最適化アルゴリズム:「山登り法」と「焼きなまし法」をPythonで実装
Aru
Aru's テクログ(Aruaru0)

Qwen3-30B-A3Bが登場してからまだそれほど経っていませんが、Alibabaから新たにQwen3-Nextが発表され、MLXで動作するモデルが公開されていたので、早速試してみました。この記事では、MacBook Pro(M4Max, 128GB)で動作させた速度などをレビューします。
Qwen-Nextは、Alibabaの発表によると、1/10のコストでトレーニングでき、従来モデルより高速に動作可能だとされています。
性能的には、Qwen3-235B-A22Bという235Bのモデルと同等性能で、Thinkingモデルについては一部のベンチマークでは、Gemini-2.5-Flash-Thinkingを上回ると書かれています。

Thinkingモデルについては、上位のQwen3-235B-A22B-Thinkingに迫ると書かれているので、235Bのモデルよりは性能が低いみたいです。とはいえ、40Bで235B相当というのは驚きです。
書かれている特徴は以下の通り。他にも特徴はありますが、利用する上では下記の2つかなと思って他は割愛しています(詳しくはこちら)
今回は9/16日にMacで動作するMLX版のQwen-Nextが公開されていましたので、そちらを動作させてみました。公開されているのはInstructで、Thinkingモデルはないようです。個人的にはQwen-30B-A3Bのように/think, /no_thinkをモードを切り替えで使えるモデルが好きなのですが、ここは残念です。
llama.cppで動作するGGUFのモデルは提供されていないみたいです。いまのところ、LMStudioで動かせるのはMacだけのようです。
今回のベンチマークは、以下の環境で行いました。
ダウンロードしたところ、サイズは44.86 GBでした。80Bモデルで40GBクラスということから、4bit量子化されたモデルだとわかります。
以下、ベンチマーク結果です。同じようなMoEモデルとしてOpenAIのgpt-ossを比較対象としました。

| tok/秒 | First Token | |
| Qwen-next-80b | 69.36 tok/sec | 0.19s |
| Qwen3-30B-A3B | 83.25 tok/sec | 0.07s |
| gpt-oss-20b | 81.40 tok/sec | 0.68s |
| gpt-oss-120b | 52.00 tok/sec | 0.40s |
結果を見ると、gpt-oss-20bやQwen3-30B-A3Bといったモデルより遅く、gpt-oss-120bよりは速いというところです。20B・30Bのモデルより遅く、120Bより速いという結果を見ると、80Bモデルとしては妥当といえそうです(同じMoEモデルで比較した場合)。
Qwen-nextのリリースを見る限り、コンテキストが大きい時の速度も高速みたいなことが書かれていたのでコンテキスト(入力)を増やした実験もやってみました。
ロングコンテキスト(入力が大きい)時に、応答の優位性もあるみたいですが、ここは評価していません。品質の良し悪しは主観によるところが大きいので。
芥川龍之介の「羅生門」全文を与えて要約するプロンプトで測定してみました。羅生門全文は日本語で「約6000文字」です。
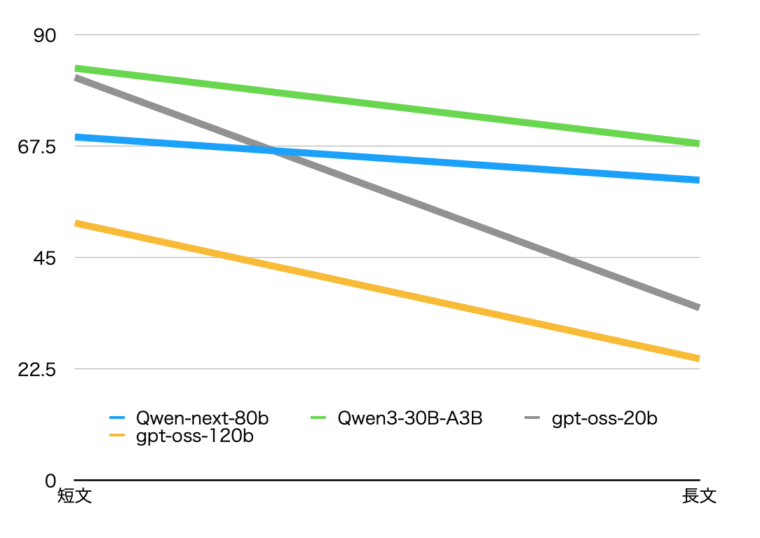
表の速度比は、短いプロンプトと長いプロンプトの速度比率(長いプロンプトのtok/s÷短いプロンプトのtok/s)です。
| tok/秒 | First Token | 速度比 | |
| Qwen-next-80b | 60.63 tok/sec | 15.98s | 1.14 |
| Qwen3-30B-A3B | 68.01 tok/sec | 3.83s | 1.22 |
| gpt-oss-20b | 34.85 tok/sec | 4.73s | 2.34 |
| gpt-oss-120b | 24.57 tok/sec | 9.46s | 2.12 |
これを見るとgpt-ossは、短いプロンプトの時と比べて2倍近く遅くなっていることがわかります。一方、Qwen系は処理速度低下が少なく、Qwen-Nextは14%程度しか低下していないことがわかります。
長文の入力に対しては、gpt-oss-20bより高速だったのは驚きです。
一方、First Tokenの出力までの時間が、他と比べて遅い部分は気になりました。
確かに、長いプロンプトで差が出ています。これは、会話を続けても同じようにプロンプトが長くなるので、対話している間の速度低下も抑えられることを示しています。
品質については、個人の主観によるところが大きいと思うので、あくまで「私の感想」ですが、ちょっとチャットして感じでは、Qwen3-30B-A3Bより洗練された印象です。
また、チャットする範囲では特に小さなモデルだからという感じもありません。
MCPでGoogle Searchを使うように設定すれば、最新情報をWebから取得して回答できるため、クラウドサービスを利用しているのと大差ない感覚で使えます。
とりあえず、競技プログラミングの問題としてAtCoder ABC-423E問題を解かせてみましたが、正しそうな回答を出力しました(「正しそう」と表現している理由は、解法が正いこととプログラムを目視で確認しただけで実際にACしているわけではないため)。推論モデルではないので厳しいかと思いましたが、サクッと回答したのは意外でした。
試した問題が数学より(=生成AIが得意)だったので、解答できた感じがします。
最近は、時間がかかっても推論が必要な場合はgpt-oss-120b、ちょっとした要約などの依頼は、gpt-oss-20bを使っていましたが、またQwenを使いそうです。特に、長文を入力した際のレスポンスの良さは大きなメリットだと感じました。




