
PyTorch+TIMMでクラス分類(犬猫分類)にチャレンジ
Aru
Aru's テクログ(Aruaru0)

この記事では、PyTorchを使ったU-Netを用いた超解像の実装方法について解説します。超解像技術は、画像の解像度を上げるための技術で、最近はディープラーニングを使った手法がメジャーになりました。ここでは、U-Netを用いて学習データをもとに超解像モデルを構築し、その後の画像の高解像度化にチャレンジしてみます(Apple silicon用のコードも入れています)。
超解像(Super-Resolution, SR)とは、低解像度画像から高解像度画像を生成する技術です。従来の高解像度化では、バイキュービックやLanczos補間などでピクセル間を補間し、解像度を向上させていましたが、ノイズが増えたり、リンギングが発生したりすることがありました。
ディープラーニングの登場で、超解像処理と呼ばれる高解像度化の処理が実用レベルになり、画像の細部まで再現することが可能となりました。
ディープラーニングを用いた超解像技術の代表例は以下の通り。
U-Netも超解像に利用されるネットの一つで、特にスキップ接続により細かい特徴を捉えることができるため、超解像処理に向いたネットワークの1つです。
U-Netは、セグメンテーションのために開発された深層畳み込みニューラルネットワークですが、ノイズリダクション処理や超解像処理に応用することも可能です。U-Netは、大きく分けてエンコーダとデコーダの2つの部分からなるネットワークで、U字型の構造をしています。
図にすると下図のような構造になります。エンコーダーとデコーダーがU字型に接続され、同じ高さにはスキップ接続があるのが特徴です。
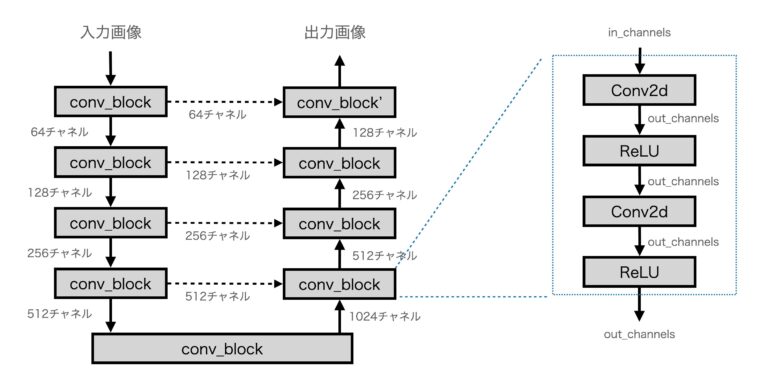
ここでは、説明したモデルを実際にPyTorchで作成し、学習・推論させてみます。以下のコードはGoogle Colabで動作確認しています。なお、学習データに関しては、train_dataフォルダを作成し、適当な画像(png)を格納すれば実行できます。

画像は、最低でも20枚程度はほしいです。
Colabで動作するコードはここにあります(画像等は用意していないので、train_dataにpngファイルを用意する必要があります)
利用するパッケージ(ライブラリ)をインポートします。今回はtorch, torchvisionを利用します。また、ファイルアクセスに必要となりそうなパッケージも合わせてインポートしています。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from torchvision.utils import save_image
import glob
import os
import matplotlib.pyplot as plt
import numpy as np
from PIL import ImageU-Netのモデル定義です。conv_blockは、conv-reluで構成されるブロックを生成するためのユーティリティ関数です。U-Netではこの構造を多用するので、関数として用意しました。
モデルの処理は、先に示したU-Netの構造そのものになります。
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(UNet, self).__init__()
self.encoder = nn.ModuleList([
self.conv_block(in_channels, 64),
self.conv_block(64, 128),
self.conv_block(128, 256),
self.conv_block(256, 512)
])
self.bottleneck = self.conv_block(512, 1024)
self.decoder = nn.ModuleList([
self.conv_block(1024+512, 512),
self.conv_block(512+256, 256),
self.conv_block(256+128, 128),
nn.Sequential(
nn.Conv2d(128+64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, out_channels, kernel_size=3, padding=1),
)
])
def conv_block(self, in_channels, out_channels):
"""Conv-ReLUブロックを生成するユーティリティ関数"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
)
def forward(self, x):
skip_connections = []
# Encoder
for enc in self.encoder:
x = enc(x)
skip_connections.append(x)
x = nn.MaxPool2d(2)(x)
# Bottleneck
x = self.bottleneck(x)
# Decoder
for i, dec in enumerate(self.decoder):
x = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)(x)
if i < len(skip_connections):
x = torch.cat((x, skip_connections[-(i + 1)]), dim=1) # skip connection
x = dec(x)
return xモデルをSRCNNに入れ替える場合は、以下のモデル定義を使います。SRCNNの方が構造がシンプルなので高速です。GPUのない環境で試したい場合はこちらを使うと
class SRCNN(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=out_channels, kernel_size=5, padding=2)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.conv3(x)
return xデータセット(SuperResolutionDataset)を定義します。
データセットでは、低解像度(ぼけ画像)を以下の手順で作成しています。
256x256サイズにランダムにクロップ(切り抜き)上記の処理で、元の画像(高解像度画像)とぼけ画像(低解像度画像)のペアを作成しています。②でランダムクロップをして256×256サイズに変換しているので、元の画像のサイズを気にする必要はありませんが、あまり大きいと読み込みが重くなるので注意が必要です。
class SuperResolutionDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
# self.image_files = [f for f in os.listdir(root_dir) if f.endswith('.png')]
self.image_files = glob.glob(os.path.join(root_dir, "*.png"))
