Label Studioの自動アノテーション(AI支援)にYOLOv8を使う方法
Aru
Aru's テクログ(Aruaru0)

Kaggleに取り組み始めてからPyTorchしか使わなくなった私が、tensorflow/kerasを使って犬猫分類の実装にチャレンジしてみました。この記事では、PyTorchユーザから見た、kerasのメリット・デメリットと感想になります。具体的には、ResNet50を用いたモデルを学習・推論させてみました。
Kerasは、ニューラルネットワークの構築とトレーニングを容易にする高水準のニューラルネットワークライブラリで、バックエンドエンジンとしてTensorFlowやTheano、Microsoft Cognitive Toolkitなどをサポートするライブラリです。
ただ、Kerasはバックエンドにtensorflowを使う、tensorflowに統合されたものを指すことが多いと思います。
この記事でも、tensorflowに統合されたKerasを使っています。Tensorflowと統合されているので、tensorflowがインストールすれば個別にインストールする必要はありません。
今回は、Google Colab上で実際にKerasを使って犬猫のクラス分類について、学習と推論をやってみました。
Google Colabで動くノートブックはこちらにありますので、参考にしてください。
PyTorchでも犬猫分類をやっています。Pytorchの記事は以下になります

GoogleImageCrawlerを使って画像を収集しようかと思いましたが、画像数が100枚程度と少ない場合、訓練データに過学習してしまいうまく学習できませんでした。
なので、ここでは、Kaggle Cats and Dogs Datasetを使いました。このデータセットはこちらからダウンロードすることが可能です。
データセットをColabでダウンロードする場合は、以下のコードをコードセルで実行します。
!wget https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip
!unzip kagglecatsanddogs_5340.zipこれで、画像データがダウンロードされ、展開されます。ただ、画像枚数が多く学習に時間がかかるので、今回はこの中から約2,000枚を取り出して学習させます。
以下のコードで、images/trainに訓練画像が、images/validに評価画像が格納されます。

最後の行でrm images/train/cat/666.jpgを実行しているのは、この画像の読み込みエラーが発生したからです。

エラーが発生する画像かどうかは以下のコードで確認しました
import tensorflow as tf
files = glob.glob("./images/train/*/*.jpg")
for file in files:
print(file)
img = tf.io.read_file(file)
tf.image.decode_image(img)!mkdir images images/train images/valid images/train/cat images/train/dog images/valid/cat images/valid/dog
!cp PetImages/Cat/??.jpg images/valid/cat
!cp PetImages/Dog/??.jpg images/valid/dog
!cp PetImages/Cat/???.jpg images/train/cat
!cp PetImages/Dog/???.jpg images/train/dog
!rm images/train/cat/666.jpg今回のコードで利用するライブラリをインポートしておきます。
import os
import random
import glob
import matplotlib.pyplot as plt
import keras
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.applications.resnet50 import ResNet50
from tensorflow.keras.applications import EfficientNetB0
from keras.models import Sequential, Model
from keras.layers import Input, Flatten, Dense, GlobalAveragePooling2D, Dropout, BatchNormalization
from keras import optimizers
from keras.callbacks import ModelCheckpoint, EarlyStopping各種変数を初期化します。
classes = ['cat','dog']
nb_classes = len(classes)
#train val dir
train_dir = './images/train'
val_dir = './images/valid'
model_dir = './model'データセットの定義を行います。train, validの2つデータセットを作成します
Kerasでは、ImageDataGeneratorで、データ拡張を含めて定義しておいて、flow_from_directoryなどを使って、データを指定する形式のようです。
訓練データでは、フリップや回転、その他のデータ拡張を行い、検証データはスケール変更だけを行っています。また、target_sizeで入力を224,224にリサイズしています。
各引数の意味は以下になります
target_size 画像のサイズkeep_aspect_ratio 画像のアスペクト比を保持するかどうかのフラグcolor_mode 画像のカラーモードrgb, grayscaleなどを設定可能classes クラス名のリストclass_mode クラスのモードbatch_size バッチサイズshuffle 画像をシャッフルするかどうかimg_w, img_h = 224,224
batch_size = 16
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
# vertical_flip = True,
horizontal_flip = True,
rotation_range=20,
zoom_range=0.2,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.05
)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_h,img_w),
# keep_aspect_ratio = True,
color_mode = 'rgb',
classes = classes,
class_mode = 'categorical',
batch_size = batch_size,
shuffle = True,
)
val_datagen = ImageDataGenerator(
rescale=1.0 / 255,
)
validation_generator = val_datagen.flow_from_directory(
val_dir,
target_size=(img_h,img_w),
# keep_aspect_ratio = True,
color_mode = 'rgb',
classes = classes,
class_mode = 'categorical',
batch_size = batch_size,
shuffle = False
)記述の仕方は異なりますが、このあたりはPyTorchと似た感じです。
実行結果
Found 1799 images belonging to 2 classes.
