
LMStudioで外部ツールを呼び出す方法|Tool Use対応モデルの使い方
Aru
Aru's テクログ(Aruaru0)
PyCaretでのクラス分類の方法については以前の記事で紹介しましたが、この記事では回帰(Regression)、時系列分析(Time Series)、クラスタリング(Clustering)、異常検知(Anomaly Detection)の各タスクについて詳しく解説します。それぞれのタスクの実行方法を具体的なサンプルコードとともに紹介し、実践的な内容を心がけました。
PyCaretで回帰を行う必要があったので、以前の記事を見ながら取り組もうと思いましたが、クラス分類の方法しか書いていなかったことに気づきました。そこで、今回の記事では、前回の記事で取り上げなかった回帰(Regression)、時系列分析(Time Series)、クラスタリング(Clustering)、異常検知(Anomaly Detection)の各タスクについてまとめました。
今回もGoogle Colabで実行可能なノートブックをGithubに置いていますのでそちらも参考にしてください。
Google Colabで実行できるコードはこちらです。
前回の記事にも書きましたが、インストールは簡単です。以下のコマンドでインストールできます。
pip install pycaretscikit-learn、XGBoost、LightGBM、CatBoostなどでの評価も同時に行いたい場合には、これらも同時にインストールしておきます。
pip install scikit-learn
pip install xgboost
pip install lightgbm
pip install catboostPyCaretで回帰を行う場合は、pycaret.regressionを読み込みます。
from pycaret.regression import *