self.crop = transforms.RandomCrop(256)
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_name = os.path.join(self.image_files[idx])
image = Image.open(img_name).convert('L') # グレースケール画像
image = self.crop(image)
# ボケた画像を作成
# Image.NEAREST Image.BOX Image.BILINEAR Image.HAMMING Image.BICUBIC Image.LANCZOS
low_res = image.resize((image.size[0] // 2, image.size[1] // 2), Image.BILINEAR)
low_res = low_res.resize(image.size, Image.BILINEAR)
if self.transform:
image = self.transform(image)
low_res = self.transform(low_res)
return low_res, image拡大・縮小はBILINEARで行っています。BICUBICなどを用いると折り返しによるリンギング(エッジが光る現象)が発生するので、学習時は線形補間による縮小・拡大を行いました。
以下のようなコードで、データセットの読み込みが正しく行われているか確認することが可能です。
transform = transforms.Compose([
transforms.RandomCrop(256),
transforms.ToTensor(),
])
dataset = SuperResolutionDataset(root_dir='train_data', transform=transform)
low, hi = dataset[0]
plt.imshow(low.squeeze(), cmap='gray')
plt.show()
plt.imshow(hi.squeeze(), cmap='gray')
plt.show()学習用のtrain関数を定義します。出力は10epochに1回にしました。
def train(model, dataloader, criterion, optimizer, num_epochs=20):
model.train()
for epoch in range(num_epochs):
for i, (low_res, high_res) in enumerate(dataloader):
optimizer.zero_grad()
# GPU使用のため
low_res = low_res.to(device)
high_res = high_res.to(device)
outputs = model(low_res)
loss = criterion(outputs, high_res)
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.6f}')モデル生成です。UNetモデルを入力1ch, 出力1chで作成しています(今回のモデルはグレースケール画像に対するものになります)。
カラー画像を入力できるようにしていますので、カラーでも利用できるかと思います。カラーの場合はデータセットの方も修正が必要になります。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# モデル、損失関数、最適化手法の初期化
model = UNet(in_channels=1, out_channels=1).to(device)
# model = SRCNN(in_channels=1, out_channels=1).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-5)学習のメインループです。epoch数はとりあえず2,000回としました。モデルの学習が完了したらセーブしています。
# データ変換
transform = transforms.Compose([
transforms.ToTensor(),
])
# データセットとデータローダーの作成
dataset = SuperResolutionDataset(root_dir='train_data', transform=transform)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# モデルのトレーニング
train(model, dataloader, criterion, optimizer, num_epochs=2000)
# モデルの保存
torch.save(model.state_dict(), 'unet_super_resolution.pth')結果を見ると、Lossも順調に減少し学習が進んでいることがわかります。
Epoch [1/2000], Loss: 0.268597
Epoch [11/2000], Loss: 0.268679
Epoch [21/2000], Loss: 0.049778
Epoch [31/2000], Loss: 0.041591
Epoch [41/2000], Loss: 0.027210
Epoch [51/2000], Loss: 0.013986
Epoch [61/2000], Loss: 0.008761
Epoch [71/2000], Loss: 0.006517
Epoch [81/2000], Loss: 0.005540
:
<略>
:
Epoch [1961/2000], Loss: 0.001195
Epoch [1971/2000], Loss: 0.001052
Epoch [1981/2000], Loss: 0.001014
Epoch [1991/2000], Loss: 0.000992以下は推論のテストです。学習終了後に継続して推論をするコードになっており、保存したモデルの読み込みは行なっていません。
本来は、valid画像のlossが最小のモデルを保存しておくべきですが、今回はvalid画像を用意せずに処理したので最終epochのモデルを利用しています。
テスト画像を読み込みます。この例ではdatas/girl.jpgを読み込んでいます。読み込んだ画像を縮小→拡大してボケ画像を作成しています。
image_file = "datas/girl.jpg"
image = Image.open(image_file).convert('L') # グレースケール画像
# ボケた画像を作成
low_res = image.resize((image.size[0] // 2, image.size[1] // 2), Image.BILINEAR)
low_res = low_res.resize(image.size, Image.BILINEAR)
