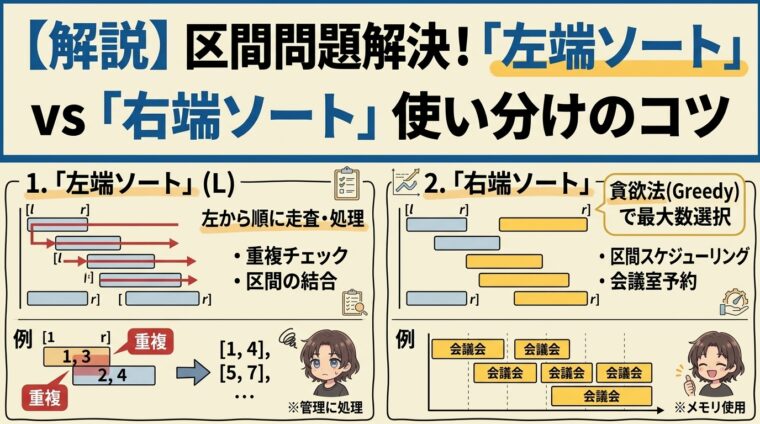
区間問題の解き方|「左端ソート」と「右端ソート」の使い分けのコツ
Aru
Aru's テクログ(Aruaru0)
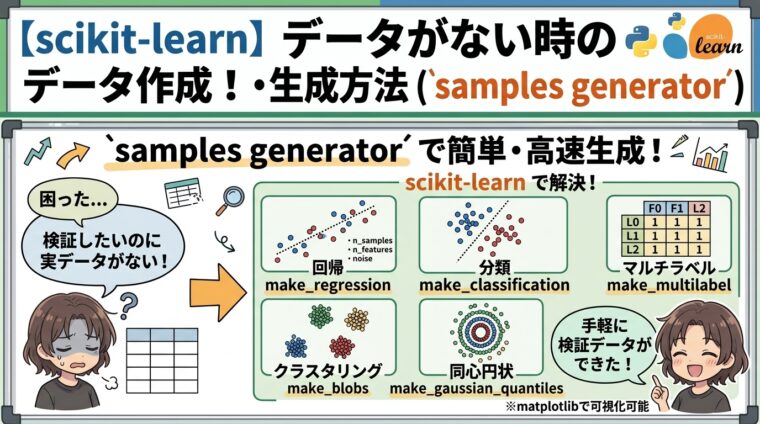
機械学習の検証では、実データを用意する前にアルゴリズムの挙動を確認したい場面があります。本記事では、scikit-learnのsamples generatorを利用して、特徴量の構造やノイズを制御しながら人工データセットを生成する方法を紹介します。
アルゴリズムのチェックのために、データを用意したり、ゼロからダミーデータを作るのは意外と面倒です。単純なデータであれば乱数を使ってる作ることもできますが、クラス分類や回帰問題用など、目的に合わせて「それっぽい(意味のある特徴量の)」データをつくるのは結構手間です。
pythonの代表的な機械学習ライブラリである scikit-learn では、Samples generator という人工的にデータセットを生成させるための関数が用意されています。
ここでは、このライブラリを使って人工データを生成する方法を紹介します。

試しに使う場合は、make_classificationとmake_regressionだけで良い気もします
| 関数名 | 説明 |
datasets.make_blobs([n_samples, n_features, …]) | 分類問題のデータセットを生成する |
datasets.make_classification([n_samples, …]) | クラス分類問題のデータセットを作成する |
datasets.make_gaussian_quantiles(*[, mean, …]) | 等方性ガウス分布の分布を生成し、クラス分類データセットを作成する |
datasets.make_hastie_10_2([n_samples, …]) | Hastie et al. で使用されている二項分類用のデータセットを生成する |
datasets.make_multilabel_classification([…]) | ランダムなマルチラベル分類問題のデータセットを生成する |
datasets.make_regression([n_samples, …]) | 回帰問題のデータセットを生成する |
それでは、実際にコードを動かしてどのようなデータが生成されるのか見ていきましょう。可視化には matplotlib を使用します。
datasets.make_classification([n_samples, …])2値分類や多クラス分類のためのデータを生成します。特徴量の中に「意味のある特徴量」と「ノイズ(意味のない特徴量)」を混ぜることができるため、より現実のデータに近い複雑なデータセットを作ることができます。
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
# データセットの生成
X, y = make_classification(
n_samples=200, # サンプル数
n_features=2, # 特徴量の数
n_informative=2, # 目的変数に影響する意味のある特徴量の数
n_redundant=0, # 意味のある特徴量の線形結合で作られる冗長な特徴量の数
n_classes=2, # クラスの数(今回は2値分類)
n_clusters_per_class=1, # 1クラスあたりのクラスタ数
random_state=42
)
# 可視化
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='bwr', edgecolors='k', alpha=0.7)
