
大規模言語モデル(LLM)パラメータ「temperature, top_k, top_p」について【初級 深層学習講座】
GradCamをPyTorchのforward/backward hookで実装し、判断根拠を可視化する【初級 深層学習講座】

Aru
この記事では、PyTorchを使用してGradCamを実装し、判断根拠や注目領域を可視化する方法を解説します。PyTorchでは、forward_hookとbackward_hookを用いることで、GradCamの計算に必要な中間層の特徴量を抜き出すことが可能です。本記事では、timmライブラリのresnet18モデルを使って、GradCamの具体的な実装手順とそのプロセスを詳しく紹介します。
Contents
GradCAMとは
GradCAMは、画像のクラス分類の分類根拠(判断根拠、注目領域)を可視化するための手法の1つです。一時期は、よく耳にしていましたが、最近は以前ほど聞かなくなりました。とはいえ、注目領域を可視化するのは、モデルの解析で重要です。
最近、GradCAMを使う機会があって調べてみました。これまで、Kerasで実装したことはあったのですがPyTorchでは実装したことがなかったので、実装方法のチェックを兼ねて実装してみました。
とろこで、GradCamについてうまく説明できなかったので、ChatGPTに説明してもらいました。以下、回答です。
GradCAM(Gradient-weighted Class Activation Mapping)は、ディープラーニングの可視化手法の一つです。主に畳み込みニューラルネットワーク(CNN)を用いた画像認識タスクで利用されます。
GradCAMは、ネットワークが特定のクラスを予測するためにどの画像の部分に注目しているかを可視化するために使用されます。これにより、ネットワークの予測にどのような根拠があるのかを理解しやすくなります。
GradCAMは、ネットワークの出力層のクラススコアに関する勾配情報を利用して、各特徴マップの重要性を計算します。この計算により、各ピクセルがネットワークの予測にどの程度寄与しているかが得られます。そして、これらの重要度を元に、元の画像に対する注目度マップ(Attention Map)を生成します。この注目度マップは、予測されたクラスに対して重要な部分を強調します。
GradCAMは、ネットワークがどのようにして特定のクラスを識別するかを視覚的に理解するために非常に役立ちます。これにより、モデルの解釈性を向上させ、モデルの信頼性や説明性を向上させることができます。
Chat-GPTの「GradCAMとは」に対する回答

自分で実装しなくても、「Advanced AI explainability for PyTorch」というライブラリを使えばGradCAMを簡単に使うことが可能です。こちらについては、以下のリンクを参考にしてください。
GradCAMの実装
以下では、GradCAMを実装してみます。利用したモデルはtimmのresnet18です。
必要なライブライのインポート
今回は、以下のライブラリを利用します
import torch
import torch.nn.functional as F
import timm
import cv2
import matplotlib.pyplot as plt
import numpy as np画像の読み込み
モデルに入力する画像の読み込みです。PILを利用して画像を読み込み、リサイズしてtorch.tensorに変換しています(input)。
from PIL import Image
import torchvision
img = Image.open("cat.png")
w, h = img.size
ratio = 224/min(w, h)
w *= ratio
h *= ratio
img = img.resize((int(w+0.5), int(h+0.5)))
img = img.crop((0,0,224,224))
input = torchvision.transforms.functional.to_tensor(img)
plt.imshow(input.permute(1,2,0))
モデルの読み込み
model = timm.create_model("resnet18", pretrained=True)
print(model)print(model)の出力
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act1): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop_block): Identity()
(act1): ReLU(inplace=True)
(aa): Identity()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop_block): Identity()
(act1): ReLU(inplace=True)
(aa): Identity()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop_block): Identity()
(act1): ReLU(inplace=True)
(aa): Identity()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop_block): Identity()
(act1): ReLU(inplace=True)
(aa): Identity()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop_block): Identity()
(act1): ReLU(inplace=True)
(aa): Identity()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop_block): Identity()
(act1): ReLU(inplace=True)
(aa): Identity()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop_block): Identity()
(act1): ReLU(inplace=True)
(aa): Identity()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop_block): Identity()
(act1): ReLU(inplace=True)
(aa): Identity()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
)
)
(global_pool): SelectAdaptivePool2d(pool_type=avg, flatten=Flatten(start_dim=1, end_dim=-1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)モデルの構造を見て、特徴量を取り出す部分を調べます。
Resnetの場合は、layer4がCNNの最後のブロックなので、ここの出力を取り出すことにします。
TIMMの使い方についてはこちらの記事も参考にしてください

