
LMStudioで外部ツールを呼び出す方法|Tool Use対応モデルの使い方
Aru
Aru's テクログ(Aruaru0)

2024年3月21日、Rakutenから新たに大規模言語モデルが発表されました。今回は、楽天が発表したRakutenAI-7B-chatモデルを使ってチャットボットを作成してみました。この記事では、RakutenAIの使い方と、Gradioを使ったチャットボットの作成手順を解説します。Gradioは、インタラクティブなGUIを簡単に作成できるツールで、AIモデルのデモやプロトタイプに最適です。

Rakuten AIはMistral AI社のオープンモデル「Mistral-7B-v0.1」を基に、継続的に大規模なデータを学習させて開発された70億パラメータの日本語基盤モデルです。
提供されたのは、ベースモデル、インストラクション、チャットの3つです。
この3モデルとも商用目的で使用することができるということです。
今回は提供されている3つのモデルの中から、RakutenAI-7B-chatを使ってチャットボットを作ってみました。

国内メーカーが発表する日本語モデルは、Mistralベースのモデルが多い印象です。
LLMの推論プロセスについては以下の記事でわかりやすく説明しています。気になる方は参考にしてください。

Google Colabで試す場合は、以下のパッケージをインストールしてください。
今回は、gradioを使ってGUIアプリを作るので、gardioもインストールします。
!pip install -q accelerate
!pip install gradioGoogle Colabで動作するコードはこちらにあります
とりあえず、RakutenAIを動かしてみます。コードのベースは、HuggingfaceのRakutenAI-7B-chatのコードですが、一部修正を加えています。
以下、モデルの生成です。Google ColabのT4(GPU)で動かすと少し遅く、出力されるまでイライラするので、途中経過が出力されるようにstreamerを用います。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
MODEL_NAME = "Rakuten/RakutenAI-7B-chat"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,
device_map="auto",
torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
model.eval()この部分は、モデルのページにあるサンプルとほぼ同じです。異なるのはstreamerをパラメータとして渡してているところくらいです。
メッセージのフォーマットをみると、最初にシステムメッセージがあって、USER:、ASSISTANT:という形で会話を入力するようです。これを参考にして、Gradioを使ったサンプルではプロンプトを作成します。
requests = [
"「馬が合う」はどう言う意味ですか",
"How to make an authentic Spanish Omelette?",
]
system_message = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {user_input} ASSISTANT:"
for req in requests:
input_req = system_message.format(user_input=req)
input_ids = tokenizer.encode(input_req, return_tensors="pt").to(device=model.device)
tokens = model.generate(
input_ids,
max_new_tokens=1024,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
streamer = streamer
)
out = tokenizer.decode(tokens[0][len(input_ids[0]):], skip_special_tokens=True)
print("USER:\n" + req)
print("ASSISTANT:\n" + out)
print()
print()1つ目の質問の結果は以下のようになります。
USER: 「馬が合う」はどう言う意味ですか
ASSISTANT: 「馬が合う」は、相性が良い、息が合う、協力しやすい、といった意味を持つ成句です。馬に乗る際には、馬との息を揃えなければならないため、「馬が合う」という成句は、相手と息が合う、協力しやすいといった意味で使われます。「二人(ふたり)で馬を借りたなら、馬が合うようにすまえ」という諺があるように、うまくいくためには相性と息が合うことが重要だとされています。ビジネスの世界でも、上司と部下の馬が合わなければ、仕事でうまく進まず、良好な関係を維持することが難しくなってしまいます。
提供されているサンプルなので、それなりの回答になっていると思います。
チャットアプリ作成については、以下の記事を参考にしました。
Gradioを使ってチャットアプリを作成する方法は公式を含め多数ありますが、ストリーム生成を使ったサンプルは少なかったです。