Found 180 images belonging to 2 classes.結果より、訓練データが1799枚、評価データが180枚、クラスが2クラスであることがわかります。
訓練データ、検証データの中身を確認します
items = next(iter(train_generator))
plt.figure(figsize=(12,12))
for i in range(len(items[1])):
plt.subplot(5,5,i+1)
plt.imshow(items[0][i])
label = classes[int(np.argmax(items[1][i]))]
plt.title(label)
plt.axis('off')
items = next(iter(validation_generator))
plt.figure(figsize=(12,12))
for i in range(len(items[1])):
plt.subplot(5,5,i+1)
plt.imshow(items[0][i])
label = classes[int(np.argmax(items[1][i]))]
plt.title(label)
plt.axis('off')検証データはシャッフルしていない(shuffle=False)なので、先に猫が並んでいます(対して、訓練データは、順番がバラバラになる)

今回は、ファインチューンを行うので、一部のレイヤーだけ学習を行うことにします。
ベースモデルをResnet50にしてモデルを作成しています。
今回は、Resnet50の出力の後ろに、
GlobalAveragePooling2D→BatchNormalization→Dropout→Dense
を追加しました。
base_model.trainable = Falseとしているので、Resnet50の部分はフリーズされ、追加したレイヤーだけを学習することになります。
checkpoint = ModelCheckpoint(
filepath = os.path.join(
model_dir,
'model_{epoch:02d}.hdf5'
),
save_best_only=True
)
early_stopping = EarlyStopping(monitor='val_loss',patience=3,verbose=0,mode='auto')
input_tensor = Input(shape=(img_h,img_w,3))
base_model = ResNet50(
weights='imagenet',
include_top=False,