PyTorch TIMMでモデル生成・一覧取得の方法(create_modelチートシート)

PyTorch+TIMMでクラス分類(犬猫分類)にチャレンジ
特徴量を取り出すためにhookを設定する
モデルの中間層の特徴量を取り出すために、hookを設定します。hookはforwardで特徴量(feature)を、backwardで勾配(feature_grad)を取り出せます。
以下は、コードです。まず、それぞれのhookに対応する関数を定義し、register関数で登録します。
backwardはregister_full_backward_hookを使います。
feature, feature_grad = None, None
def forward_hook(module, inputs, outputs):
global feature
feature = outputs[0].cpu().detach()
def backward_hook(module, grad_inputs, grad_outputs):
global feature_grad
feature_grad = grad_outputs[0].cpu().detach()
model.layer4.register_forward_hook(forward_hook)
model.layer4.register_full_backward_hook(backward_hook)PyTorchのhookについて
PyTorchでは、register_forward_hookやregister_full_backward_hookを使って、層の状態を取り出すことが可能です。
状態を取り出すことができるのはtorch.nn.Moduleで定義されているモジュールです。関数を定義して登録しておくことで、module、モジュールの入力(input), モジュールの出力(output)にアクセスすることができます。
推論を実行する
推論を実行します。また、backwardを呼び出してバックワードを実行します。
今回は予測結果から、clを設定していますが、正解ラベルyから設定してもOKです。
イメージとしては「クラスclに対する根拠となる特徴量」を視覚化することになります。
pred = model(input.unsqueeze(0))
cl = int(pred.argmax(axis=1))
print(cl)
pred[0][cl].backward()ちなみに、今回利用した画像では、cl=285でした。imagenetのクラスとしては285=Egyptian_catなので、一応クラス分類はうまく動いていそうです。
GradCAMを計算する
GradCAMは、以下のような数式で定義されています(詳しくは論文参照)
$$\begin{eqnarray}
\alpha^c_k = \frac{1}{Z} \sum_i \sum_j \frac{\partial y^c}{\partial A^k_{i,j}}\\
L^c_{Grad-CAM} = ReLU \biggl( \sum_k \alpha^c_k A^k \biggl)\\
\end{eqnarray}$$
$A^k$は特徴量で、$\frac{\partial y^c}{\partial A^k_{i,j}}$は正解がyである場合の勾配情報になります。勾配情報はbackwardで計算されるので、この2つが取り出したfeatureとfeature_gradになります。
$\alpha^c_k$は、各特徴マップの重要度です。
結局、「ある出力を得られた場合に、特徴量のどの部分が寄与したのか」を勾配情報を使って計算しているだけです。最終層のLinerの重み$w$でもわかりそうですが、ここが多段だった場合は画素位置に直すのは面倒そうです。
とりあえず、画像の特徴量として抜き出せる部分がポイントだと感じました。
これを、実装していきます。
b, c, w, h = feature_grad.shape
vec = feature_grad.view(c, w*h)
alpha = torch.mean(vec, axis=1)
feature = feature.squeeze(0)
print("vec:", vec.shape)
# vec: torch.Size([512, 49])
print("alpha:", alpha.shape)
# alpha: torch.Size([512])
print("feature", feature.shape)
# feature torch.Size([512, 7, 7])
L = F.relu(torch.sum(feature*alpha.view(-1, 1, 1), 0))
L = L.cpu().detach().numpy()計算式通りに実装すると上記のようになります。
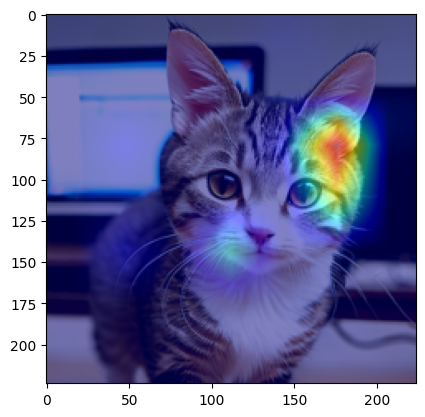
画像に重畳してみる
得られたGradCAMの結果を、画像にマッピングします。Lは小さいので画像と同じサイズに拡大して重ね合わせます。
L_min = np.min(L)
L_max = np.max(L - L_min)
L = (L - L_min)/L_max
c, h, w = input.shape
L = cv2.resize(L, (w, h))
def toHeatmap(x, h, w):
x = (x*255).reshape(-1)
cm = plt.get_cmap('jet')
x = np.array([cm(int(np.round(xi)))[:3] for xi in x])
return x.reshape(h,w,3)
img2 = toHeatmap(L, h, w)
img1 = input.squeeze(0).permute(1,2,0)
alpha = 0.5