from pycaret.datasets import get_dataデータセットは、PyCaretで用意されているデータセットの中からdiamondを利用します。
df = get_data('diamond')このデータセットを使って、ダイヤモンドの価格を予測します。
session_idには、乱数のシードを入れます。ターゲットは価格なので、Priceを設定します。インポートの時に、pycaret.regressionとしているので、ここの部分はクラス分類とほぼ同じです。
seed = 42
reg = setup(df, target = 'Price', session_id=seed)実行すると、セットアップされた内容が表示されます

compare_modelsを呼び出してモデルの比較を行います。bestには最も良かったモデルが返されます。
best = compare_models()なお、以下のようにソートをどの指標で行うかや、上位何個のモデルを選択するかなどを引数で指定できます。
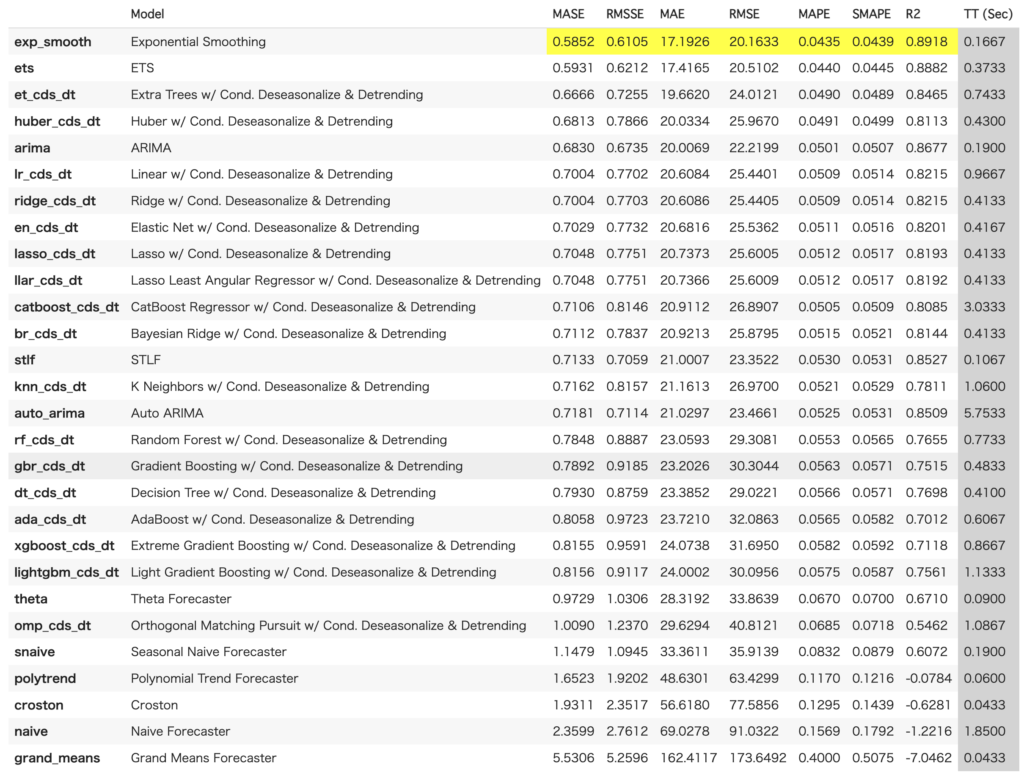
best = compare_models(sort="RMSE", n_select=3)結果から、CatBoostが全ての指標で良かったことがわかります。
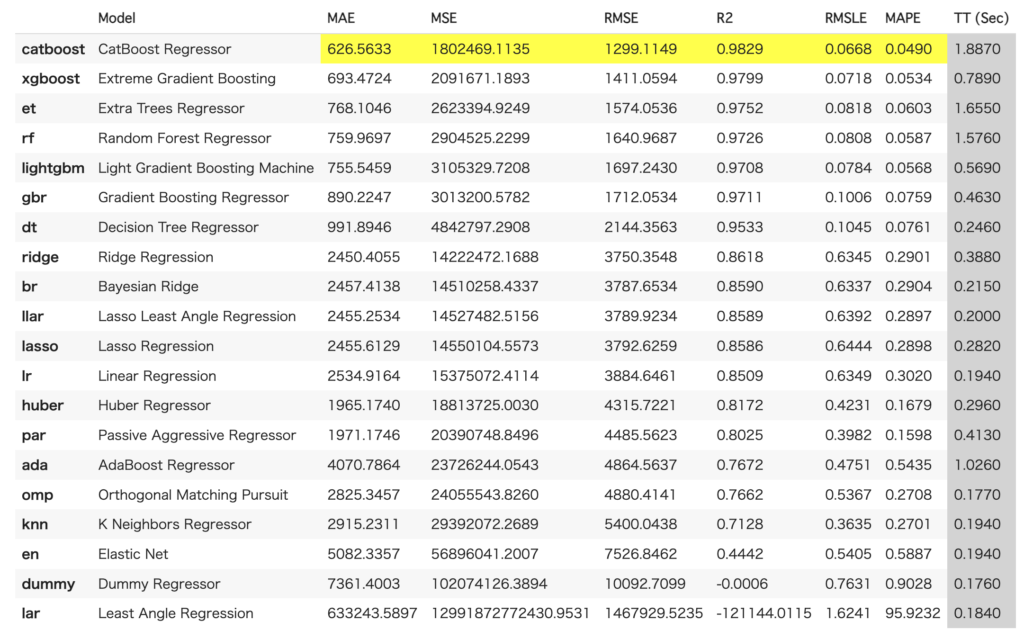
なお、それぞれの指標の意味は以下の通りです。
| 指標名 | 説明 |
| MAE | 誤差の絶対値(Mean Absolute Error) |
| MSE | 誤差の2乗(Mean Squared Error) |
| RMSE | 平均平方二乗誤差(Root Mean Squared Error) |
| R2 | 決定係数(1に近いほど良いスコア) |