plt.imshow(low_res, cmap='gray')
plt.show()ボケ画像をモデルで処理して処理画像を作成しています。
img = transform(low_res).unsqueeze(0).to(device)
print(img.shape)
model.eval()
with torch.no_grad():
predicted_image = model(img)
predicted_image = predicted_image.squeeze().cpu().numpy()
predicted_image = np.clip(predicted_image, 0, 1) # 値を0-1にクリップ
plt.imshow(predicted_image, cmap='gray')
plt.show()以下、元の画像、処理画像、元の画像を縮小・拡大して作成したボケ画像(入力画像)を並べたものです。予想したより綺麗になりました。学習データが少なめ、かつ、epoch数も少なめだったのに意外です。


なお、実際の処理の場合、低解像度の画像をターゲットの解像度に拡大処理してモデルに入力します。今回のモデルでは縦横2倍の高解像度化に対する学習をしたので2倍拡大に利用するモデルとなります。
U-NetはConv2Dのみで構成されるネットワークなので、入力サイズが学習時の画像サイズと異なっても処理することができます。実際、学習は256×256サイズで行いましたが、推論の画像は512×768の画像で行いました。
損失関数(MSEloss)と似た計算式なので、lossを小さくする方向で処理していればSNRも向上している可能性が高いので一応SNRもチェックしてみました。
## SNRを計算する
def calc_snr(original_image, noisy_image):
"""
2つのPIL Imageを入力として、SNRを計算する
original_image: PIL Image (元画像)
noisy_image: PIL Image (ノイズのある画像)
"""
# PIL Image を NumPy 配列に変換
original_image_np = np.array(original_image, dtype=np.float32)
noisy_image_np = np.array(noisy_image, dtype=np.float32)
# 元画像とノイズ画像の差を計算
noise = noisy_image_np - original_image_np
# 信号(元画像)のパワーを計算
signal_power = np.mean(original_image_np ** 2)
# ノイズのパワーを計算
noise_power = np.mean(noise ** 2)
# SNRを計算(10 * log10(signal/noise))
if noise_power == 0:
return float('inf') # ノイズが全くない場合、SNRは無限大
else:
snr = 10 * np.log10(signal_power / noise_power)
return snr
result = transforms.functional.to_pil_image(predicted_image)
print("low_res SNR = ", calc_snr(image, low_res))
print("result SNR = ", calc_snr(image, result))結果は以下の通りです。若干ですが良くなっている感じです。数値で見ると大したことないですが、画像で見るとかなりくっきりした印象です。
low_res SNR = 26.314213275909424
result SNR = 28.841605186462402学習時に、高解像度画像を縮小して入力画像(低解像度画像)を作ることで学習データを簡単に準備することが可能です。ただし、拡大と縮小のアルゴリズムの影響を受けますので拡大・縮小のアルゴリズム選定は要注意です。
個人的にはバイリニア補間を使うと、入力画像の影響をあまり受けずに高解像度化できる印象があります。
アニメ絵などはニヤレストネイバー補間などが良いかもしれません。
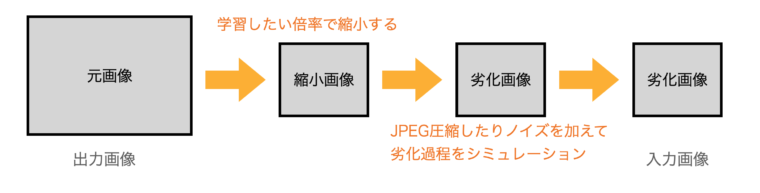
超解像処理のモデルを学習させる場合、元の画像を劣化させて入力画像を作成しますが、このとき、縮小処理はターゲットにする倍率に合わせると精度がアップします。また、実際に処理したい画像がJPEG圧縮などされている場合はJPEG圧縮を実際に行なったり、その他のノイズを加えた方がうまくいきます(劣化の過程をシミュレーションして入力画像を作成します)。
万能な超解像処理のモデルより、「DVDのアップコンバート専用」などのモデルを作成した方がうまくいくので、入力画像と出力画像(結果画像)のペアの作成はそれに合わせた処理を施したほうがよいです。
このあたりは、ノウハウになるかと思います
以下、Apple Silicon搭載のMac用のコードです。MacBook Air(M2, 16GB)で動作させたところ、学習に20枚ほどの学習データを使って10時間ほどかかりました。
コードは学習用のコードと、超解像処理テスト用コードの2つに分かれています。
sr_train.py)Apple SiliconのGPUを使って学習を行うコードです(”mps”)。train_dataに学習用のpngファイルを入れてください。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from torchvision.utils import save_image
import glob
import os
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from tqdm import tqdm
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(UNet, self).__init__()
self.encoder = nn.ModuleList([
self.conv_block(in_channels, 64),
self.conv_block(64, 128),
self.conv_block(128, 256),
self.conv_block(256, 512)
])
self.bottleneck = self.conv_block(512, 1024)
self.decoder = nn.ModuleList([
self.conv_block(1024+512, 512),
self.conv_block(512+256, 256),
self.conv_block(256+128, 128),
nn.Sequential(
nn.Conv2d(128+64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, out_channels, kernel_size=3, padding=1),
)
])
def conv_block(self, in_channels, out_channels):
