
手書き文字(MNIST)認識をオリジナルのCNNでやってみる【初級 深層学習講座】
Aru
Aru's テクログ(Aruaru0)

結果は、5137/6712位。ここまで大幅なシェークダウンを経験したのは初めてですが、とりあえず、取り組み内容をまとめました
コードもgithubに置いていますので参考になれば幸いです
定期的にkaggleに参加している。今回はICR(Identifying Age-Related Conditions)に参加したので、取り組み内容などを紹介する。
まず、最初に今回のコンペ、結果として5000位レベルの大幅なシェークダウンを食らいました。ベストモデルも選択できてないないどころか、作ったモデルのうち良いモデルが選べていないという最悪な状態。

ここでは、ICRでの取り組み内容と、大幅なシェークダウンについて考察したいと思います。
上位に入れたら、手法とか細かく解説しようかと思いましたが、全然ダメだったのでさらっと全体の説明だけにしたいと思います。何かの参考になれば幸いです。
ICR Identifying Age-Related Conditionsコンペとは、加齢による疾患があるかないかを判定するものです。与えられるデータは加工がされていて、ラベルを見ただけではどれが年齢で性別かさえわからないようになっています。
また、疾患の種類も隠されているので3つの疾患が一体なんなのかもわかりません。
コンテストとしては面白いけど、事前知識をここまで使わせないで学習モデルを作るのは研究としてはどうなのかなとか思いながら参加しました。
今回のコンペの特徴は、データが少ないこと。その成果参加者も6,712名とかなり多かったです。
LeaderBoardのトップのスコア0.0(ミスが1つもない!)、公開ノートのベストが0.06という結果です。明らかにオーバフィッテング気味です。
ディスカッションでも言われているけど、LBで見えているサンプルは推論しやすいデータだけっぽいです。問題は、見えてない58%のデータですが、見えないデータがLBと似たデータなのか、全然異なるデータ、あるいは、難しいデータが含まれているかが問題です。
難しいデータがなければ、LBのまま順位は決まりそうですし、難しいデータがあれば大きな順位変動が起きて大荒れするかも。
ディスカッションをまとめるとこんな感じの意見でした(荒れる予想が多かった気がします)。
結果として大荒れしたわけですが・・・・
最初に、EDAを作成しました。他の医療コンペもそうでしたが、どの列が何のデータなのかわからないように加工しています。
コンペをゲームとして考えると面白いですが、社会の役に立つアルゴリズムを本気で考えようとしているのかちょっと疑問に感じます。