plt.title("make_classification")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()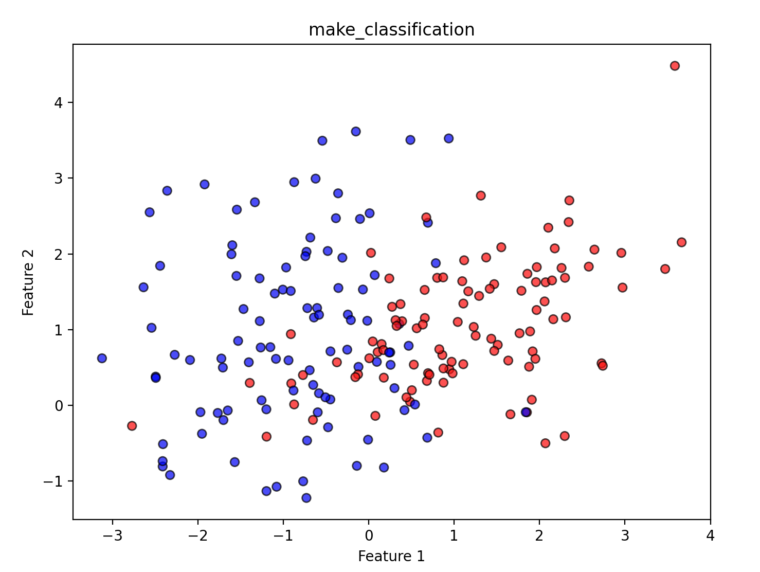
作成したデータは、2つのクラスのモデルです。データを見ると、Feature 1とFeature 2により、2つのクラスの分布が分かれていることが分かります。ただ、少しだけ重なりもあるので、完全な分離ができないという、よさそうな人工データが作られています。
上記の方法で作成したデータをlightGBMで学習・評価するコードです。サンプル数は、1000個と先ほどより増やしています。
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.datasets import make_classification
# データセットの生成
X, y = make_classification(
n_samples=1000, # サンプル数
n_features=2, # 特徴量の数
n_informative=2, # 目的変数に影響する意味のある特徴量の数
n_redundant=0, # 意味のある特徴量の線形結合で作られる冗長な特徴量の数
n_classes=2, # クラスの数(今回は2値分類)
n_clusters_per_class=1, # 1クラスあたりのクラスタ数
random_state=42
)
# ステップ1: 全体の25%(100サンプル分)をテストデータとして切り出す
X_train_val, X_test, y_train_val, y_test = train_test_split(
X, y, test_size=0.10, random_state=42, stratify=y
)
# ステップ2: 残りの75%を訓練(800)と検証(100)に分割 (100/900)
X_train, X_val, y_train, y_val = train_test_split(
X_train_val, y_train_val, test_size=100/900, random_state=42, stratify=y_train_val
)
print(f"Train size: {len(X_train)}, Val size: {len(X_val)}, Test size: {len(X_test)}")
# Dataset形式に変換
train_data = lgb.Dataset(X_train, label=y_train)
val_data = lgb.Dataset(X_val, label=y_val, reference=train_data)
# パラメータ設定(二値分類の例)
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'verbosity': -1,
'boosting_type': 'gbdt',
'random_state': 42,
'learning_rate': 0.05,
'num_leaves': 31
}
# 学習
model = lgb.train(
params,
train_data,
valid_sets=[train_data, val_data],
valid_names=['train', 'valid'],
num_boost_round=1000,
callbacks=[
lgb.early_stopping(stopping_rounds=50), # 50回改善がなければ終了
lgb.log_evaluation(period=10) # 10回ごとにログ表示