"""Conv-ReLUブロックを生成するユーティリティ関数"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
)
def forward(self, x):
skip_connections = []
# Encoder
for enc in self.encoder:
x = enc(x)
skip_connections.append(x)
x = nn.MaxPool2d(2)(x)
# Bottleneck
x = self.bottleneck(x)
# Decoder
for i, dec in enumerate(self.decoder):
x = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)(x)
if i < len(skip_connections):
x = torch.cat((x, skip_connections[-(i + 1)]), dim=1) # skip connection
x = dec(x)
return x
class SRCNN(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=out_channels, kernel_size=5, padding=2)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.conv3(x)
return x
class SuperResolutionDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
# self.image_files = [f for f in os.listdir(root_dir) if f.endswith('.png')]
self.image_files = glob.glob(os.path.join(root_dir, "*.png"))
self.crop = transforms.RandomCrop(256)
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_name = os.path.join(self.image_files[idx])
image = Image.open(img_name).convert('L') # グレースケール画像
image = self.crop(image)
# ボケた画像を作成
# Image.NEAREST Image.BOX Image.BILINEAR Image.HAMMING Image.BICUBIC Image.LANCZOS
low_res = image.resize((image.size[0] // 2, image.size[1] // 2), Image.BILINEAR)
low_res = low_res.resize(image.size, Image.BILINEAR)
if self.transform:
image = self.transform(image)
low_res = self.transform(low_res)
return low_res, image
def train(model, dataloader, criterion, optimizer, num_epochs=20):
model.train()
with tqdm(total = num_epochs) as pbar:
for epoch in range(num_epochs):
for i, (low_res, high_res) in enumerate(dataloader):
optimizer.zero_grad()
# GPU使用のため
low_res = low_res.to(device)
high_res = high_res.to(device)
outputs = model(low_res)
loss = criterion(outputs, high_res)
loss.backward()
optimizer.step()
pbar.set_postfix({"Loss": loss.item()})
pbar.update()
# if epoch % 10 == 0:
# print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.6f}')
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device(device if not torch.backends.mps.is_available() else "mps")
# モデル、損失関数、最適化手法の初期化
model = UNet(in_channels=1, out_channels=1).to(device)
# model = SRCNN(in_channels=1, out_channels=1).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-5)
# データ変換
transform = transforms.Compose([
transforms.ToTensor(),
])
# データセットとデータローダーの作成
dataset = SuperResolutionDataset(root_dir='train_data', transform=transform)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# モデルのトレーニング
print("Training model...", device)
train(model, dataloader, criterion, optimizer, num_epochs=2000)
# モデルの保存
torch.save(model.state_dict(), 'unet_super_resolution.pth')
# 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [10:47:12<00:00, 19.42s/it, Loss=0.00102]
sr_create.py)推論コードです。ここでは、SNRを計算するため入力画像を一旦低解像度(ぼけ画像)にしたあと超解像処理を行なっています。実際に利用する場合は、低解像度画像を入力するように処理を変更する必要があります。
とりあえず、縮小・拡大をしないようにすれば入力画像をそのまま超解像処理を行うように修正できます。
具体的にはコードの以下の部分を、
low_res = image.resize((image.size[0] // 2, image.size[1] // 2), Image.BILINEAR)
low_res = low_res.resize(image.size, Image.BILINEAR)次のように修正します。
