
大規模言語モデル(LLM)パラメータ「temperature, top_k, top_p」について【初級 深層学習講座】
手書き文字(MNIST)認識をオリジナルのCNNでやってみる【初級 深層学習講座】

Aru
以前の記事で手書き文字認識をPyTorchで実装しましたが、今回はニューラルネットワークのモデルを「畳み込みニューラルネットワーク(CNN)」に変更してゼロから自作してみます。CNNは画像のクラス分類で広く利用されている技術です。一度フルスクラッチから実装すれば、CNN仕組みをしっかり理解する助けになります。本記事では、MINSTデータセットを使って、PyTorchでのCNNの実装方法とその効果を解説します。
あわせて読みたい

PyTorchで手書き文字(MNIST)の認識の実装に挑戦【初級 深層学習講座】
Contents
はじめに
MNISTの手書き数字のデータセットは、「0」〜「9」の数字を手書きした、機械学習ではお馴染みのデータセットです。
ディープラーニングの学習用途で頻繁に利用されているため、データセットを利用する環境がよく整っていることも特徴です。
今回は、このMINSTの手書き文字を識別するCNNモデルをPyTorchで作成して動かしてみたいと思います。
実のところ、普段はTIMM(PyTorch Image Models)などのライブラリに用意されているベースモデルを改変してモデルを作っているので、フルスクラッチでもモデルを作るのは久しぶりです。
とはいえ、自分でモデルを作ると、CNNをより深く理解することができますので一度はやっておくことをお勧めします。
ここでは、PyTorchのコードを使っていますが、紹介するコードはGoogle Colab or Jupyter notebookで動かす前提として書かれています。他の環境の場合は、少し修正が必要かもしれませんので注意してください。
Google Colabで動作するコードはこちらに置いています。活用してください。
ライブラリのインストール
前半のコードは、「手書き文字(MNIST)認識をPyTorchで記述する【初級 深層学習講座】」と同じです。一応、こちらの記事でも改めて掲載しておきます。
あわせて読みたい
PyTorchで手書き文字(MNIST)の認識の実装に挑戦【初級 深層学習講座】
最初に、ライブラリをインポートします。
インポートするのは、torch関連、torchvision, matplotlib, numpy, tqdm, sklearnです。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import matplotlib.pyplot as plt
import numpy as np
from tqdm.notebook import tqdm
from sklearn.metrics import accuracy_scoreGoogle Colab/Jupyterで動かさない場合は、tqdm.notebookをtqdmに変えてください。コードは以下になります。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
from sklearn.metrics import accuracy_score
importでエラーが出た場合は、必要なライブラリをインストールしてください
MNIST(手書き数字データセット)
データセット概要
MNISTのデータセットは以下の構成です
- 訓練データ(6万枚)、テストデータ(1万枚)の合計7万枚
- 8bitグレースケール(0~255)、28×28画素
PyTorchの場合は、torchvision.datasets.MNIST()を使うことで簡単にダウンロードし、データセットとして利用するこtが可能です。
データセットのダウンロード
以下のコードでtrain_datasetに6万枚の訓練データが、valid_datasetに1万枚のテストデータがダウンロードされます。
ローカル環境の場合、初回はデータセットがダウンロードされるので、インターネットへの接続が必要です
train_dataset = torchvision.datasets.MNIST(root="data",
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
valid_dataset = torchvision.datasets.MNIST(root="data",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)データの中身を確認してみます。以下のコードを実行すると、訓練データの25枚の内容が表示されます。
# データを確認
fig, ax = plt.subplots(5,5, figsize=(10,10))
for i in range(25) :
img, label = train_dataset[i]
r, c = i//5, i%5
ax[r, c].imshow(img.squeeze(), cmap="gray")
ax[r, c].axis("off")
ax[r, c].set_title(label)
データローダーの設定
PyTorchでは、データローダー(DataLoader)を使ってデータをロードするのが一般的です。データローダーは、バッチ単位でのデータのロード、データのシャッフル、マルチスレッドによるデータの読み込みなどをサポートしてくれるので、自身でコードを書かなくても、バッチ単位で画像をシャッフルしつつ読み込むことができます。
データセットを定義していれば、データローダーの設定は非常に簡単です。
batch_sizeはバッチサイズ、shuffleはシャッフルするかどうかのフラグです。訓練データは毎回順番が変化した方がよいので、shuffle=Trueと設定しています。
batch_size = 64
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)PyTorchのデータセットとデータローダーの関係
PyTorchのデータセット(Dataset)は、トレーニングやテストに使用するデータを扱うためのもので、例えば画像やテキストなどのデータを1つずつ処理します。一方、データローダー(DataLoader)は、データセットからバッチ単位でデータを取り出すためのものです。この2つを組み合わせることで、簡単に大量のデータを取り扱うことが可能です。
以上で、データセットを読み込む準備は完了です。
モデル
モデルを定義する
MNISTは簡単なモデルでも学習できるので、今回は全結合層3つからなるモデルとしてみます。
PyTorchでモデルを作成する場合は、nn.Moduleを派生したクラスを定義します。基本的には、以下の2つの関数を定義します
__init__()
初期化を行う関数です。引数は、自身のモデルに合わせて変更します。今回は、input_size(=28)を引数として受け取る想定です。画像のサイズはinput_size*input_sizeとなります。また、3つのnn.Linearを定義していますforward()
モデルの流れ(処理)を記述します。xは入力です(model(x)で渡される引数)
class MyCNNModel(nn.Module):
def __init__(self, input_size):
super(MyCNNModel, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(2,2)
self.act = nn.ReLU()
self.pool2 = nn.AdaptiveAvgPool1d(1024)
self.fc1 = nn.Linear(1024, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.pool(self.act(self.conv1(x)))
x = self.pool(self.act(self.conv2(x)))
x = torch.flatten(x, start_dim=1)
x = self.pool2(x)
x = self.act(self.fc1(x))
x = self.fc2(x)
return xモデルを図示すると以下のようになります。
最初のconv1, conv2がCNN(畳み込みの部分です)。2回畳み込みを行い7×7, 64チャネルにした後に、Flattenで1次元に変換し、AdaptivePoolで1024個に平均プーリングしています。
AdaptivePoolは、入力のサイズに関わらず出力サイズに合わせてくれるので、入力サイズを気にすることなく構成できるのでここに挿入しました。
実際は28×28と決まっているので、AdaptivePoolをする必要はありませんが、とりあえず挿入しています。AdaptivePoolについては以下の記事を参考にしてください。

