
PythonでPandasを活用して列データを行に集約する方法(shift, groupby)
Aru
Aru's テクログ(Aruaru0)
Sentence Transformerは、文章をベクトル表現(埋め込み表現)に変換するものです。これを使うことで、文章間の意味合いの比較が可能となります。本記事では、Sentence Transformersを使って、2つの文書間の類似度を計算するて手順について詳しく解説します。
Sentence Transformersは、文章を埋め込み表現(ベクトル)に変換するものです。Sentence Transformersを使うと、文章を512次元といった数値(ベクトル)に変換することが可能になります。
このベクトルは、文章の意味合い的なものをベクトル化したものとなり、ベクトル間の距離で文章が似ているかどうかを調べることができます。
Sentence Transformersを使うことで、以下のようことを行うことが可能となります。
この記事では、Sentence Transformersを使って、文章をベクトル化し、類似度をチェックしてみます。
単語の埋め込みベクトルを計算するものとしてWord2vecがあります。こちらについては以下の記事を参考にしてください。

文章のベクトル化とは、入力された文章をn次元のベクトルで表現することです。
例えば、2次元のベクトルで表現できたとすると、文章は2次元のグラフの中のある点として表すことができるようになります。
下図は、3つの文章が2次元のベクトルで表現された場合のイメージ図です。この図では、文章1と文章3の距離が近いので、文章1と文章2より、文章1と文章3の方が類似度が高いと考えることが可能です。

このように、文章を(適切に)ベクトル化できれば、文章の類似度を計算することができるようになります。

単語をベクトル化するword2vecというものがありますが、それを文章に拡張したものだと考えるとわかりやすいです。
この変換を行うのがSentence Transformerです。これらのモデルでは、事前に大規模なコーパスを使って学習した重みが提供されているので、新たに学習することなく利用することも可能です(ファインチューニングすることも可能です)。
実際には、Sentence Transformerでは、2次元ではなく、512次元や1024次元といった高次元への変換が行われます。
Sentence Transformersはpipを使ってインストール可能です。
pip install sentence_transformersSentence Transformersを利用するには、学習済みのモデルを読み込む必要があります。以下のコードは、マルチリンガルなモデルの1つであるsentence-transformers/distiluse-base-multilingual-cased-v2を読み込んで利用する例になります。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/distiluse-base-multilingual-cased-v2')モデルはhugging faceのmodelsからsimilarityでタスク検索することで見つけることが可能です。今回は上記のモデルを利用していますが、目的に合わせてモデルを選べば良いと思います。
手っ取り早く例文を作成するために、以下のプロンプトを利用してChat-GPTで例文を作成しました。
10ワードほどの英文を適当に作成して、以下のフォーマットで出力してください
sentences = [
"1つ目の英文",
"2つ目の英文",
:
]出力をPythonコードに貼り付けて完成です。
sentences = [
"Just chilling with some tunes and a good book.",
"Thinking about grabbing a coffee with friends later.",
"Stoked about the new movie coming out this weekend!",
"Feeling pumped for the upcoming road trip with the crew.",
"Craving some delicious pizza for dinner tonight.",
"Can't wait to hit the beach and catch some waves tomorrow.",
"Totally forgot about that assignment due tomorrow, oops!",
"Got lost in the world of video games for hours yesterday.",
"Finally finished binge-watching that new series on Netflix.",
"Feeling like a lazy couch potato today, no regrets."