low_res = imageimport torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
import numpy as np
from PIL import Image
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(UNet, self).__init__()
self.encoder = nn.ModuleList([
self.conv_block(in_channels, 64),
self.conv_block(64, 128),
self.conv_block(128, 256),
self.conv_block(256, 512)
])
self.bottleneck = self.conv_block(512, 1024)
self.decoder = nn.ModuleList([
self.conv_block(1024+512, 512),
self.conv_block(512+256, 256),
self.conv_block(256+128, 128),
nn.Sequential(
nn.Conv2d(128+64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, out_channels, kernel_size=3, padding=1),
)
])
def conv_block(self, in_channels, out_channels):
"""Conv-ReLUブロックを生成するユーティリティ関数"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
)
def forward(self, x):
skip_connections = []
# Encoder
for enc in self.encoder:
x = enc(x)
skip_connections.append(x)
x = nn.MaxPool2d(2)(x)
# Bottleneck
x = self.bottleneck(x)
# Decoder
for i, dec in enumerate(self.decoder):
x = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)(x)
if i < len(skip_connections):
x = torch.cat((x, skip_connections[-(i + 1)]), dim=1) # skip connection
x = dec(x)
return x
class SRCNN(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=out_channels, kernel_size=5, padding=2)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.conv3(x)
return x
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device(device if not torch.backends.mps.is_available() else "mps")
# model = SRCNN(in_channels=1, out_channels=1).to(device)
model = UNet(in_channels=1, out_channels=1).to(device)
model.load_state_dict(torch.load('unet_super_resolution.pth'))
image_file = "datas/girl.png"
image = Image.open(image_file).convert('L') # グレースケール画像
# ボケた画像を作成
low_res = image.resize((image.size[0] // 2, image.size[1] // 2), Image.BILINEAR)
low_res = low_res.resize(image.size, Image.BILINEAR)
transform = transforms.Compose([
transforms.ToTensor(),
])
img = transform(low_res).unsqueeze(0).to(device)
print(img.shape)
model.eval()
with torch.no_grad():
predicted_image = model(img)
predicted_image = predicted_image.squeeze().cpu().numpy()
predicted_image = np.clip(predicted_image, 0, 1) # 値を0-1にクリップ
## SNRを計算する
def calc_snr(original_image, noisy_image):
"""
2つのPIL Imageを入力として、SNRを計算する
original_image: PIL Image (元画像)
noisy_image: PIL Image (ノイズのある画像)
"""
# PIL Image を NumPy 配列に変換
original_image_np = np.array(original_image, dtype=np.float32)
noisy_image_np = np.array(noisy_image, dtype=np.float32)
# 元画像とノイズ画像の差を計算
noise = noisy_image_np - original_image_np
# 信号(元画像)のパワーを計算
signal_power = np.mean(original_image_np ** 2)
# ノイズのパワーを計算
noise_power = np.mean(noise ** 2)
# SNRを計算(10 * log10(signal/noise))
if noise_power == 0:
return float('inf') # ノイズが全くない場合、SNRは無限大
else:
snr = 10 * np.log10(signal_power / noise_power)
return snr
result = transforms.functional.to_pil_image(predicted_image*255)
print("low_res SNR = ", calc_snr(image, low_res))
print("result SNR = ", calc_snr(image, result))
low_res.save("low_res.png")
result.convert("L").save("result.png")U-Netは入力画像→出力画像のペアがあれば学習でき、色々な処理に使えるネットワークですが、今回は超解像処理に使ってみました。学習するデータが少ないにも関わらずそれなりの結果がでたのは驚きです。