]
)
# テストデータで予測
y_pred_prob = model.predict(X_test, num_iteration=model.best_iteration)
y_pred = np.where(y_pred_prob > 0.5, 1, 0) # 閾値0.5でクラス分け
# 結果の表示
print("\n--- Test Data Evaluation ---")
print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f}")
print(classification_report(y_test, y_pred))結果は以下のようになります。テスト結果を見ると9割付近の正答率であることが分かります(クラス0の方が少しだけ精度(precision)が悪いことも分かります)
Train size: 800, Val size: 100, Test size: 100
Training until validation scores don't improve for 50 rounds
[10] train's binary_logloss: 0.40216 valid's binary_logloss: 0.437065
[20] train's binary_logloss: 0.264528 valid's binary_logloss: 0.320001
[30] train's binary_logloss: 0.189491 valid's binary_logloss: 0.262851
[40] train's binary_logloss: 0.146763 valid's binary_logloss: 0.234169
[50] train's binary_logloss: 0.120004 valid's binary_logloss: 0.219821
[60] train's binary_logloss: 0.101965 valid's binary_logloss: 0.218595
[70] train's binary_logloss: 0.0889157 valid's binary_logloss: 0.227693
[80] train's binary_logloss: 0.0790398 valid's binary_logloss: 0.239471
[90] train's binary_logloss: 0.0703472 valid's binary_logloss: 0.251112
[100] train's binary_logloss: 0.0615857 valid's binary_logloss: 0.262127
Early stopping, best iteration is:
[57] train's binary_logloss: 0.10672 valid's binary_logloss: 0.215986
--- Test Data Evaluation ---
Accuracy: 0.9200
precision recall f1-score support
0 0.89 0.96 0.92 50
1 0.96 0.88 0.92 50
accuracy 0.92 100
macro avg 0.92 0.92 0.92 100
weighted avg 0.92 0.92 0.92 100datasets.make_regression([n_samples, …])連続値を予測する「回帰問題」用のデータを生成します。ノイズ(noise)の大きさを調整することで、データのばらつき具合をコントロールできます。
