + \frac{\epsilon}{K}
$$
式中の$\epsilon$は、確率分布を滑らかにするために使用されるパラメータです。0から1の間の値を取ります。$K$はクラス数です。
この式を図にすると、以下のようなイメージになります。
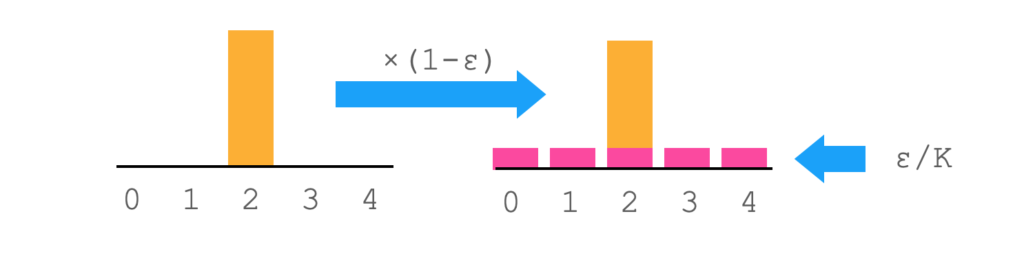
これは、最初に説明したラベルスムージングの処理と一致します。
ラベル平滑化のプログラム例(1)
以下、具体的なプログラムの例です。
プログラムでは以下のような記述になります。
import torch
e = 0.1
k = 5
gt = torch.tensor([0, 0, 1, 0, 0], dtype=torch.float32)
gt = gt*(1-e) + e/k
print(gt)
# tensor([0.0200, 0.0200, 0.9200, 0.0200, 0.0200])ラベル平滑化のプログラム例(2)
多くの場合、正解ラベルは数値で与えれているかと思います。正解ラベルが数値で与えられている場合は、一旦one-hotエンコーディングに直して同様の処理を行います。
import torch
e = 0.1
k = 5
gt = torch.tensor([2])
gt = torch.nn.functional.one_hot(gt, num_classes=k) * (1-e) + e/k
print(gt)
# tensor([0.0200, 0.0200, 0.9200, 0.0200, 0.0200])One-hotエンコーディングとは?
One-hotエンコーディングは、カテゴリデータを変換する方法の1つです。
例えば、カテゴリ数が3で、正解がカテゴリ1の場合、one-hotエンコーディングではこれを[1, 0, 0]というベクトルで表現します。もし、正解がカテゴリ2の場合は、[0, 1, 0]と2番目の位置を1にしたベクトルで表現します。
このように数値データを正解の1つだけが1にとなるベクトルデータに変換したものをone-hotエンコーディングと言います。
Pytorchの実装
以下、Pytorchでの具体的な実装になります。
CrossEntropyLoss
PyTorchのCrossEntropyLossには、ラベルスムージングを行うためのパラメータがあります。ここに$\epsilon$を代入することでラベルスムージングすることができます。
この機能を使えば、自分でラベルスムージングを実装する必要はありません。
import torch
from torch.nn import CrossEntropyLoss
gt = torch.tensor([0, 0, 1, 0, 0], dtype=torch.float32)
pred = torch.tensor([0.1, 0.1, 0.8, 0.1, 0.1], dtype=torch.float32)
loss = CrossEntropyLoss(label_smoothing=0.1)
print(loss(pred, gt))
# tensor(1.1500)ラベル平滑化を自分で行った場合
CrossEntropyLossのラベル平滑化のパラメータの動きを確認するために、ラベルスムージングを自分のコードで行ったのちにCrossEntropyLossを実行し、結果が一緒になるか確認してみます。
下のプログラムでは、ラベル平滑化をコード中で行った後に、CrossEntropyLossに与えていま。当然ですが、結果は、abel_smoothing=0.1を渡した場合と同じになります。。
e = 0.1
k = 5
gt = torch.tensor([0, 0, 1, 0, 0], dtype=torch.float32)
gt = gt*(1-e) + e/k
print(gt)
# tensor([0.0200, 0.0200, 0.9200, 0.0200, 0.0200])
pred = torch.tensor([0.1, 0.1, 0.8, 0.1, 0.1], dtype=torch.float32)
print(pred)
# tensor([0.1000, 0.1000, 0.8000, 0.1000, 0.1000])
print(gt)
# tensor([0.0200, 0.0200, 0.9200, 0.0200, 0.0200])
loss = CrossEntropyLoss()
loss(pred, gt)
# tensor(1.1500)
自分でラベル平滑化する方法は、ラベル平滑化をサポートしていない損失関数を利用する場合に使うことができるので、覚えておくと便利です。
まとめ
この記事ではラベル平滑化(label smoothing)について解説しました。簡単な処理で効果がありますので覚えておいて損はないと思います。



ディープラーニングに関する記事一覧はこちら

ディープラーニング関連の記事一覧
ABOUT ME

専門分野は並列処理・画像処理・機械学習・ディープラーニング。プログラミング言語はC, C++, Go, Pythonを中心として色々利用。現在は、Kaggle, 競プロなどをしながら悠々自適に活動中