input_tensor=input_tensor,
)
base_model.trainable = False
x = GlobalAveragePooling2D(name="avg_pool")(base_model.output)
x = BatchNormalization()(x)
top_dropout_rate = 0.2
x = Dropout(top_dropout_rate, name="top_dropout")(x)
output_tensor = Dense(2,activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output_tensor)
optimizer = keras.optimizers.Adam(learning_rate=1e-3)
model.compile(optimizer=optimizer,
loss="categorical_crossentropy",
metrics=['accuracy'])
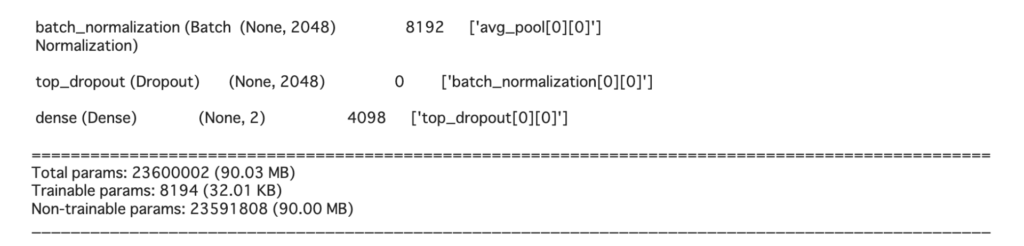
model.summary()学習するパラメータの数は、model.summary()の出力の最後のTrainable paramsで確認することができます。今回は、少ないレイヤーしか学習させないので、Total paramsが90.03MBであるのに対して、訓練するパラメータは32.01KBと非常に少ないことがわかります。
以下が学習部分のコードです。
!rm model/*
epochs = 20
train_step_size = train_generator.n // train_generator.batch_size
valid_step_size = validation_generator.n // validation_generator.batch_size
history = model.fit(
train_generator,
steps_per_epoch=train_step_size,
validation_data=validation_generator,
validation_steps=valid_step_size,
epochs=epochs,
verbose=1,
callbacks=[checkpoint]#, early_stopping]
)
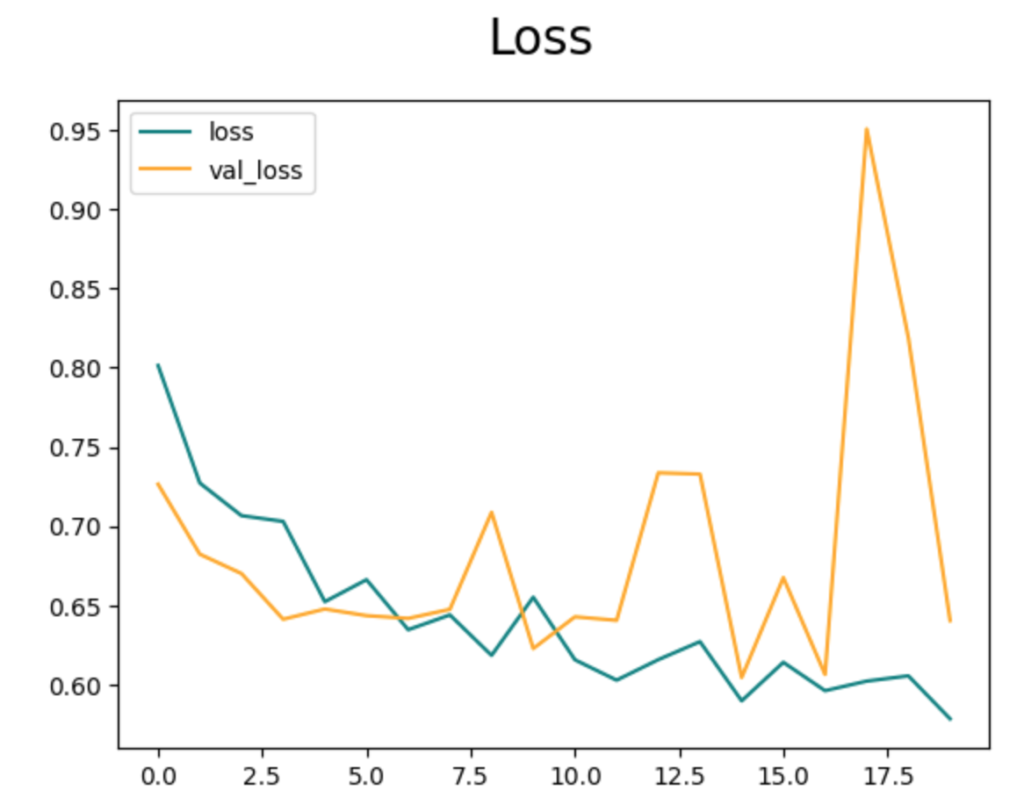
fig = plt.figure()
plt.plot(history.history['loss'], color='teal', label='loss')