Adaptive Pooling層の動きをわかりやすく解説【初級 深層学習講座】
最後の出力の10がクラスに対応し、クラスに対応してどれか1つの値だけ大きな値となります。例えば、文字が4の場合は、4番目の値が最大になるように学習させます。
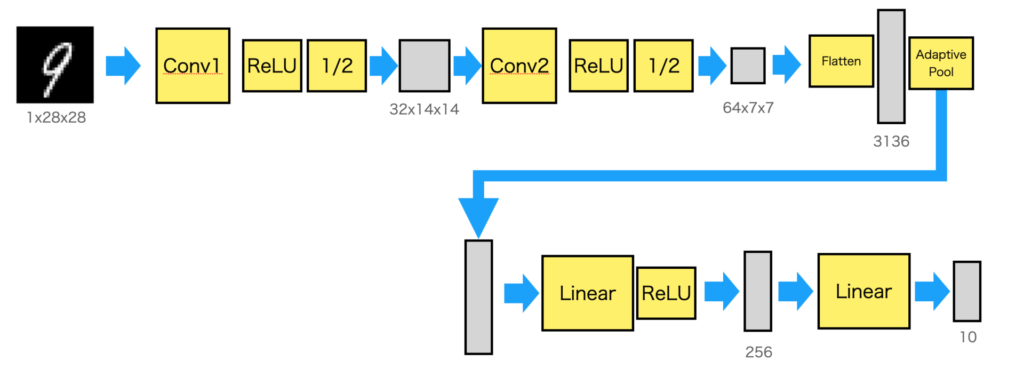
CNNを作る場合は、畳み込み層(conv)、活性化(ReLUなど)、プーリング(MaxPoolingなど)の3つを並べることが多いです。段が深くなった場合は、勾配消失を防ぐために、さらにバッチノーマライゼーションを並べます。
また、CNNの部分には、より複雑な構造を持つinceptionやresidual blockなどいろいろな構成が論文発表されています。
モデルを生成する
モデルを定義したので、モデルを生成します。モデルの生成は以下のコードになります。
device = ... の行は、GPUがあるかどうかをチェックして、GPUがある場合はcudaを、無い場合は、cpuを設定します。
to(device)とすることで、GPUがある場合はGPUにモデルがロードされます。
Macの場合は、GPUはmpsとなります
device = "cuda" if torch.cuda.is_available() else "cpu"
model = MyCNNModel(28).to(device)
model以下がモデルの内容を表示したものになります
MyCNNModel(
(conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(act): ReLU()
(pool2): AdaptiveAvgPool1d(output_size=1024)
(dropout): Dropout(p=0.5, inplace=False)
(fc1): Linear(in_features=1024, out_features=256, bias=True)
(fc2): Linear(in_features=256, out_features=10, bias=True)
)学習
損失関数と最適化手法を設定
損失関数と最適化手法を設定します。
クラス分類なので、損失関数はCrossEntropyLossを利用します。最適化手法は、SGDやAdamなどありますが、ここではAdamを選びました。
最適化関数の引数は、最適化するパラメータのリストと最適化のためのハイパーパラメータとなります。今回は、lrだけ設定し、他はデフォルトを利用しています。
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)最適化のパラメータを調整することで、精度や学習速度が変化します。ここは、何度か実験して決めていくのが一般的です
訓練用と評価用関数の定義
1エポック分の訓練用と評価用の関数を用意します。これを用意しておくと、学習コードが簡単になりますので、作成するように習慣づけしておくと良いと思います。
訓練用関数
学習では、model.train()でモデルを学習できる状態に切り替えます。
for文で、データローダーからデータを読み込み終わるまで繰り返します。処理の内容は以下の通りです
- 画像とラベルを読み出す
model(images)で、推論結果を出力lossを計算loss.backward()を実行して誤差を逆伝播optimizer.step()を実行- 各種結果集計
どのような学習でも基本の流れはほぼ同じです。
なお、modelを呼び出す前に、optimizer.zero_grad()を呼び出すのを忘れないようにしましょう。
def do_train(model, device, loader, criterion, optimizer):
model.train()
tot_loss = 0.0
tot_score = 0.0
for images, labels in tqdm(loader, desc="train"):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
tot_loss += loss.detach().item()
tot_score += accuracy_score(labels.cpu(), outputs.argmax(dim=1).cpu())
tot_loss /= len(loader)
tot_score /= len(loader)
return tot_loss, tot_score評価用関数
評価では、学習を行わないのでmodel.eval()で評価モードに切り替えます。
また、with torch.no_grad()で勾配計算を無効化しておきます。
no_grad()としておくことで推論時に不必要なメモリ使用量を減らすことができます
学習を行わないので、optimizerとloss.backwordは必要ありません。
def do_valid(model, device, loader, criterion):
model.eval()
tot_loss = 0.0
tot_score = 0.0
with torch.no_grad():
for images, labels in tqdm(loader, desc="valid"):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
tot_loss += loss.detach().item()
tot_score += accuracy_score(labels.cpu(), outputs.argmax(dim=1).cpu())
tot_loss /= len(loader)
tot_score /= len(loader)
return tot_loss, tot_score学習ループ
学習ループです。エポック数は10回としました。
処理としては、訓練→評価を繰り返して実行しているだけです。
trainとvalidで異なるデータを与えています。validのデータは学習に含まれていないので、validに対する結果は未知のデータに対する結果と考えることができます