| RMSLE | 対数平均平方二乗誤差(Root Mean Squared Logarithmic Error) |
| MAPE | 平均絶対パーセント誤差(Mean Absolute Percentage Error) |
回帰に関しては、結果を可視化してみます。これも用意された関数で簡単に行うことができます。
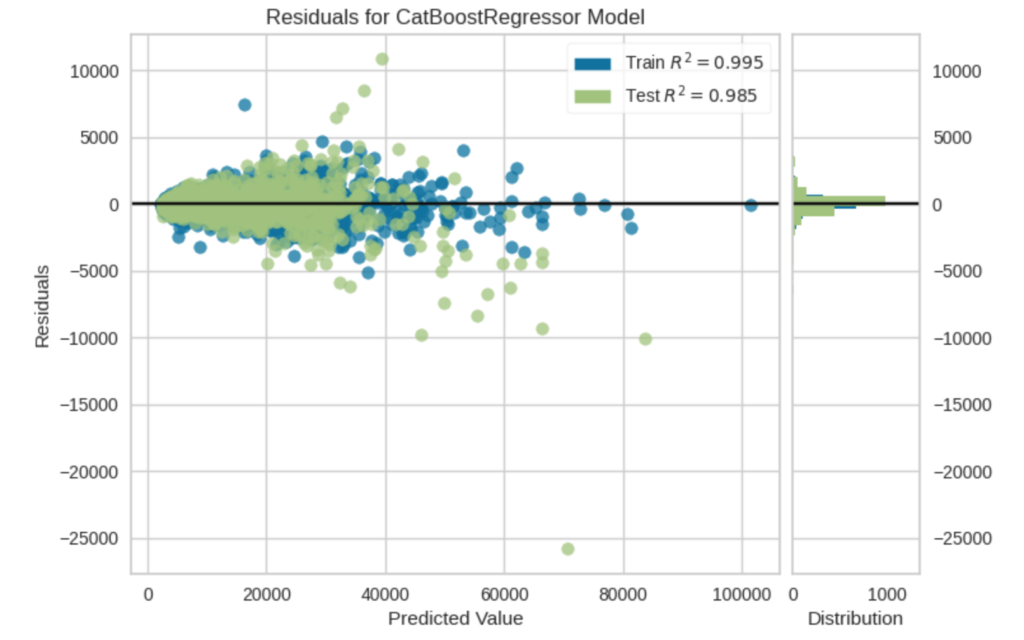
plot_model(best[0])
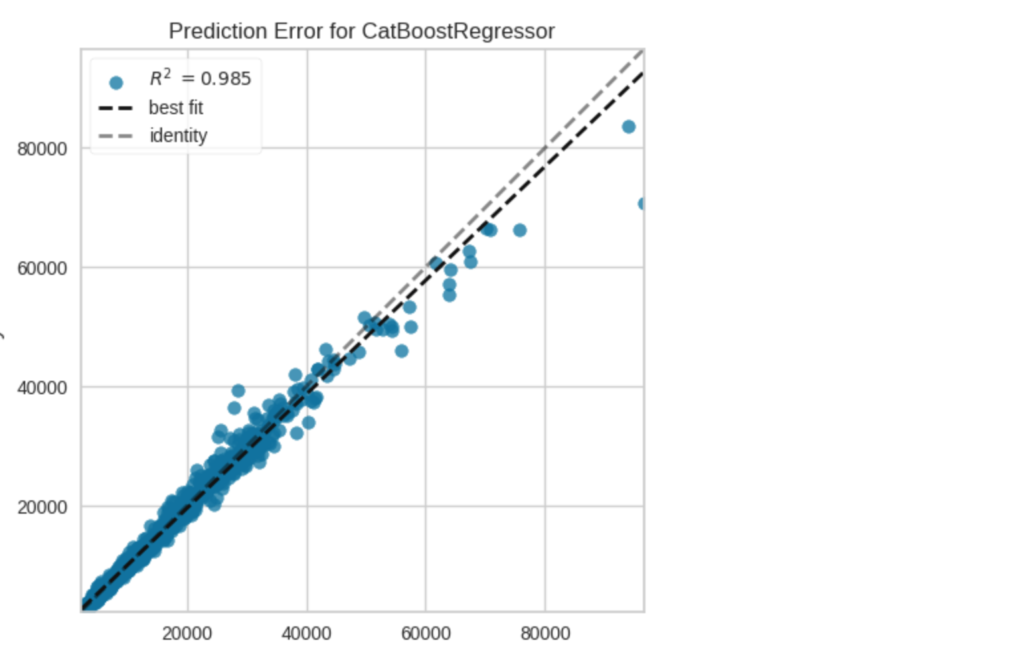
plot_model(best[0], plot="error")
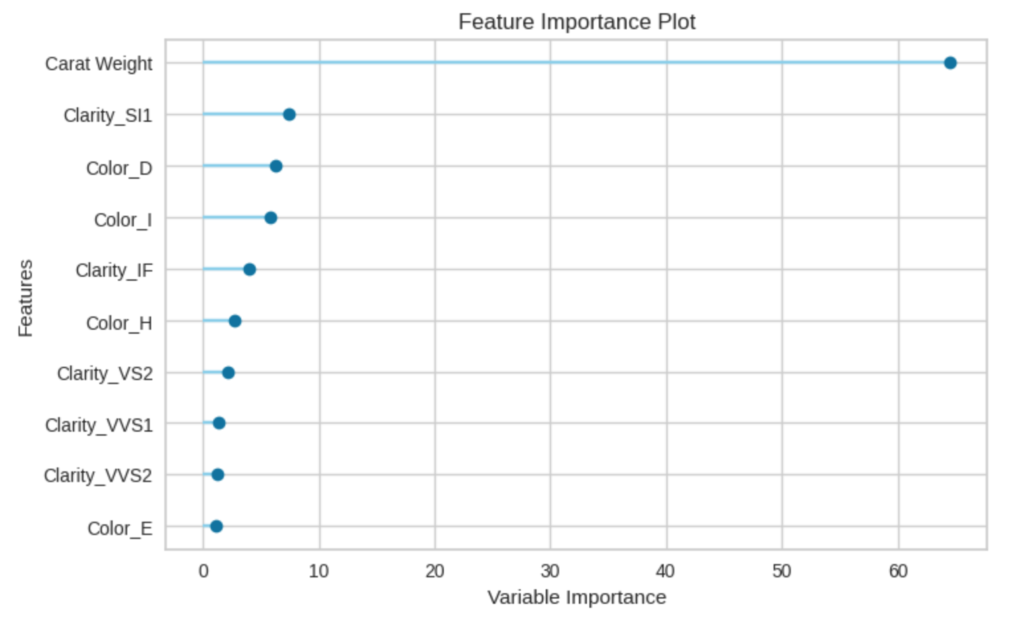
plot_model(best[0], plot="feature")3つのグラフは、上のコードの実行結果です。最初のグラフは、横軸が予測値、縦軸が正解値との誤差です(所謂、Bland-Altmanグラフ)。2つ目は誤差を、3つ目はCatBoostの特徴量への重みです。3つ目のグラフを見ると、カラット数(Carat Weight)の重みが大きいことがわかります。
最後にモデルをファイナライズしています。ファイナライズでは、全てのデータを使って学習を行いますので、モデルとパラメータが決定したらこれを実行しておきます。
models = finalize_model(best[0])モデルの保存、読み込み、予測は以下のようにします。
save_model(models, "models")
loaded = load_model("models")
pred = predict_model(loaded, data=df)時系列データでは、pycaret.time_seriesをインポートします。
from pycaret.time_series import *