モデルの生成は、先ほどとほぼ同じですが、ストリーマーにTextIteratorStreamerを使っている部分が異なります。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TextIteratorStreamer
MODEL_NAME = "Rakuten/RakutenAI-7B-chat"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,
device_map="auto",
torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
model.eval()入力されたメッセージと会話のヒストリに基づいてプロンプトを作成する関数を作成します。
この関数では、RakutenAIのプロンプトフォーマットに合わせた出力が行われます。なので、他のモデルを使う場合は、ここを変更する必要があります。
SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。\n"
def compose_prompt(message:str, history:list[list[str]]) -> str:
prompt = f"{SYSTEM_PROMPT}"
if len(history) == 0:
prompt += f"USER:{message}\nASSISTANT:"
return prompt
else:
for pair in history:
[user, assistant] = pair
prompt += f"USER: {user} \nASSISTANT:{assistant} <|endoftext|>\n"
prompt += f"USER:{message}\nASSISTANT:"
return prompt
# プロンプトを確認
prompt = compose_prompt("日本で一番高い山は?", [["一番長い川は?", "信濃川です"]])
print(prompt)モデルによってはチャットテンプレートを使ってプロンプトを作成できるモデルもあります。チャットテンプレートの使い方については以下を参考にしてください。

ストリーマーを作成します
from threading import Thread
async def gen_stream(prompt: str) -> TextIteratorStreamer:
input_ids = tokenizer(prompt, return_tensors="pt").to(device=model.device)
# print(prompt, input_ids)
config = dict(
**input_ids,
max_new_tokens=512,
streamer=streamer,
pad_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.5,
)
thread = Thread(target=model.generate, kwargs=config)
thread.start()
return streamer最後にGUIを作成します。chat関数は、プロンプトを作成してRakutenAIで返答を生成し、これをレスポンスとして返す関数です。
あとは、ChatInterfaceを呼び出すだけです。チャットボット向けのインタフェースが用意されているのでGUIを作るのは簡単です。
import gradio as gr
async def chat(message: str, history: list[list[str]]):
prompt = compose_prompt(message, history)
st = await gen_stream(prompt)
total_response = ""
for output in st:
if not output:
continue
total_response += output
yield total_response
demo = gr.ChatInterface(chat).queue()
demo.launch(share=True)gradioで動かすと、どんなエラーが発生したかわからないので苦労しました。それぞれの関数(compose_prompt、gen_stream)を個別にテストしてからgradioで動かした方がよいです。
実行結果は以下のような感じです。いい感じで動作させることができました。
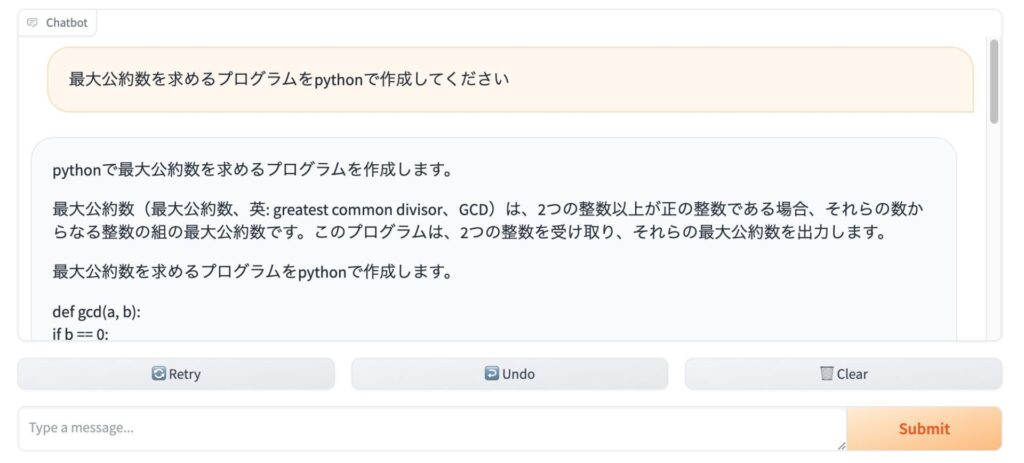
プログラムのテストをしているときに「日本で一番高い山は?」とたずねたところ、すごく長い、くどい返答をしてきました。
テストで使った「「馬が合う」はどう言う意味ですか」の回答も少し長い気がしますので、そいう傾向があるのかもしれません。
丁寧なのはいいですが、アシスタントしてはもっと簡潔に答えて欲しかったりします。
system_messageでコントロールできる可能性もありますが、すこし変更してみた範囲ではあまり変化ありませんでした。
とりえあず、RakutenAIをうごかしてみました。いろいろなモデルが発表されていますが、どれも似たり寄ったりな気もします。確かにベンチマークは違うかもしれませんが体感ではそこまで違いを感じませんでした。



