
LMStudioで外部ツールを呼び出す方法|Tool Use対応モデルの使い方
Aru
Aru's テクログ(Aruaru0)

HP OmniBook 7 Aero 13-bg1010AU(AMD Ryzen™ AI 7 350 /メモリ32GB/SSD 1TB)を購入し、ローカルLLM実行環境である「LMStudio」をインストールして性能を検証してみました。LMStudioはRyzen AIに対応しており、Vulkanを利用したGPUアクセラレーションによって高速な推論が可能です。
本記事では、32GBメモリ環境でQwen-3-30B-A3BおよびGemma-3-12B, 4Bの4bit量子化モデルを実行し、MacBook(Air M2, Pro M4Max)とのベンチマーク比較も行いました。ノートPC単体でのLLM実行性能やRyzen AIの効果に興味がある方の参考になれば幸いです。
Windows環境が必要になったため、持ち運びに適したノートパソコンを新たに購入しました。選定条件としては、重さが1kg前後のモバイルノートであること、十分なメモリを搭載していること、そして価格と性能のバランスが取れていることを重視しました。
最終的に選んだのは、HP OmniBook 7 Aero 13-bg1010AUです。AMD Ryzen™ AI 7 350 、32GBメモリ、1TB SSDという構成で税込159,800円という価格は、コストパフォーマンス的に非常に魅力的でした。
LLM実行環境「LMStudio」は、Ryzen AIでのGPUアクセラレーションがサポートされています。今回はこのノートPC上でLMStudioを使用し、いくつかのローカルLLM(Qwen-3-30B-A3BおよびGemma-3-12B 4bit量子化版)を動かして、性能や実用性を検証してみました。

LMStudioは、ローカル環境で大規模言語モデル(LLM)を手軽に実行できるオープンソースツールです。モデルのダウンロードや起動がGUI上で完結し、細かな設定を必要としない点が特徴です。私は普段MacBook Proをメインマシンとして使用していますが、ローカルLLMを試す際にはLMStudioを重宝しています。
Ryzen AIへの対応については、llama.cppのVulkanバックエンドを利用することで、GPUによるアクセラレーションが可能になっています。
Ryzen AI対応PCを購入しているユーザーは少なくないと思いますが、ローカルLLMを実際に動かしたベンチマーク情報はまだ少ない印象です。そこで今回は、自分の環境でいくつかのモデルを実行し、処理速度を計測してみました。
今回使用したモデルは以下の通りです:

今回のように統合メモリ(ユニファイドメモリ)を活用できる構成であれば、GPUメモリに収まらなくても一部の大規模モデルを「とりあえず動かす」ことが可能です。

GPUとCPUで分担してLLMを動作させることができますが、実行速度はかなり遅くなります。
| モデル名 | モデルサイズ |
| Qwen-3-30B-A3B | 18.63GB |
| Gemma3-12B | 8.15GB |
| Gemma3-4B | 3.34GB |
今回は、比較対象としてMacbook Air(M2, 16GB)とMacbook Pro(M4Max, 128GB)でも計測を行いました。
以下、実行結果です。
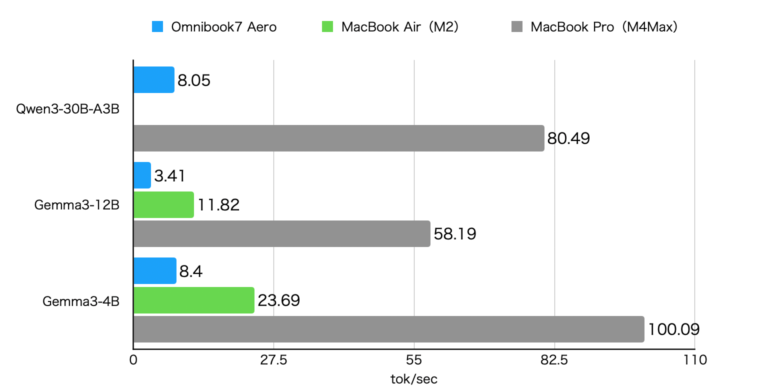
Qwen3-30B-A3BとGemma3-4Bは8トークン/秒で、Gemma3-12Bは3.4トークン/秒でした。Qwen3-30B-A3Bは、MoE構成のモデルで同時にアクティブになるのは3Bなので、4Bモデルとほぼ同じ速度だというのは感覚と一致します。
8トークン/秒は「なんとかつかえるかな?」というレベルの速度ですが、Qwen3-30B-A3Bを推論モードで動かした場合は、普通に1000トークンを超える推論を行うので、回答が出力されるまでかなり待たされます。推論OFF(/no_think)で使うなら使えるといった感じだと思います。
MacBook Airはメモリが16GBしかないのでQwen3-30B-A3Bは動作させることができませんでした。
Omnibook 7 AeroとMacBook Airを比較すると、LLMの実行速度はMacBook Airの方が高速でした。Ryzen AI 7 350は、もう少し速度がでるかと思いましたが思ったより実行速度が伸びませんでした。
なお、MacBook Pro(M4Max)は、他の2つと比較的圧倒的に高速です。80トークン/秒程度になると、普通にクラウドでChatGPTなどを使っているのと遜色ないスピードです。
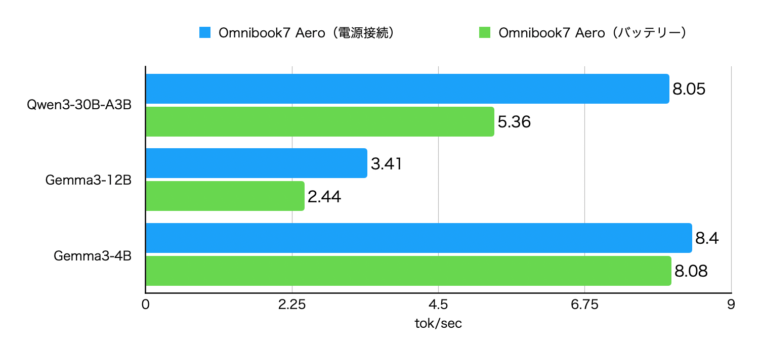
Macbookの場合、電源に接続している状態でもバッテリーで駆動している時でもあまり速度が変化しないので気にしてなかったですが、Omnibook7では差がありましたので計測してみました。
以下が電源接続時とバッテリー駆動時の測定結果です。バッテリー駆動になると70%程度の速度に低下するようです。ただ、Gemma3-4Bはそこまで速度が落ちませんでした。このモデルであればバッテリー駆動時にも利用できそうです。
Omnibook 7 Aero 13のメモリもLPDDR5x-7500MT/sなので、帯域は決して狭くない(デュアルチャネルならMacBook Air(M2)より広い)はずですが、実行速度ではMacbook Airに大幅に負ける結果になりました。これは、llama.cppのValkanサポートがまだまだこなれていないのが理由なのかもしれません(GPU使用率は100%に張り付きませんでした)
なお、Apple SiliconもRyzen AIもLLMの実行ではNPU(MacではNural Engine)は活用されていません。どちらもGPUのみが動いていました。NPUを活用することができるようになったらもう少し快適に動作するかもしれません。
Ryzen AIに期待しましたが、ノートパソコンでローカルでLLMを動かす場合は現状ではMacBookの方が良いという結果になりました。なので、LLMをローカルで動かすことを目的の1つとして購入するなら現状はMacbookかなーと思いました。
AMD Ryzen™ AI 7 350を搭載したHP Omnibook 7 Aero 13で、LMStudioを使ってLLMを動かしてみました。ValkanによるGPU動作に対応しているとはいえ、思ったより速度が出なかったのが残念です。ただ、まだNPUを使っていないので、今後NPUが使われるようになれば変わるかもしれません。