from pycaret.datasets import get_data
import pandas as pd
import numpy as np利用するデータセットは、airlineです。このデータセットは、米国の航空会社の乗客データセットで、1949 年から 1960 年までの米国の航空会社の乗客数の月次合計のデータです。
data = get_data('airline')
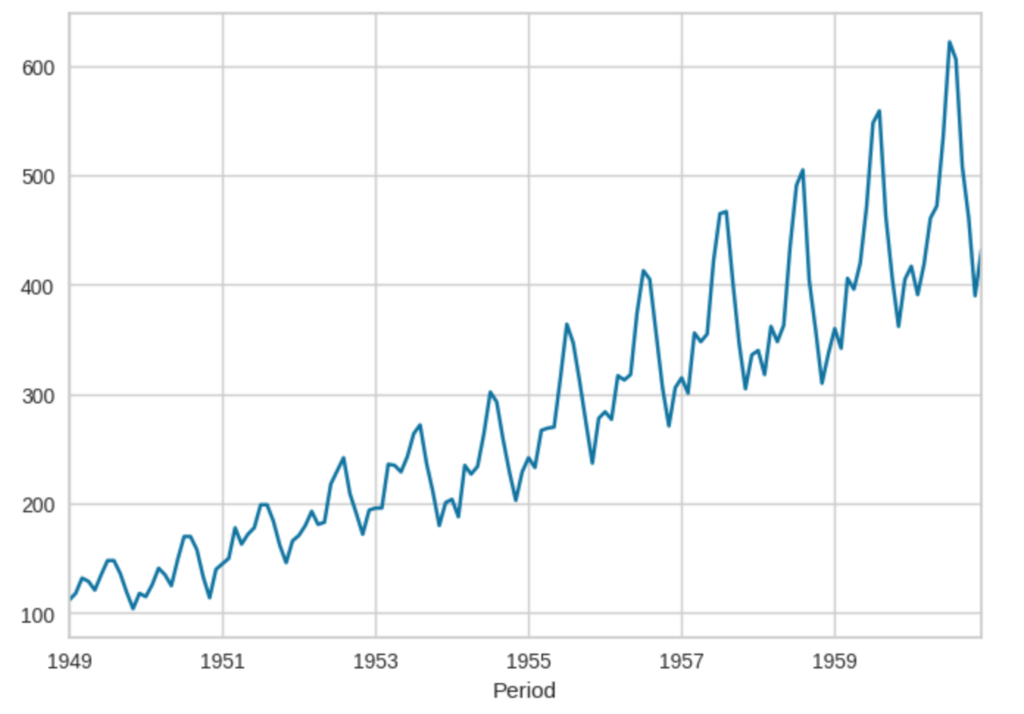
data.plot()プロットすると以下のようなグラフが表示されます。ノコギリ状の山が右肩あがりで存在することがわかるかと思います。今回は、これの続きを予測してみます。
セットアップのやり方はクラス分類と大体同じです。fhは、予測に使用される予測期間で以下では12ヶ月を指定しています。これを指定することで、最後の1年は予測に使用されます。
seed = 42
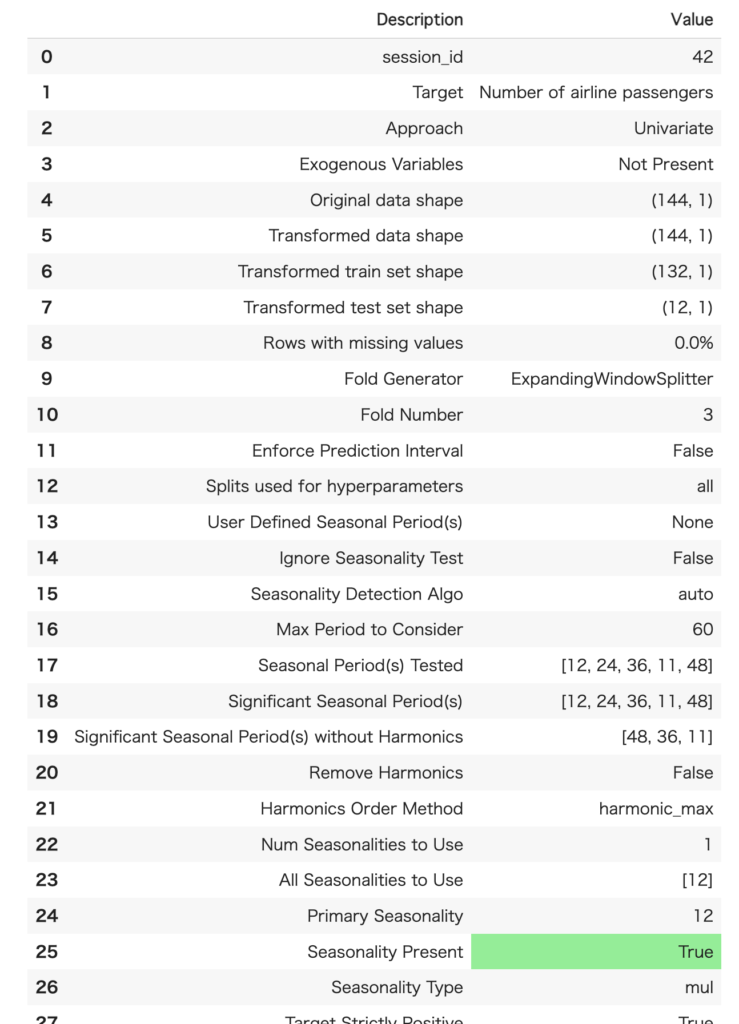
ts = setup(data = data, fh = 12, session_id=seed)なお、指定しない場合は、1が指定されます。また、seasonal_periodを指定することで周期性を設定することができます。乗客数のデータの場合、パッと見で1年周期(12ヶ月周期)があることがわかるのでseasonal_period = 12を指定すれば良いです。指定しなくても自動で設定されるようですが、周期性がわかっている場合には、設定しておいた方が予測精度が向上します。
実行すると以下のような設定結果が表示されます(一部略)
compare_modelsを使って、モデル比較を行います。比較評価を行わない場合は、create_modelで直接モデルを指定してモデルを作成しても良いですが、せっかくPyCaretを使うので、モデルの選定も自動で行います。
