LangChainのFaissを活用した近似最近傍探索の手順を解説
Aru
Aru's テクログ(Aruaru0)

GPU-Benchmarks-on-LLM-InferenceにM4Maxの結果が追加されないので、私の方で実行してみました。M3Maxとどの程度違うのか分かりやすいようにM3Maxのデータを並べて記事にしています。
GPU-Benchmarks-on-LLM-Inference(リンク)にあるLLMのベンチマークをM4Maxで行ってみました。RTX4090などのデータは上記のリンクにありますので、M4Maxと比較するのに役立つかと思います。
特にM4Max搭載のMacBook ProをLLMを動作させる目的で購入検討している方の参考になるかと思います。実際、私自身、LLMと巨大なデータをpandasで処理するために128GB搭載のM4Maxを購入しました。

上記のリンクのコードはそのまま動かなかったのでllama.cppをインストールし、同じモデルをダウンロードしてコマンドラインで実行しました。

ベンチマークに利用されるのはllama 8Bと70Bです。8BはQ4_K_Mとfp16のバージョン。70BはQ4_K_Mのバージョンです。今回購入したM4Maxはメモリが128GBなので、さらに大きなモデルも動作させることはできそうですが、今回はこの3つのモデルだけ実行してみました。
ppはプロンプト処理で、tgはテキスト生成の意味です。また、t/sはトークン/秒です。
今回ベンチマークのために、パフォーマンスを「自動」に変更しましたが、いつも低電力で使っているので「ファン」が久しぶりに回って少し気になりました。
8B Q4モデルは、tgが少しだけ大きい感じでした。
| model | size | params | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | ---------------: |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | pp 512 | 693.32 ± 0.42 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | pp 1024 | 678.04 ± 0.46 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | pp 2048 | 652.33 ± 9.50 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | pp 4096 | 573.09 ± 14.08 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | tg 512 | 48.97 ± 0.17 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | tg 1024 | 50.74 ± 2.02 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | tg 2048 | 49.78 ± 0.01 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | tg 4096 | 44.21 ± 0.01 || model | size | params | test | t/s |
| ------------------------------ | ---------: | ---------: |---------: | ---------------: |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | pp512 | 685.25 ± 14.26 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | pp1024 | 638.83 ± 4.63 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | pp2048 | 621.13 ± 4.20 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | pp4096 | 513.26 ± 31.09 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | tg512 | 54.49 ± 0.84 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | tg1024 | 56.54 ± 1.27 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | tg2048 | 56.06 ± 0.42 |
| llama 8B Q4_K - Medium | 4.58 GiB | 8.03 B | tg4096 | 51.32 ± 0.09 |8B F16もtgが少しだけ大きかったです。
| model | size | params | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | ---------------: |
| llama 8B F16 | 14.96 GiB | 8.03 B | pp 512 | 769.84 ± 1.23 |
| llama 8B F16 | 14.96 GiB | 8.03 B | pp 1024 | 751.49 ± 0.52 |
| llama 8B F16 | 14.96 GiB | 8.03 B | pp 2048 | 695.29 ± 20.23 |
| llama 8B F16 | 14.96 GiB | 8.03 B | pp 4096 | 609.97 ± 15.87 |
| llama 8B F16 | 14.96 GiB | 8.03 B | tg 512 | 22.04 ± 0.24 |
| llama 8B F16 | 14.96 GiB | 8.03 B | tg 1024 | 22.39 ± 0.09 |
| llama 8B F16 | 14.96 GiB | 8.03 B | tg 2048 | 21.86 ± 0.00 |
| llama 8B F16 | 14.96 GiB | 8.03 B | tg 4096 | 20.72 ± 0.00 || model | size | params | test | t/s |
| ------------------------------ | ---------: | ---------: |-----------: |--------------: |
| llama 8B F16 | 14.96 GiB | 8.03 B | pp512 | 691.61 ± 29.85 |
| llama 8B F16 | 14.96 GiB | 8.03 B | pp1024 | 663.42 ± 8.90 |
| llama 8B F16 | 14.96 GiB | 8.03 B | pp2048 | 628.72 ± 18.60 |
| llama 8B F16 | 14.96 GiB | 8.03 B | pp4096 | 590.92 ± 4.80 |
| llama 8B F16 | 14.96 GiB | 8.03 B | tg512 | 28.70 ± 0.13 |
| llama 8B F16 | 14.96 GiB | 8.03 B | tg1024 | 28.23 ± 0.05 |
| llama 8B F16 | 14.96 GiB | 8.03 B | tg2048 | 27.35 ± 0.02 |
| llama 8B F16 | 14.96 GiB | 8.03 B | tg4096 | 25.88 ± 0.03 |70BはM3Maxの方が性能が高いという結果になりました。結構数値は乱れるのかもしれません。
| model | size | params | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | ---------------: |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp 512 | 70.19 ± 2.91 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp 1024 | 62.88 ± 0.13 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp 2048 | 64.09 ± 1.46 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp 4096 | 64.90 ± 0.09 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | tg 512 | 7.65 ± 0.07 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | tg 1024 | 7.53 ± 0.00 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | tg 2048 | 7.20 ± 0.00 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | tg 4096 | 6.58 ± 0.00 || model | size | params | test | t/s |
| ------------------------------ | ---------: | ---------: | ----------: |-------------: |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp512 | 65.87 ± 4.16 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp1024 | 62.82 ± 1.10 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp2048 | 49.78 ± 1.91 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp4096 | 50.77 ± 0.19 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | pp8192 | 47.98 ± 0.12 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | tg512 | 6.15 ± 0.26 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | tg1024 | 6.25 ± 0.01 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | tg2048 | 6.26 ± 0.19 |
| llama 70B Q4_K - Medium | 39.59 GiB | 70.55 B | tg4096 | 6.88 ± 0.15 |以上がベンチマーク結果です。M3Maxの結果とそれほど違わない結果になりました。llama.cppのバージョンが違うのでそのせいかなとか思っています。というのも、他の方のベンチ結果ではもう少し差がある結果が出ているのもあるんですよね。とりあえず、参考になれば幸いです。
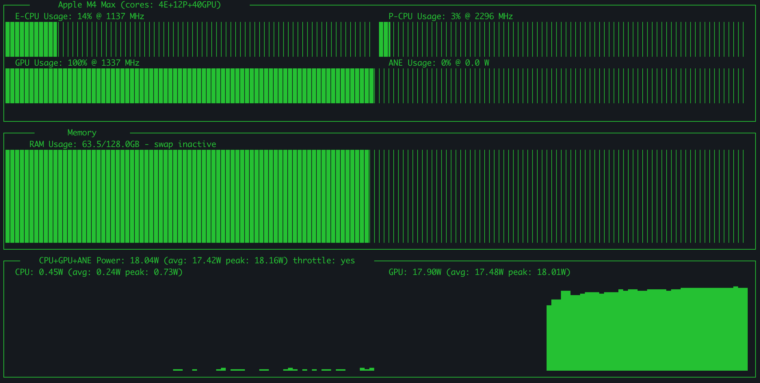
ところで、ベンチマーク実行中はCPUのPコアが全然動いていませんでした。GPUは全力で動いていたのでほぼGPUだけで実行していたようです(下図)。ちなみに、GPU0.45W, GPU17Wとなっていまうすが65WのUSB-Cだと電力不足になったので65W以上の電力消費のようでした。