]model.encodeを呼び出すことで、文章をベクトル化することができます。なお、リスト形式で複数の文章を渡した場合は、全ての文章がベクトル化されます。
10個の文章を入力したので、512次元のベクトルが10個出力(10,512)されました。
embeddings = model.encode(sentences)
print(embeddings.shape)
# (10, 512)ここから類似度を計算します。なお、類似度の計算にはコサイン類似度を使います。これは、sklearnのcosine_similarityを使うことで可能です。
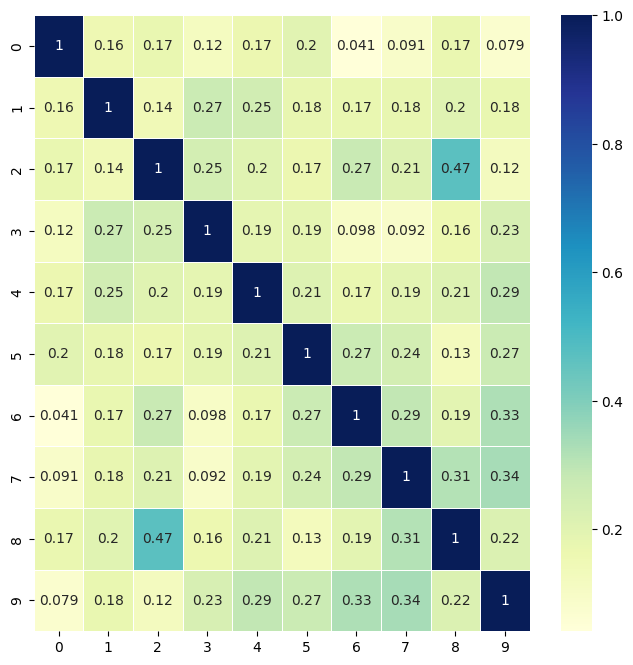
以下は、コサイン類似度を計算して、ヒートマップ表示する例です。
import numpy as np
import seaborn as sns
import matplotlib.pylab as plt
from sklearn.metrics.pairwise import cosine_similarity
pairwise = cosine_similarity(embeddings)
plt.figure(figsize = (8,8))
ax = sns.heatmap(pairwise, linewidth=0.5, annot=True, cmap="YlGnBu")
plt.show()実行すると以下の結果を得ることができます。自分同士(同じ文章)の類似度は1で、類似度が小さい文章間は、小さな値になっていることがわかります。
以下、2つの文章間の距離を計算する例です。
同じ内容の文章の日本語と英語の類似度の比較です。約0.899とかなり高い類似度になっています。
sentences = ["明日は晴れますか? いいえ、明日は雨です。", "Will it be sunny tomorrow? No, it will rain tomorrow."]
embeddings = model.encode(sentences)
x = embeddings[0]
y = embeddings[1]
cosine_similarity(x.reshape(1, -1), y.reshape(1, -1))
# array([[0.898783]], dtype=float32)日本語と英語で異なる内容の比較です。片方は晴れ、片方は雨です。先ほどより類似度は下がっています(0.773)が、どちらも天気に関する内容のためか類似度は高いままです。
sentences = ["明日は晴れますか? はい、明日は晴れです。", "Will it be sunny tomorrow? No, it will rain tomorrow."]
embeddings = model.encode(sentences)
x = embeddings[0]
y = embeddings[1]
cosine_similarity(x.reshape(1, -1), y.reshape(1, -1))
# array([[0.77278]], dtype=float32)試しに、日本語同士で晴れと雨で文章の類似度を計算した結果が以下になります。やはり、天気に関する内容なため、類似度は高いです。
sentences = ["明日は晴れますか? はい、明日は晴れです。", "明日は晴れますか? いいえ、明日は雨です。"]
embeddings = model.encode(sentences)
x = embeddings[0]
y = embeddings[1]
cosine_similarity(x.reshape(1, -1), y.reshape(1, -1))
# array([[0.8550335]], dtype=float32)最後に、英語の文章をGoogle Translate APIを使って日本語に翻訳し、類似度を計算してみます。
googletransの使い方については、以下の記事を参照してください。

英文には先ほど作成したsentencesを利用します。
from googletrans import Translator
translator = Translator()
all = []
for sentence_en in sentences:
sentence_ja = translator.translate(text=sentence_en, dest="ja").text
emb_en = model.encode(sentence_en)
emb_ja = model.encode(sentence_ja)
all.append(sentence_en)
all.append(sentence_ja)
print("-"*100)
print("English: ", sentence_en)
print("Japanese: ", sentence_ja)
print("cosine_similarity", cosine_similarity(emb_en.reshape(1, -1), emb_ja.reshape(1, -1)))以下が結果です。
----------------------------------------------------------------------------------------------------
English: Just chilling with some tunes and a good book.
Japanese: いくつかの曲と良い本で冷えているだけです。
cosine_similarity [[0.82612586]]
----------------------------------------------------------------------------------------------------
English: Thinking about grabbing a coffee with friends later.
Japanese: 後で友達とコーヒーをつかむことを考えています。
cosine_similarity [[0.8995351]]
----------------------------------------------------------------------------------------------------
English: Stoked about the new movie coming out this weekend!
Japanese: 今週末にリリースされる新しい映画について興奮しました!
cosine_similarity [[0.93231857]]
----------------------------------------------------------------------------------------------------
English: Feeling pumped for the upcoming road trip with the crew.
Japanese: 乗組員との今後のロードトリップのために興奮していると感じました。
cosine_similarity [[0.686803]]
----------------------------------------------------------------------------------------------------
English: Craving some delicious pizza for dinner tonight.
Japanese: 今夜の夕食においしいピザを渇望しています。
cosine_similarity [[0.8589651]]
----------------------------------------------------------------------------------------------------
English: Can't wait to hit the beach and catch some waves tomorrow.
Japanese: 明日ビーチにぶつかり、いくつかの波をキャッチするのが待ちきれません。
cosine_similarity [[0.9197008]]
----------------------------------------------------------------------------------------------------
English: Totally forgot about that assignment due tomorrow, oops!