grad_cam_image = img1*alpha + img2*(1-alpha)
plt.imshow(grad_cam_image)結果は以下のようになりました。「ここ?」って感じですが、ここを重要視して判断したようです。
その他の実装
今回は、forward_hook、backward_hookを使ってGradCamを実装しましたが、これを使わない実装方法もあるようです。
下記の記事にhookを使わない実装方法が紹介されていました。
この記事のパターンも実装してみました。
model = timm.create_model("resnet18", pretrained=True)
# features, globalpool classifierに分割
from collections import OrderedDict
layers = []
for name, module in model.named_children():
layers.append((name, module))
if name == "layer4" : break
features = torch.nn.Sequential(OrderedDict(layers))
globalpool = model.global_pool
classifier = model.fc
feature = features(input.unsqueeze(0))
feature = feature.clone().detach().requires_grad_(True)
pool = globalpool(feature)
pred = classifier(pool)
cl = int(pred.argmax(axis=1))
print(cl)
# GradCAMを計算
b, c, w, h = feature.shape
vec = feature.grad.view(c, w*h)
alpha = torch.mean(vec, axis=1)
feature = feature.squeeze(0)
print("vec:", vec.shape)
print("alpha:", alpha.shape)
print("feature", feature.shape)
L = F.relu(torch.sum(feature*alpha.view(-1, 1, 1), 0))
L = L.cpu().detach().numpy()
# 画像に重畳
L_min = np.min(L)
L_max = np.max(L - L_min)
L = (L - L_min)/L_max
c, h, w = input.shape
L = cv2.resize(L, (w, h))
def toHeatmap(x, h, w):
x = (x*255).reshape(-1)
cm = plt.get_cmap('jet')
x = np.array([cm(int(np.round(xi)))[:3] for xi in x])
return x.reshape(h,w,3)
img2 = toHeatmap(L, h, w)
img1 = input.squeeze(0).permute(1,2,0)
alpha = 0.5
grad_cam_image = img1*alpha + img2*(1-alpha)
plt.imshow(grad_cam_image)こちらのやり方では、モデルを特徴量を作成する部分と、それ以外のブロックに分割します。具体的にはlayer4手前までの部分を取り出してtorch.nn.Sequenaialでモデル化し、後ろにクラス分類のための完全網(fc)をつける方法です。
この処理を行っているのが以下のコードになります(上のコードから抜粋)。
from collections import OrderedDict
layers = []
for name, module in model.named_children():
layers.append((name, module))
if name == "layer4" : break
features = torch.nn.Sequential(OrderedDict(layers))
globalpool = model.global_pool
classifier = model.fc上半分と下半分を分割することで、中間層の特徴量の出力を取り出すという方法です。
モジュールを名前で取り出す方法
PyTorchでは、named_children()を使って各層を名前で取り出すことが可能です。コードでは、上記の部分が該当します。
for name, module in model.named_children():
...また、OrderdDictに登録してtorch.nn.Sequentialを呼び出すことで、モジュールをつなげたモデルを作成することが可能です。
上記の例では、これを使って入力からlayer4までの部分を切り出しています。
resnetの場合、layer4の下には2つしかモジュールがないのでこちらはまとめていませんが、こちらも同様のやり方でまとめることが可能です。
こちらの方法は、以前、私がkerasでやった実装に近い気がします。
個人的にはhookを使った方が楽だと感じましたが、こちらの方が直感的といえば直感的です。
まとめ
以上、GradCAMをPytorchで実装する方法について解説しました。途中の情報を取り出すという部分が面倒ですが、それ以外の部分はそこまで難しくなかったです。



ディープラーニングに関する記事一覧はこちら

ディープラーニング関連の記事一覧
ABOUT ME

専門分野は並列処理・画像処理・機械学習・ディープラーニング。プログラミング言語はC, C++, Go, Pythonを中心として色々利用。現在は、Kaggle, 競プロなどをしながら悠々自適に活動中