best = compare_models()実行すると、時系列用のモデルの結果が並びます。
まず、プロットしてみます。最後の1年の予測結果は、正しい値とほぼ一致しているように見えます。まずまずの予測ができていると言えます。
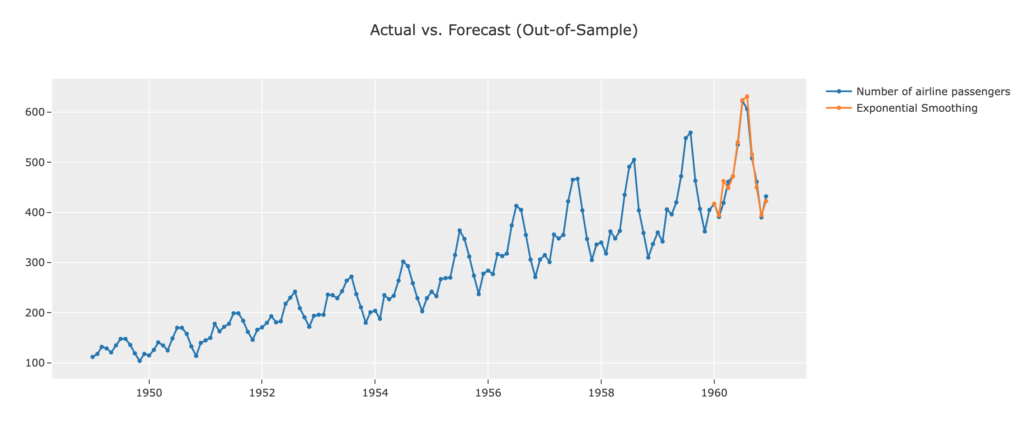
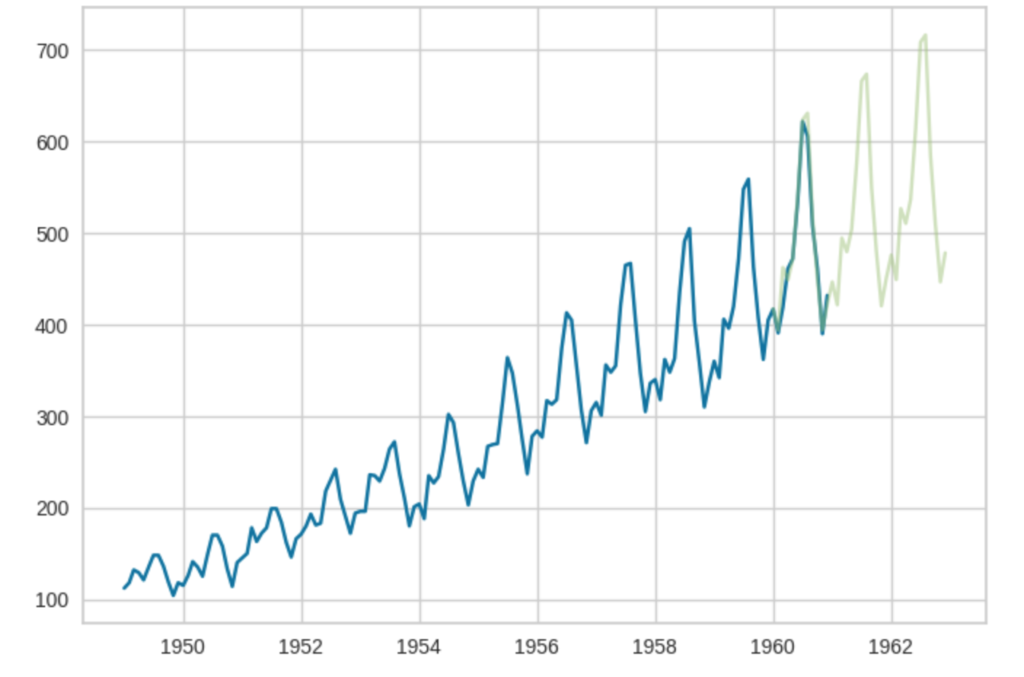
さらに、2年先まで予測を行ってみます
pred = predict_model(best,36)この結果をグラフにプロットします。まずは、matplotlibで扱いやすいようにデータを変換します。具体的には、indexをタイムスタンプ型に変換してます。
pred = pred.to_timestamp()
prev = pd.DataFrame(data).to_timestamp()
prev.head()グラフにプロットします。
import matplotlib.pyplot as plt
plt.plot(prev.index, prev['Number of airline passengers'])
plt.plot(pred.index, pred.y_pred, alpha=0.5)グラフを見る限り、なんとなく予測できてそうな雰囲気です。
クラスタリングでは、pycaret.clusteringをインポートします。
from pycaret.clustering import *
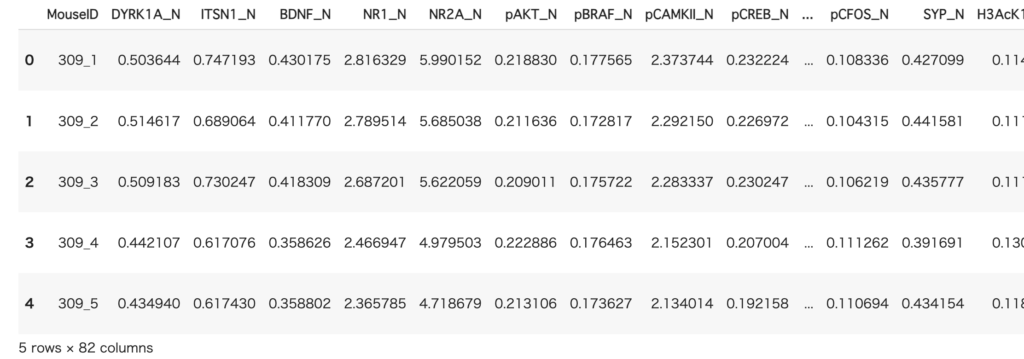
from pycaret.datasets import get_dataここで使うデータはmiceです。このデータは、ネズミのタンパク質のデータです。これをクラスタリングしてみます。