plt.plot(history.history['val_loss'], color='orange', label='val_loss')
fig.suptitle('Loss', fontsize=20)
plt.legend(loc="upper left")
plt.show()
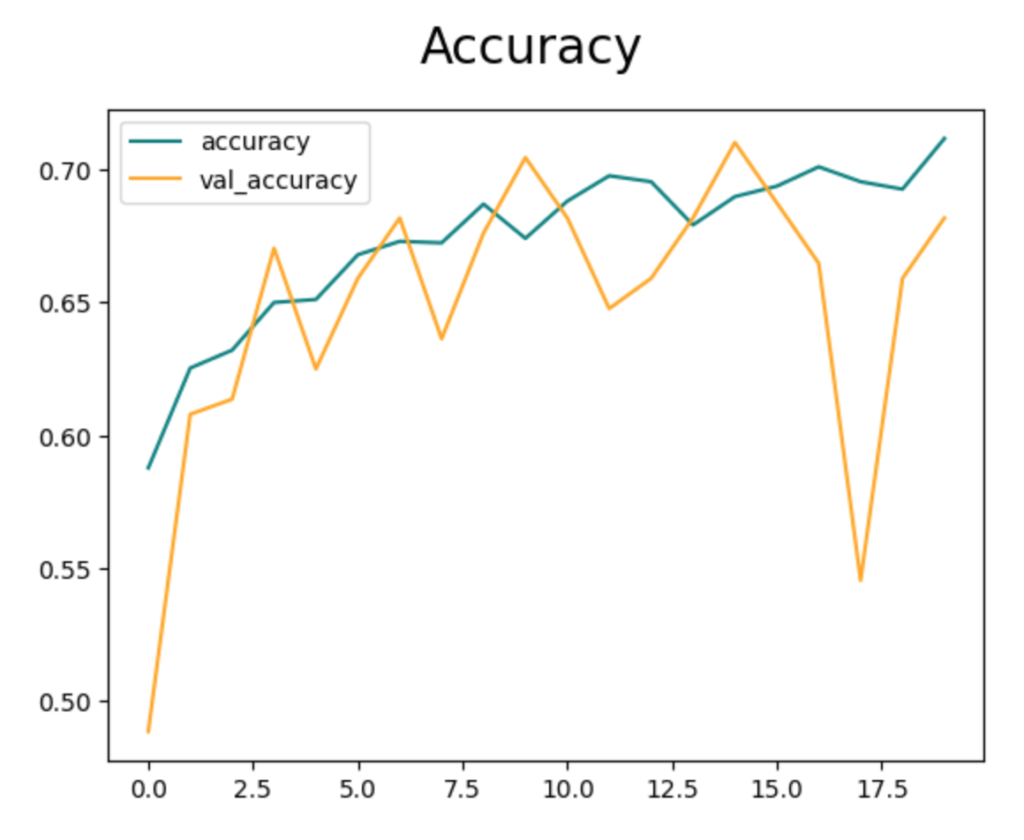
fig = plt.figure()
plt.plot(history.history['accuracy'], color='teal', label='accuracy')
plt.plot(history.history['val_accuracy'], color='orange', label='val_accuracy')
fig.suptitle('Accuracy', fontsize=20)
plt.legend(loc="upper left")
plt.show()
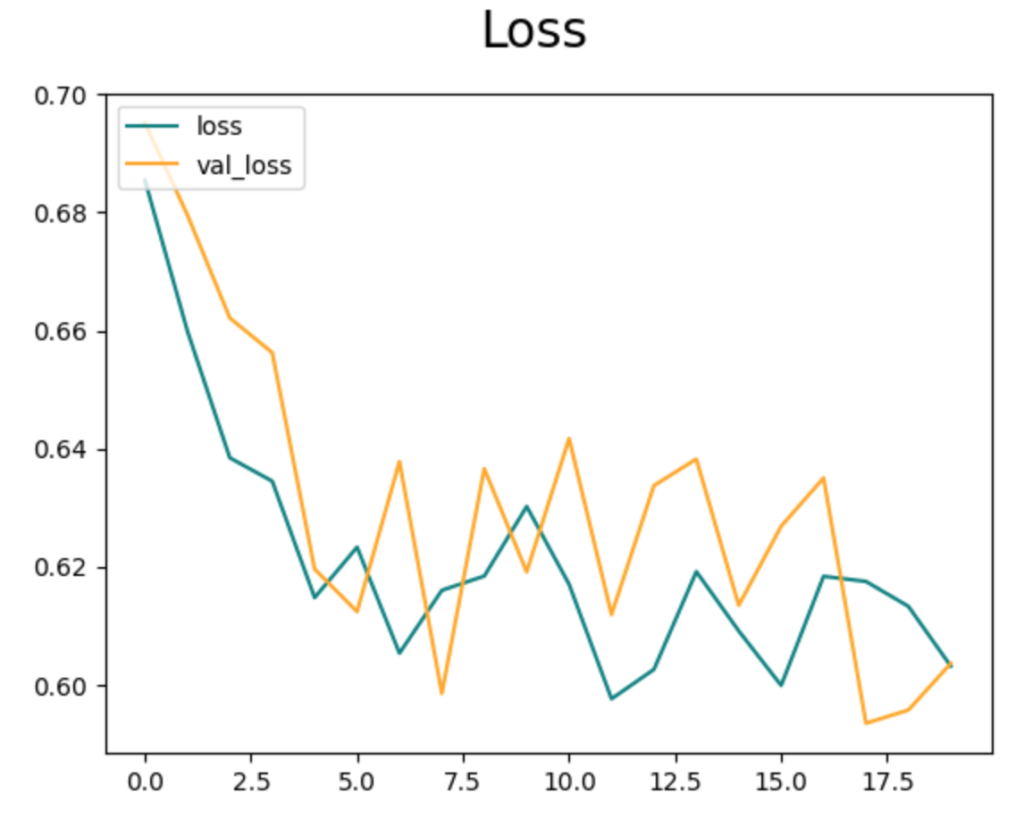
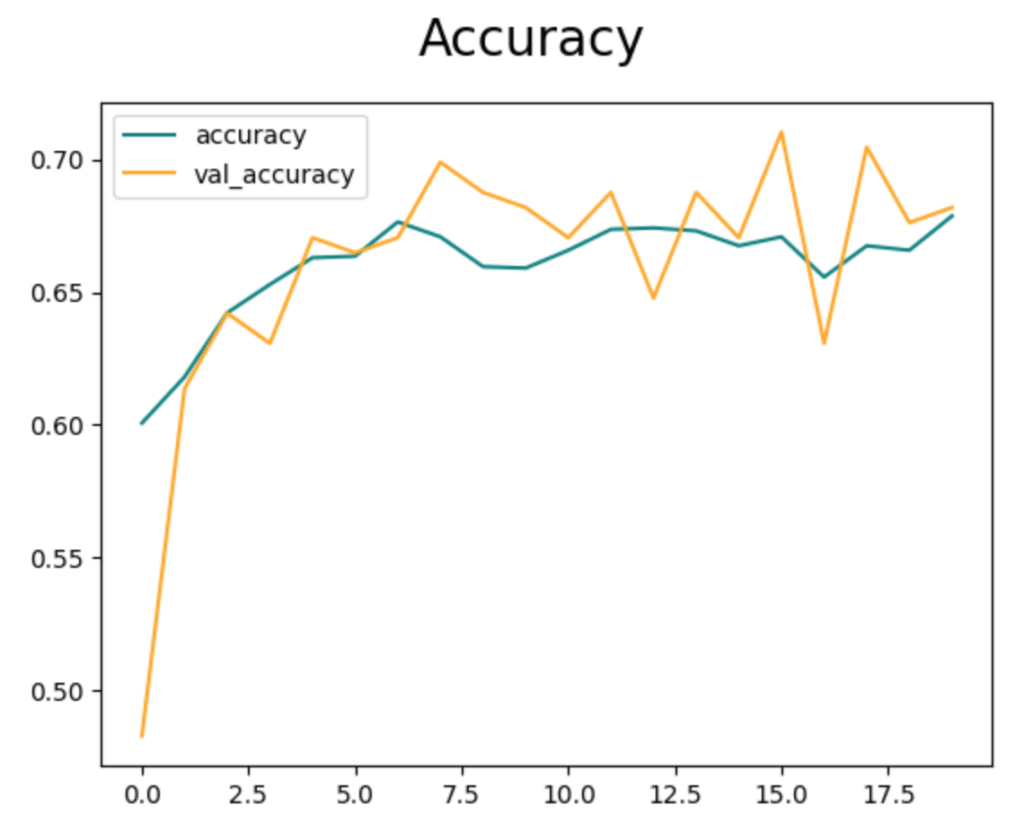
結果を見ると、正解率が0.7前後まで学習できていることがわかります。
追加したレイヤーに加えて一部のレイヤーを学習に加える場合は、以下のようにします。
プログラム中のハイライトの部分が、異なる部分です。
例では、出力付近の14層を学習対象とします(trainable=True)
また、学習率を下げて1e-5にしています。
学習対象の層を増やした場合、学習率が大きすぎると学習が安定しませんでしたのでlrを調整する必要があります
checkpoint = ModelCheckpoint(
filepath = os.path.join(
model_dir,
'model_{epoch:02d}.hdf5'
),
save_best_only=True
)
input_tensor = Input(shape=(img_h,img_w,3))
base_model = ResNet50(
weights='imagenet',
include_top=False,
input_tensor=input_tensor,
)
base_model.trainable = False
x = GlobalAveragePooling2D(name="avg_pool")(base_model.output)
x = BatchNormalization()(x)
top_dropout_rate = 0.2