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
# データセットの生成
X, y = make_regression(
n_samples=200, # サンプル数
n_features=1, # 特徴量の数(今回は2次元プロットのため1)
noise=15.0, # ノイズの大きさ(ばらつき)
random_state=42
)
# 可視化
plt.figure(figsize=(8, 6))
plt.scatter(X, y, color='blue', alpha=0.7)
plt.title("make_regression")
plt.xlabel("Feature 1")
plt.ylabel("Target")
plt.show()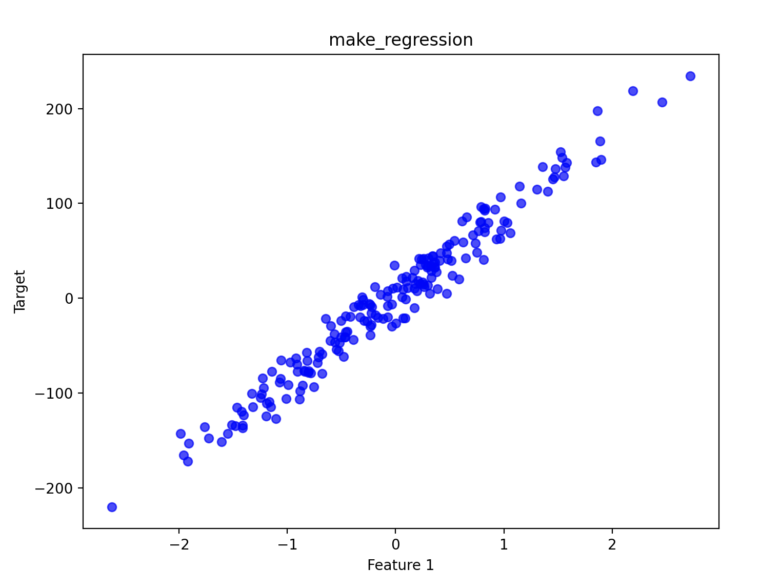
作成したデータは、一定の直線上に分布しているが、ランダム性があることがわかります。
datasets.make_blobs([n_samples, n_features, …])指定した数の塊(クラスタ)を持つデータを生成します。主にK-Meansなどの「クラスタリング手法」の動作確認によく使われます。各クラスタの標準偏差(ばらつき)を指定することも可能です。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# データセットの生成
X, y = make_blobs(
n_samples=300, # サンプル数
n_features=2, # 特徴量の数
centers=3, # クラスタ(塊)の数
cluster_std=1.5, # クラスタのばらつき
random_state=42
)
# 可視化
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', edgecolors='k', alpha=0.7)
plt.title("make_blobs")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()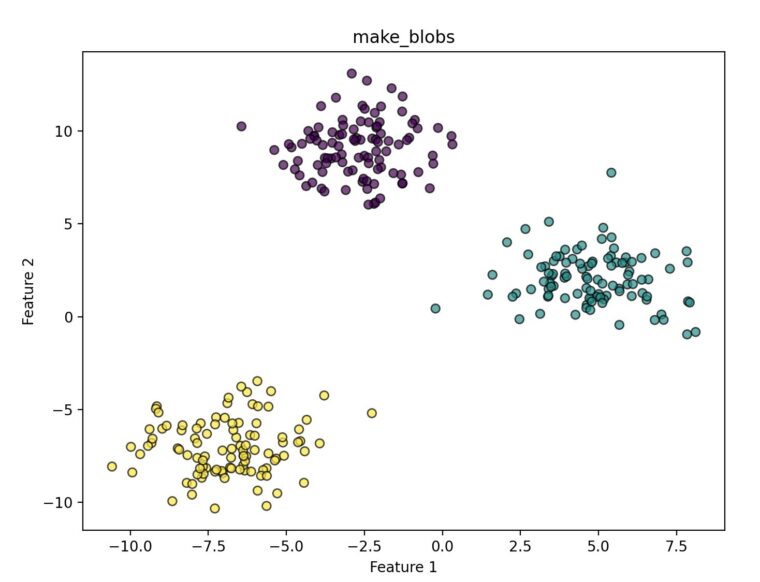
今回作成したデータではcluster_stdが大きすぎるので、綺麗に分かれてしまっていますが、値を調整することで近づけることも可能です。
datasets.make_gaussian_quantiles(*[, mean, …])原点を中心とした同心円状(多次元の場合は球状)にクラスが分かれるようなデータを生成します。線形分離が不可能なデータセットを作りたい場合(SVMのRBFカーネルのテストなど)に便利です。
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
# データセットの生成
X, y = make_gaussian_quantiles(
n_samples=300, # サンプル数
n_features=2, # 特徴量の数
n_classes=3, # クラスの数
random_state=42
)
# 可視化
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='plasma', edgecolors='k', alpha=0.7)
plt.title("make_gaussian_quantiles")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()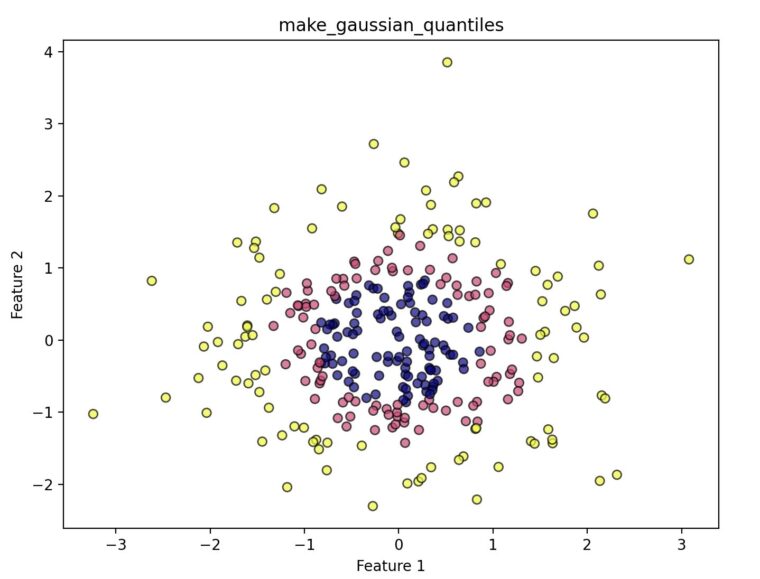