箱ひげ図、分布の違いなどチェックしたが、なんとも言えない状態。ディスカッションをみると、イプシロンが結構使えるっぽい。
実際に見てみると、期間によってクラス0とクラス1の割合が違うことを発見。テストデータは、訓練データより後のデータだと書かれているので、イプシロンは採用する方向で決定。
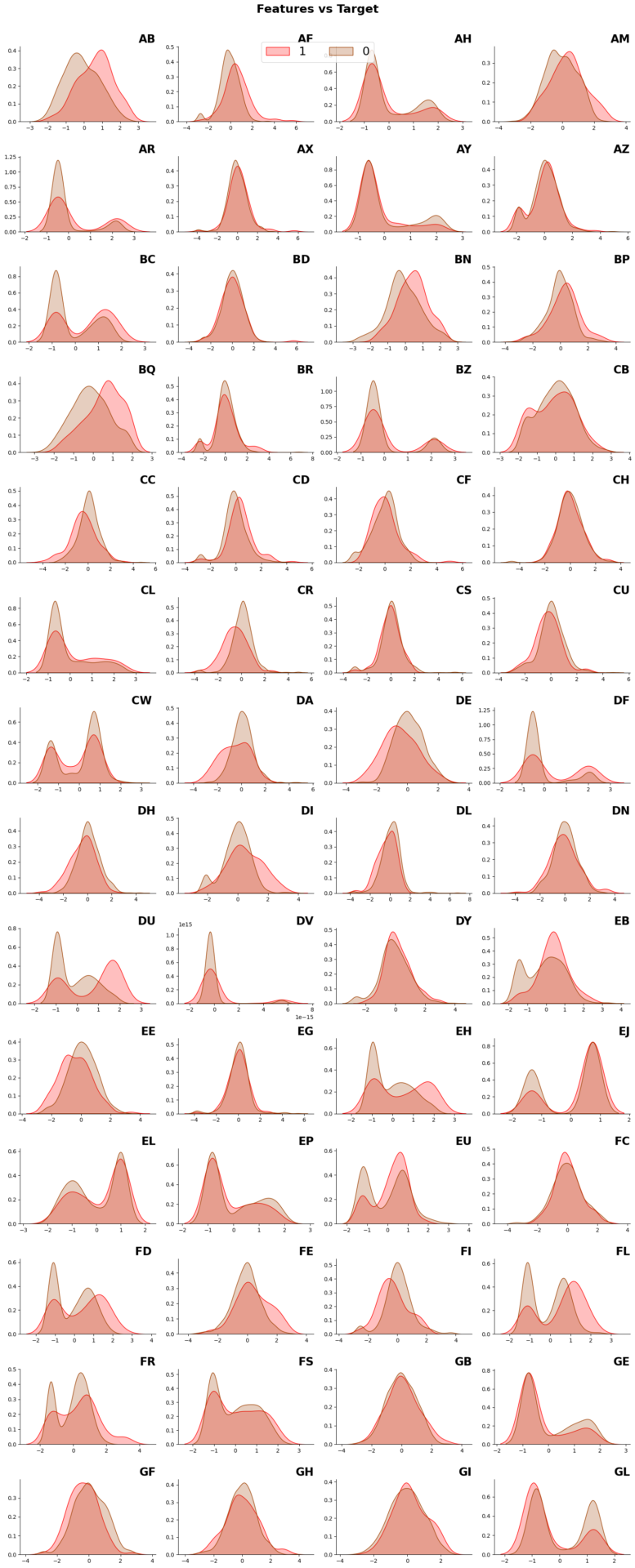
下図はEDAで作成したグラフの1つ。各グラフがデータの列に対応していて、赤い方が疾患のある人、茶色っぽい方が健常者。これを見ると、いくつかのデータでデータの偏りが異なっていることはわかる。
最初にPyCaretを使って、サクッと訓練・推論をしてみました。PyCaretの使い方は以下を参考にしてください。kaggleのノートブックはこちら(推論コードのみ)。学習コードを含むものはGithubに置いています(こちら)。
CVはそれなり、LBは0.25と結構良さそうでした(ちなみに、最終のPBは0.54と、提出した1.88よりかなり良いモデルでした)。
とりあえず、PyCaretの結果を参考にしてモデルを作ることにしました。
PyCaretで行ったモデル比較は以下の通り
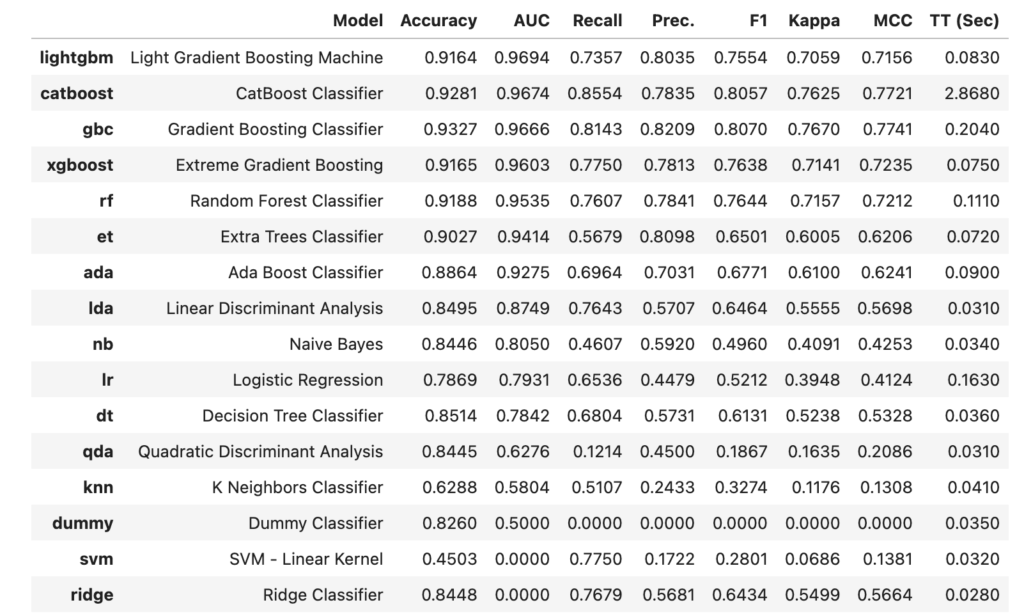
この結果をみると、LightGBM, XGBoost, CatBoostあたりは外せなさそう。
とりあえず、LightGBM, XGBoost, CatBoostは使うことを決定。あと、Boostingではないアルゴリズムとして5番目に来ているRandom Forestも候補として選択。この辺りをアンサンブルすることを考えました。
また、今回のコンペの公開ノートブックではTabPFNというトランスフォーマーベースのモデルが使われていました。調べて見ると面白そうなのでこれも採用。

独自のものとして、NNを追加することにしました。モデルはPyTorchで作成した独自モデル。トライアル的にArcFaceを挟んだモデルとし、出力される特徴量のコサイン距離をKnnで分類するという手法を組み込んでみました。
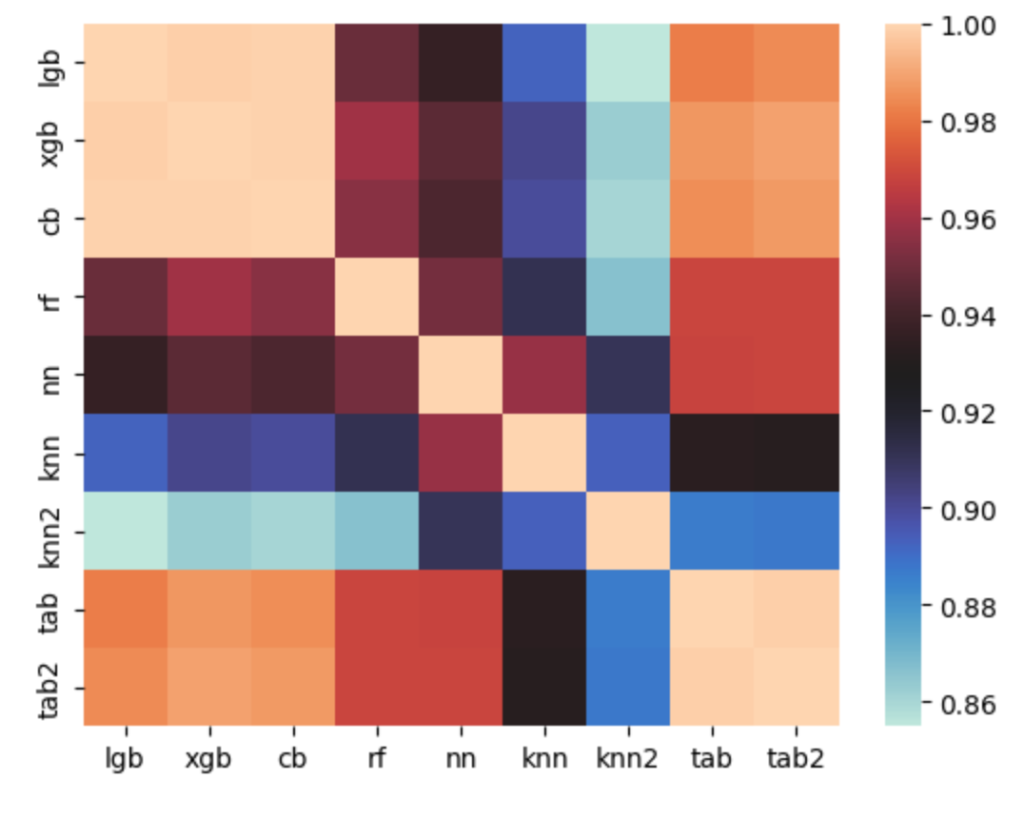
このモデル面白くて、検出率はそこそこだけど、LightGBM, XGBoost, CatBoostとは相関係数が低いというものです。
下図は各モデルの創刊を表したもの、knn, knn2というknnベースとBoostingとのそうかんが低いことがわかります。逆に、LightGBM, XGBoost, CatBoostの相関はかなり高い。似たアルゴリズムなのでそんなものだと思います。
