
Category Encodersでカテゴリ変数を簡単に数値化する方法【pandas】
Aru
Aru's テクログ(Aruaru0)

この記事では、PyTorchとFaceNetを使って1対1の顔認証システムを手軽に構築する方法を解説します。FaceNetを利用することで、非常に簡単に顔認証機能を実装することが可能です。本記事では、実際のコードを交えながら、初めて顔認証に取り組む方にもわかりやすいように解説しています。
facenet-pytorchは、PyTorchを使用した顔認識(Face Recognition)ライブラリです。
このライブラリを使うことで、以下の処理を行うことが可能です。
つまり、入力された画像から顔を抽出し、特徴量を計算する部分までをこのライブラリだけで行うことが可能です。
また、学習済みモデルも提供されているので、とりあえず学習なしで顔特徴量の抽出を行うことが可能です。
Github: https://github.com/timesler/facenet-pytorch
顔認証には、1:1認証と1:N認証の2種類があります。
1対1認証とは、照合する本人の特徴ベクトルとの比較を行う方式です。特定の人物との照合だけを行うため、照合する処理が軽くなります。
一方、1対N認証は、登録されている多数の特徴ベクトルの中から合致する1人を選ぶという方式です。多数の人数との照合が必要となるため、処理が重くなります。
今回は1:1認証をやってみます。
1対Nの顔認証については以下の記事を参考にしてください。

今回実装したコードはこちらにあります。「Open in Colab」をクリックすると、Google Colabで実行できます。
必要なパッケージをインストールします。ノートブックの場合は!をつけてセルを実行することでpipコマンドを実行できます。
!pip install facenet_pytorch今回のコードで必要となるライブラリをインポートします。
from sklearn.datasets import fetch_lfw_pairs
from facenet_pytorch import InceptionResnetV1
from torchvision.transforms.functional import resize
import matplotlib.pyplot as plt
import numpy as np
import torch
import random
from tqdm.notebook import tqdm
from sklearn.metrics import roc_curve, roc_auc_score, precision_recall_curve顔画像データセットを読み込みます。今回は、scikit-learnのlws_pairsデータセットを利用します。
このデータセットは、2つの顔画像がペアになったデータセットで、2つの画像が同一人物である場合は「1」、違う人物である場合は「0」のラベルが付けられています。
今回は、1:1の顔認証を行うのでこのデータセットを選びました。
lfw_pairs_train = fetch_lfw_pairs(subset='train', color=True)
print(lfw_pairs_train.pairs.shape)
#(2200, 2, 62, 47, 3)facenetを初期化します。
今回利用する画像セットでは、顔部分があらかじめ切り出されているので、顔切り出しは必要ありません。
facenetの顔切り出しの機能は利用せずに、「顔画像→特徴ベクトルへの変換」だけを行います。
device = "cuda" if torch.cuda.is_available() else "cpu"
resnet = InceptionResnetV1(pretrained='vggface2').to(device).eval()
顔切り出しを行う場合は、facenetのMTCNNを利用します。MTCNNの使い方については、記事の後半の「Google ColabでWebカメラから入力して1:1認証」を参照してください
プログラムでは、random.randm()<0.99の場合は画像をスキップするようにしています。結果ランダムに約1%の画像が処理されることになります。
プログラムの流れは、以下の通りです。
コサイン類似度は以下の式になります。
$$
\cos(\theta) = \frac{vec0 \cdot vec1}{\| vec0 \| \| vec1 \|}
$$
facenetから出力される特徴量は、大きさが1になるように正規化されている($\| vec0 \| = 1$, $\| vec1 \| = 1$)ので、内積=コサイン類似度になります。
for img, label in zip(lfw_pairs_train.pairs, lfw_pairs_train.target):
if random.random() < 0.99: continue
img0 = img[0]
img1 = img[1]
fig = plt.figure(figsize=(4, 2))
fig.add_subplot(1, 2, 1)
plt.imshow(img0)
fig.add_subplot(1, 2, 2)
plt.imshow(img1)
img0 = torch.tensor(img0).permute(2, 0, 1)
img1 = torch.tensor(img1).permute(2, 0, 1)
img0 = resize(img0, size = (160, 160))
img1 = resize(img1, size = (160, 160))
with torch.no_grad():
vec0 = resnet(img0.unsqueeze(0).to(device))[0].detach().cpu()
vec1 = resnet(img1.unsqueeze(0).to(device))[0].detach().cpu()
score = torch.dot(vec0, vec1)
print(f"Two image is {lfw_pairs_train.target_names[label]}, score = {score}")