datasets.make_hastie_10_2([n_samples, …])機械学習の名著『The Elements of Statistical Learning』(Hastieら著)で使用されている、非線形な2値分類問題を再現するデータセットです。特徴量は常に10次元で生成されます。
import matplotlib.pyplot as plt
from sklearn.datasets import make_hastie_10_2
# データセットの生成(特徴量は常に10次元)
X, y = make_hastie_10_2(
n_samples=1000,
random_state=42
)
# 10次元なので、最初の2つの特徴量だけをプロットしてみる
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm', edgecolors='k', alpha=0.5)
plt.title("make_hastie_10_2 (Feature 0 vs Feature 1)")
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.show()
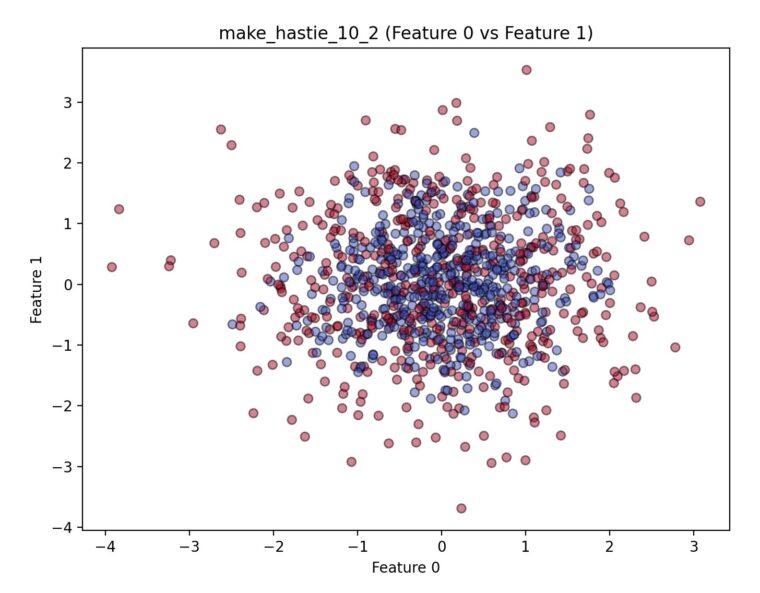
ここでは、10次元の特徴のうち2つだけでプロットしているので、重なり合っているように見えますが、10次元で見れば「おそらく」距離が離れていると思います。
datasets.make_multilabel_classification([…])1つのサンプルが複数のクラス(ラベル)に同時に属する可能性がある「マルチラベル分類」のデータセットを生成します。(例:1つの記事に「Python」「機械学習」「入門」の3つのタグが付くようなケース)
from sklearn.datasets import make_multilabel_classification
import pandas as pd
# データセットの生成
X, Y = make_multilabel_classification(
n_samples=5, # サンプル数(確認のため少なめに)
n_features=3, # 特徴量の数
n_classes=4, # ラベルの種類数
random_state=42
)
# 結果の確認(特徴量 X)
print("--- 特徴量 (X) ---")
print(pd.DataFrame(X, columns=[f"Feature_{i}" for i in range(X.shape[1])]))
# 結果の確認(ラベル Y)
print("\n--- ラベル (Y) ---")
print(pd.DataFrame(Y, columns=[f"Class_{i}" for i in range(Y.shape[1])]))
--- 特徴量 (X) ---
Feature_0 Feature_1 Feature_2
0 8.0 17.0 16.0
1 11.0 17.0 15.0
2 25.0 15.0 20.0
3 7.0 17.0 29.0
4 15.0 27.0 22.0
--- ラベル (Y) ---
Class_0 Class_1 Class_2 Class_3
0 0 1 1 0
1 1 0 0 1
2 0 0 1 1
3 1 1 1 0
4 0 1 1 1上記のように、ラベル(Y)を見ると、1つのサンプルに対して 1 が複数立っている(複数のクラスに属している)ことが分かります
パラメーターの目的別の逆引きです。データ作成の参考にしてください。
機械学習の学習・検証用ダミーデータを生成する Samples generator について紹介しました。
scikit-learnで簡単にデータが作れることを覚えておくと、アルゴリズムのプロトタイピングや、ライブラリの挙動を確認したい時に便利です。