モデルができたので、各モデルのパラメータとアンサンブル(今回は加重平均)のパラメータをOptunaを使って最適化。何度か試行して良さそうなやつを選択しました。
最終のモデルとして、5分割した各FOLDに対するモデルの出力を平均するようにするか、全データで再度フィッティングさせるか悩みましたが、後者を選択。データが少ないので各FOLD間のばらつきが気になった、分割の仕方で結構違うので安定性が気になったというのが大きいです。
全データで再度フィッティングさせると、CVが取れないのでギャンブルになります。今回はギャンブルしました。
前処理でデータ加工したかったのですが、データの意味がわからないので加工する方針も立ちませんでした。なので、ランダムに列を選択して推論するを繰り返して、スコアが良いものを選択するという、結構無茶な方法を取りました。結局、ほとんどの列を利用したモデルの方がスコアが高かったのであまり意味はありませんでしたが、取り組み内容として行ったので参考まで。
チームのデットラインギリギリで知人とチームを組みました。とりあえず、お互いのモデルをアンサンブルです。知人のモデルも、複数モデルの組み合わせ+スタッキングで構造的には似ていますが、パラメータと組み合わせたモデルが違います。
組み合わせるとLBは下がりました(CVは、FOLDの分割とかが異なるので正確に計算できないので割愛)。
最終的には、LBベストと、CVの良いモデルを組み合わせた良さそうなモデルを選択しました。
ちなみに、チームを組む前の私のコードはGitHubのここに置いてあります。
結果は、5137/6712位と惨敗です。一番良いモデルを選択した場合は、668位〜905位のどこかなので、ベストを選んだとしてもスコアが伸びていませんでした。ちなみに、上位をみても、LBから2000位とかアップしているので大荒れだったことがわかります。
「Trust your CV(あなたのスコアを信じろ)」と言われますが、CVを信じて提出したサブでさえ冴えない結果でした。
実は、今回は、かなり荒れることが予想できていたので、運よくあたりを引けたらいいな的な気持ちで参加しました。
題材が簡単だったので、いろいろ試行錯誤できたのは良かったと思います。ただ、どれもうまくハマらなくて結果は出せなかったですが。
荒れるコンテストに出てわかったのは、CV、LBで改善できているかどうか全然感触が掴めないので、荒れそうな場合はあまり深く検討せずに、サクッとサブして運試しするのがよかったかなということです。
スキルアップを目指して新しいことをいろいろ試していたのですが、その結果がLBで見えてこないというのはいまいちでした。。
少し休んで次のコンペに取り組みたいと思います。