Japanese: 明日はその割り当てを完全に忘れていました、おっと!
cosine_similarity [[0.720348]]
----------------------------------------------------------------------------------------------------
English: Got lost in the world of video games for hours yesterday.
Japanese: 昨日、ビデオゲームの世界で何時間も迷子になりました。
cosine_similarity [[0.87743104]]
----------------------------------------------------------------------------------------------------
English: Finally finished binge-watching that new series on Netflix.
Japanese: 最終的に、Netflixでその新しいシリーズを視聴しました。
cosine_similarity [[0.8689935]]
----------------------------------------------------------------------------------------------------
English: Feeling like a lazy couch potato today, no regrets.
Japanese: 今日は怠zyなカウチポテトのように感じて、後悔はありません。
cosine_similarity [[0.77211726]]最後にヒートマップにしてみます。
embeddings = model.encode(all)
pairwise = cosine_similarity(embeddings)
plt.figure(figsize = (12,12))
ax = sns.heatmap(pairwise, linewidth=0.5, annot=True, cmap="YlGnBu")
plt.show()0番と1番、2番と3番、4番と5番というように2つずつが「同じ文書の英語と日本語翻訳」のペアになっています。ヒートマップを見ると、2つずつ類似度が高く(青く)なっているように見えます。つまり、英文と日本語訳の意味合いが似ているときちんと計算できていることがわかります。
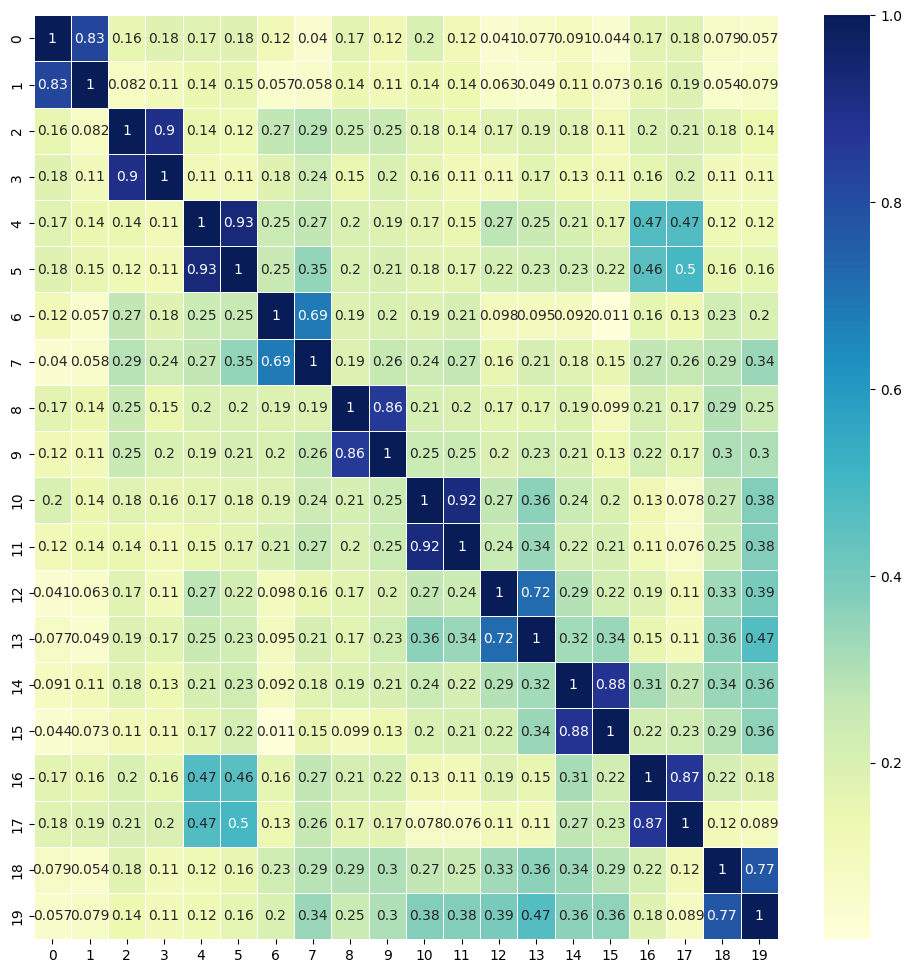
ところで、「4番と5番のペアと16番と17番のペアの類似度が若干高め」です。文章の内容をチェックすると、以下の2つの文章でした(英文側)。片方は映画に関する内容、片方はNetflixに関する内容でした。確かに少し類似している文章です。
Sentence Transformersを使って文章の類似度をチェックしてみました。文章のクラスタリングや類似度チェックなどいろいろな応用が考えられそうです。