data = get_data('mice')このデータは1080行×82列のデータとなります。
セットアップは、これまでとほぼ同じです。今回は、MouseIDは除外したいので、ignore_featuresを使って除外指定しています。
seed = 42
clust = setup(data, ignore_features = ['MouseID'], session_id = seed)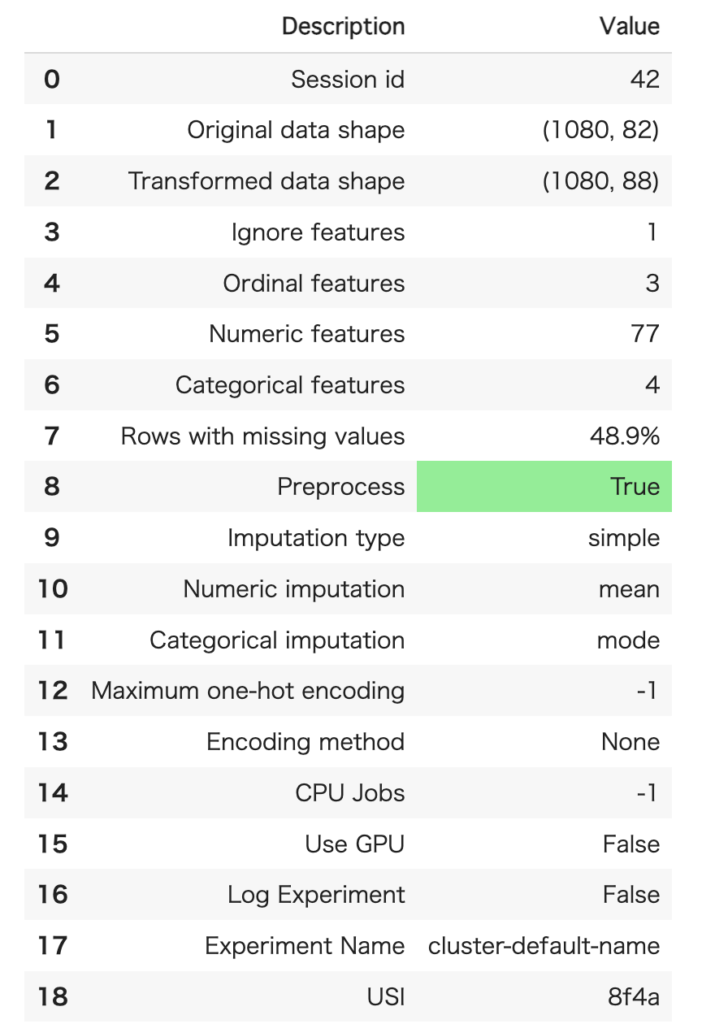
調べた限りでは、クラスタリングではcompare_modelsが用意されていないみたいです。ですから、モデルを指定する必要があります。設定できるモデルはmodels()を実行して確認できますが、以下の通りです。
| モデル名 | 説明 |
| kmeans | K-Means Clustering |
|---|---|
| ap | Affinity Propagation |
| meanshift | Mean Shift Clustering |
| sc | Spectral Clustering |
| hclust | Agglomerative Clustering |
| dbscan | Density-Based Spatial Clustering |
| optics | OPTICS Clustering |
| birch | Birch Clustering |
今回は、Kmeansを利用してみます。
kmeans = create_model('kmeans')結果をグラフで見てみます。
plot_model(kmeans)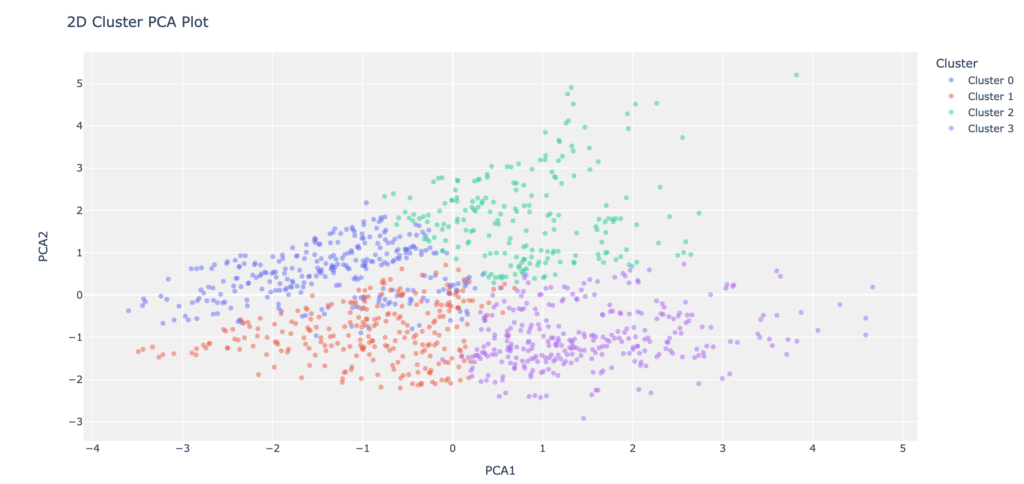
4つのクラスタに分割されていることがわかります。また、以下のようにグラフプロットをすると適切なクラスタ数を確認することができます。