plt.show()
同一人物の場合は「Two image is Same person」、異なる人物の場合は「Two image is Different persons」と表示し、コサイン類似度をscoreとして表示しています。結果を見ると、同一人物はスコアが高く、別人の場合はスコアが低くなっているようです。


すべてのデータに対して、スコアを計算し正解率を求めてみます。
まず、すべての画像に対してコサイン類似度を求めます。
scores = []
with tqdm(total=len(lfw_pairs_train.pairs)) as pbar:
for img, label in zip(lfw_pairs_train.pairs, lfw_pairs_train.target):
img0 = img[0]
img1 = img[1]
img0 = torch.tensor(img0).permute(2, 0, 1)
img1 = torch.tensor(img1).permute(2, 0, 1)
img0 = resize(img0, size = (160, 160))
img1 = resize(img1, size = (160, 160))
with torch.no_grad():
vec0 = resnet(img0.unsqueeze(0).to(device))[0].detach().cpu()
vec1 = resnet(img1.unsqueeze(0).to(device))[0].detach().cpu()
score = torch.dot(vec0, vec1)
scores.append(score)
pbar.update(1)
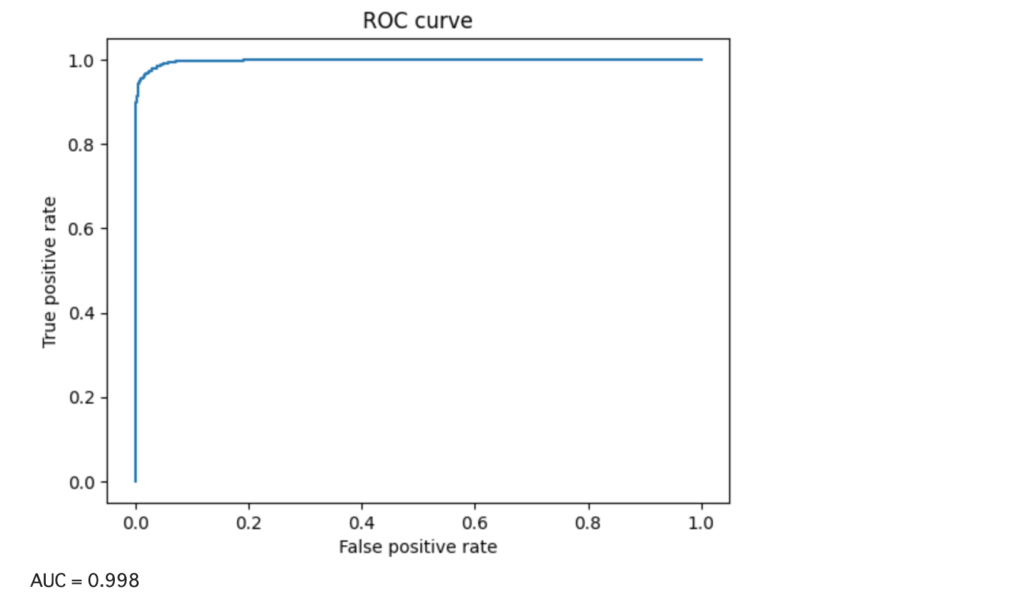
ROC曲線を作成し、ROC-AUCを求めてみます。
ROC曲線とは?
ROC曲線は、二値分類器の性能を評価するためのグラフで、横軸に偽陽性率(FPR)、縦軸に真陽性率(TPR)をプロットしたものです。TPRは、正のクラスの正しい分類率を示し、FPRは負のクラスを誤って正のクラスとして分類する割合を示します。ROC曲線は、ROC曲線を使う個とで、分類器の性能を可視化することができます。また、曲線下面積(ROC AUC)は総合的な性能を評価します。ROC-AUCが高いほど分類器の性能が良く、1に近いほど理想的です。
コードは以下になります。
(np.array(scores)+1)/2は、コサイン類似度の範囲が-1~1なので、これを0~1に変換しています。
y_true = lfw_pairs_train.target
y_score = (np.array(scores)+1)/2 # -1~1を0~1に変換
fpr, tpr, threshold = roc_curve(y_true, y_score, pos_label=1)
plt.plot(fpr, tpr)
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.show()
print(f"AUC = {roc_auc_score(y_true, y_score):.3f}")結果は以下になります。AUC=0.998とかなり高い結果になりました。
正解率を求めます。正解率を求めるには、スコアがいくつから同一人物と判断するかの閾値を決めなければなりません。
今回は、2項分類:しきい値を自動で計算するという記事を参考にして、閾値を自動計算しました。
# https://qiita.com/kotai2003/items/3ee12b776ee205b7db42を参考に作成
precision, recall, threshold_from_pr = precision_recall_curve(y_true, y_score)
a = 2* precision * recall
b = precision + recall
f1 = np.divide(a,b,out=np.zeros_like(a), where=b!=0)
idx_opt = np.argmax(f1)
threshold_opt = threshold_from_pr[idx_opt]
print(f"Threshold = {threshold_opt:.3f}")計算された閾値は0.713でした。
閾値が決まれば、正解率の計算は以下になります。
acc = sum((y_score > threshold_opt)&(y_true == 1)|(y_score <= threshold_opt)&(y_true == 0))/len(y_true)
print(f"Accuracy = {acc:.3f}")出力結果
Accuracy = 0.975結果は、0.975となりました。
高そうに見えますが、100回に3回間違う可能性があります。
実用を考えた場合、例えばロック解除などに使う場合は、閾値は慎重に設定すべきだと思います。
Google Colabでカメラ入力させたい場合は、上部メニューの「ツール」→「コマンドパレット」→「コード/スニペットパネル表示」を選択してスニペットを表示させます。
ここでCamera Captureを選択して挿入をクリックすると、カメラからのキャプチャコードが挿入されます。WebカメラをPCにつけている場合は、実行することでカメラからのキャプチャが可能です。
以下が挿入されるコードです。
from IPython.display import display, Javascript
from google.colab.output import eval_js
from base64 import b64decode
def take_photo(filename='photo.jpg', quality=0.8):
js = Javascript('''
async function takePhoto(quality) {
const div = document.createElement('div');
const capture = document.createElement('button');
capture.textContent = 'Capture';
div.appendChild(capture);