x = Dropout(top_dropout_rate, name="top_dropout")(x)
output_tensor = Dense(2,activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output_tensor)
for l in model.layers[-14:]:
l.trainable = True
optimizer = keras.optimizers.Adam(learning_rate=1e-5)
model.compile(optimizer=optimizer,
loss="categorical_crossentropy",
metrics=['accuracy'])
model.summary()
学習する層を増やしてもそれほど結果は変化せず、むしろ検証データで乱れが大きくなりました。
おそらく、事前学習で利用しているデータセット(imagenet)には犬猫のデータが多数含まれていて既に特徴を学習済みだったので、resnet50のCNN層を学習しても精度が大きく変化しなかったと考えられます。
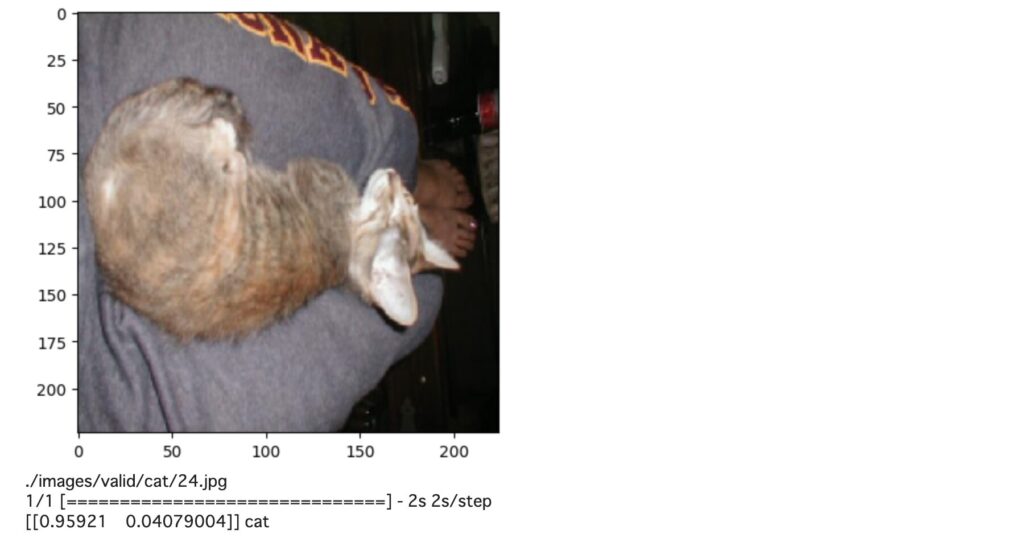
推論のコードです。このコードでは、modelフォルダに格納されたモデルを読み込んで(load_model)、推論を行なっています。
model_name = sorted(glob.glob("./model/*"))[-1]
print(model_name)
from keras.models import load_model
from keras.preprocessing.image import load_img, img_to_array
import numpy as np
import glob
import matplotlib.pyplot as plt
#test and model dir
test_dir = './images/valid'
model_dir = './model'
#num samples
test_samples = glob.glob(test_dir + '/*/2?.jpg')
print(test_samples)
#img size
img_w, img_h = 224,224
###model###
model = load_model(model_name)
for file in test_samples:
img = load_img(file,color_mode='rgb',target_size=(img_h,img_w))
img = img_to_array(img)/255.0