validの結果が良いモデルを保存などすると、学習には使っていないですが、間接的にvalidがリークするので注意が必要です。
num_epochs = 10
for epoch in range(num_epochs):
print(f'[EPOCH {epoch+1}]')
train_loss, train_acc = do_train(model, device, train_loader, criterion, optimizer)
valid_loss, valid_acc = do_valid(model, device, valid_loader, criterion)
print(f"--> train loss {train_loss}, train accuracy {train_acc}, valid loss {valid_loss} valid accuracy {valid_acc}")
最終的に、以下のような結果となりました。
--> train loss 0.013030382923994666, train accuracy 0.9957689232409381, valid loss 0.027705744465230404 valid accuracy 0.9917396496815286評価データで正解率99.17%とかなり高い精度で数字が認識できていることが分かります。
下記の記事で作成したニューラルネットワークでは、正解率は97.76%でしたので畳み込みネットワークに変更することで性能がアップしたことが分かります。
なお、resnet18というより複雑なCNNモデルを利用した場合(下記記事参照)は、99.19%と精度がさらに高くなります。
resnet18は、今回のモデルよりもかなり大きなモデルとなります。モデル差を考えると0.02%差は微妙な感じです。
とりあえず、CNNを利用することで性能向上することが確認できました。
あわせて読みたい
PyTorchで手書き文字(MNIST)の認識の実装に挑戦【初級 深層学習講座】
まとめ
MNISTの手書き文字の識別を畳み込みネットワークで作成してみました。timmなどを利用し出すとモデルを自作することは減ってしまいますが、自力でモデルを作成できることは必要です。
簡単なモデルは自作できるようにしておいた方がよいです。
認識率向上の手法としてラベルスムージングなどもあります。興味がある場合は以下の記事を読んでみてください。

ラベル平滑化(Label Smoothing)とは?アルゴリズムとPytorchでの実装方法【初級 深層学習講座】



ディープラーニングに関する記事一覧はこちら

ディープラーニング関連の記事一覧
ABOUT ME

専門分野は並列処理・画像処理・機械学習・ディープラーニング。プログラミング言語はC, C++, Go, Pythonを中心として色々利用。現在は、Kaggle, 競プロなどをしながら悠々自適に活動中