const video = document.createElement('video');
video.style.display = 'block';
const stream = await navigator.mediaDevices.getUserMedia({video: true});
document.body.appendChild(div);
div.appendChild(video);
video.srcObject = stream;
await video.play();
// Resize the output to fit the video element.
google.colab.output.setIframeHeight(document.documentElement.scrollHeight, true);
// Wait for Capture to be clicked.
await new Promise((resolve) => capture.onclick = resolve);
const canvas = document.createElement('canvas');
canvas.width = video.videoWidth;
canvas.height = video.videoHeight;
canvas.getContext('2d').drawImage(video, 0, 0);
stream.getVideoTracks()[0].stop();
div.remove();
return canvas.toDataURL('image/jpeg', quality);
}
''')
display(js)
data = eval_js('takePhoto({})'.format(quality))
binary = b64decode(data.split(',')[1])
with open(filename, 'wb') as f:
f.write(binary)
return filename実際にキャプチャするコードは以下です。
from IPython.display import Image
try:
filename = take_photo()
print('Saved to {}'.format(filename))
# Show the image which was just taken.
display(Image(filename))
except Exception as err:
# Errors will be thrown if the user does not have a webcam or if they do not
# grant the page permission to access it.
print(str(err))この機能を使って1:1認証を行ってみます。上記のプログラムを実行するとカメラがき起動します。キャプチャボタンを押すとphoto.jpgに画像が保存されます。
1度目に撮影した画像をリファレンス画像とします。
下記のコードで画像から顔を切り出し(mtcnn)、特徴量を抽出(resnet)しています。
import PIL.Image as Image
from facenet_pytorch import InceptionResnetV1, MTCNN
device = "cuda" if torch.cuda.is_available() else "cpu"
mtcnn = MTCNN(image_size=160, margin=10, device=device)
resnet = InceptionResnetV1(pretrained='vggface2').to(device).eval()
filename = 'photo.jpg'
img = Image.open(filename)
img_cropped = mtcnn(img, save_path=filename)
ref = resnet(img_cropped.unsqueeze(0).to(device))[0].detach().cpu()これで、refに参照画像の特徴ベクトルが記録されました。
次に、認証したい画像を撮影します。下記のコードを実行してキャプチャするとcheck.jpgに画像が保存されます。
from IPython.display import Image
try:
filename = take_photo("check.jpg")
print('Saved to {}'.format(filename))
# Show the image which was just taken.
display(Image(filename))
except Exception as err:
# Errors will be thrown if the user does not have a webcam or if they do not
# grant the page permission to access it.
print(str(err))画像を読み込んで特徴ベクトルを抽出し(vec)、参照ベクトル(ref)とのコサイン類似度を計算します。
import PIL.Image as Image
filename = 'check.jpg'
img = Image.open(filename)
img_cropped = mtcnn(img, save_path=filename)
vec = resnet(img_cropped.unsqueeze(0).to(device))[0].detach().cpu()
score = torch.dot(ref, vec)
print(score)何度かチェックしてみましたが、0.75~くらいの値を得ることができました。結構上手く動作するようです。
ローカルの環境でキャプチャする場合は、OpenCVを利用するのが簡単です。
FaceNetを利用して1対1の顔認証にチャンレンジしてみました。実際に使ってみるとかなり簡単に顔認証アプリを作成することができます。
OpenCV+FaceNetで、Webカメラでキャプチャ→顔切り出し→顔認証というアプリも簡単につくることができそうです。