plot_model(kmeans, plot = 'elbow')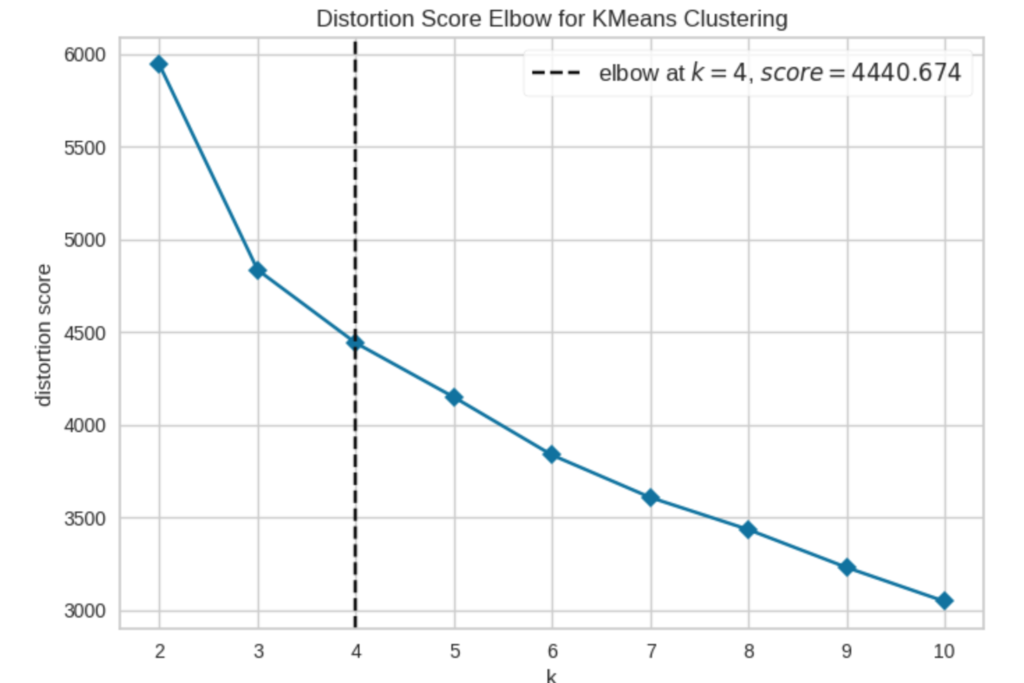
新しいデータがどのクラスタに属しているかは、以下のようなコードで予測することができます(今回は既知のデータで行なっています)
predict_model(kmeans, data)[['Cluster']]
異常検知の場合、pycaret.anomalyをインポートします。
from pycaret.anomaly import *
from pycaret.datasets import get_data異常検知でもmiceのデータを使います。
data = get_data('mice')セットアップのやり方は、クラスタリングと同じです(MouseIDを除外するのも同じ)。
seed = 42
ano = setup(data, ignore_features = ['MouseID'], session_id = seed)異常検知もcompare_modelsが使えないようなので、create_modelでモデルを指定して作成します。異常検知で使えるモデルもmodels()でチェックできますが、以下のモデルでした。
| モデル名 | 説明 |
| abod | Angle-base Outlier Detection |
|---|---|
| cluster | Clustering-Based Local Outlier |
| cof | Connectivity-Based Local Outlier |
| iforest | Isolation Forest |
| histogram | Histogram-based Outlier Detection |
| knn | K-Nearest Neighbors Detector |