plt.imshow(img)
plt.show()
img = np.expand_dims(img,axis=0)
print(file)
predict = model.predict(img)
print(predict, classes[np.argmax(predict)])
print("\n\n")結果を見ると、少し認識ミスがあるようです。
PyTorchを使う前は、Kerasを使っていた時期が少しだけありました。ただ、その頃からは使い方がかなり変わっているという印象です。
Kerasは以前から直感的でわかりやすかったですが、その頃と比べても簡単に使えるようになっている気がします(メリット)。
一方、エラーやトラブルが発生した場合の原因を調べるのがPyTorchと比べて大変でした(デメリット)。おそらく、PyTorchと比較して処理がライブラリに隠蔽されているため、エラーが発生した場合、どこで発生したのかわかりにくくなっているのだと思います。慣れの問題もあるかもしれませんが、デバッグで該当箇所がわからずにかなり手間取りました。
今回、Kerasを使った学習にチャレンジするにあたって、Pytorchで犬猫分類をする記事を同じようにやろうとしたのですが、検証データに対する精度が全然出ずにあきらめました。
原因は結局不明なままですが、データセットを大規模なものに変えたら学習できたので、100枚程度のデータだと訓練データに過学習してしまったのでは無いかと想像しますが、原因をきちんと特定することができませんでした。
PyTorchと比較して、Kerasは処理がブラックボックス化されています。ブラックボックス化されていることが簡単さにつながっているのですが、逆にトラブル時には原因を調べるのが難しくする原因にもなっていると思います。
このあたりのバランスは、個人的にはPyTorchの方が良いと感じます。
今回の記事程度の学習コードなら、サクッと書けると思ったのですが、「学習が安定しない」という問題にぶつかって、2日ほど試行錯誤しました。
慣れもあるとは思いますが、なんとなくPytorchの方がトラブルが発生した場合は楽な印象を受けました。
Kerasで、犬猫判別を書いてみました。PytorchとKerasのどちらが良いかと言われると、私はPyTorchかなと思います。まぁ、最近はモデルのコンバートも簡単にできるようになってきたので、好きな方を使えばよいと思います。
実用上、どちらが有利・不利といったことはあまり無い気もします
ただ、最新のモデルのコードを読みたいならPyTorchをお勧めします。最先端のモデルのコードはPyTorchの方が圧倒的に多いです。