| lof | Local Outlier Factor |
| svm | One-class SVM detector |
| pca | Principal Component Analysis |
| mcd | Minimum Covariance Determinant |
| sod | Subspace Outlier Detection |
| sos | Stochastic Outlier Selection |
ここでは、iforestを使って予測してみます。
iforest = create_model('iforest')データを分析するには、assign_modelを実行します。
forest_results = assign_model(iforest)
iforest_results.head()結果をグラフで見てみます。
plot_model(iforest)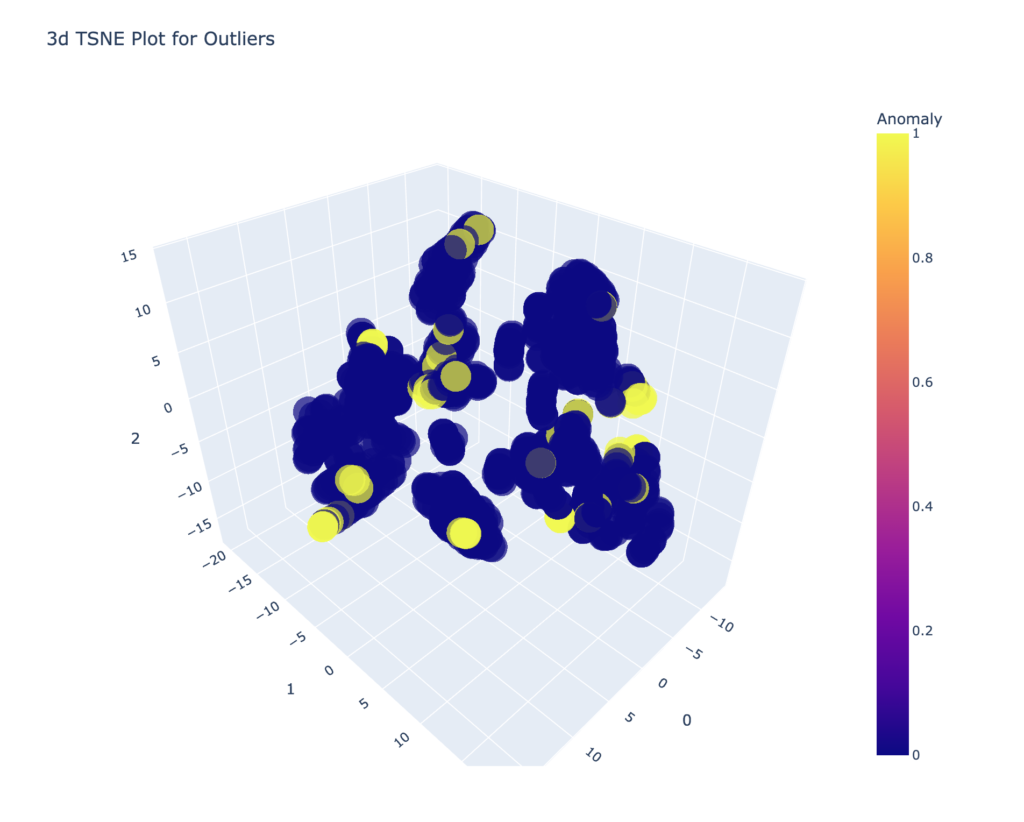
結果は上記のようになります。黄色に近い部分が異常値になります。
予測は、以下のコードになります。今回は、既知のデータを使っていますが、本来は未知のデータを入力して予測します。
pred = predict_model(iforest, data=data.drop(columns=['MouseID']))異常値判定されたものだけ抜き出すコードと以下のようになりました。
pred[pred['Anomaly'] == 1]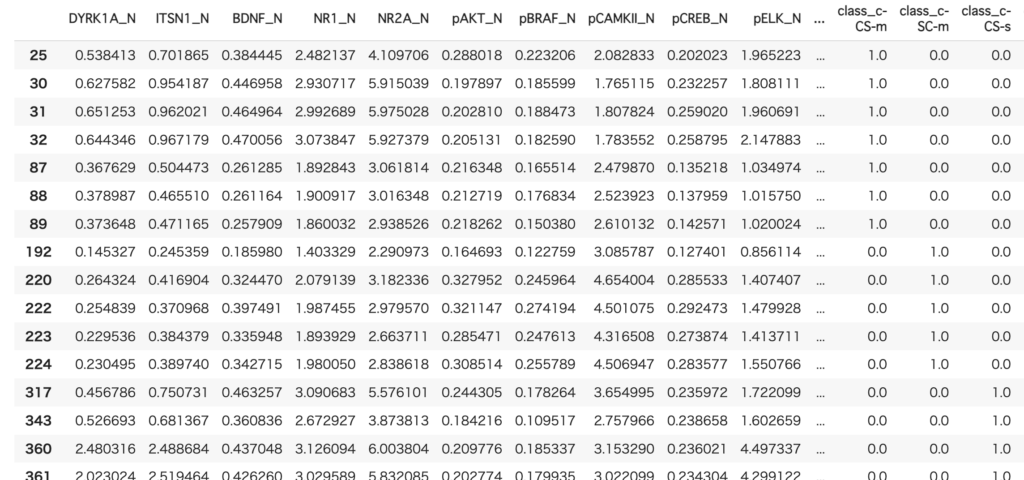
PyCaretを使って回帰・時系列データ・クラスタリング・異常検知をやってみました。
クラス分類以外のタスクも色々行うことができるPyCaretdですが、それぞれの使い方をちゃんと調べたことがなかったので良い勉強になりました。
参考になれば幸いです。



