


LMStudioに実装された「投機的デコーディング」を試す(LLM)
Aru
Aru's テクログ(Aruaru0)

この記事では、Meta社のSegmentation Anything Model(SAM)を使用したゼロショットセグメンテーションの実装方法について解説します。ゼロショットセグメンテーションは、学習なしでオブジェクトのセグメンテーションを実現するモデルです。本記事では、サンプルコードを使ってSAMの使い方を解説します。また、実際にSAMを使ってみた感想も加えました。
SAMの高速版FastSAMの使い方については以下の記事を参照してください

Segmentation Anything Model(SAM)は、Meta AIが開発した、画像内のオブジェクトを識別できるAIモデルです。
SAMは、1100万枚の画像とそれに付随した10億以上のマスクからなるデータセットで訓練されています。SAMの特徴は、ゼロショットでのセグメンテーションで、SAMでは学習していない画像やオブジェクトでも、高い精度でセグメンテーションを行うことができます。
今回は、SAMを実際に動かしてみて、実力をチェックしてみました。
Segment-Anythig
GitHub: https://github.com/facebookresearch/segment-anything
Google Colabで動作するコードをこちら(Github)に用意しました
Google Colabでインストールする場合は以下のように記述します。ローカルでインストールする場合は、先頭の!を外してコマンドラインで実行してください。
wgetでダウンロードしているのは、学習済みのパラメータです。
モデルパラメータは、ここからダウンロードできます。以下の3つが用意されていますが、今回はvit_hを使いました。

!pip install 'git+https://github.com/facebookresearch/segment-anything.git'
!wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth以下はヘルパー関数の定義です。
show_mask, show_points, show_boxは結果のビジュアライゼーションのための関数で、公式のチュートリアルにあるものです。
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0,0,0,0), lw=2))画像を読み込みます。今回利用したcat2.pngは、こちらからダウンロードできます。Google Colabの場合は、以下のコードを実行してください。
!wget -O cat2.png https://github.com/aruaru0/SAM-TEST/blob/main/cat2.png?raw=true 以下のコードを実行すると、画像が読み込まれ表示されます。
image = cv2.imread('cat2.png')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(5,5))
plt.imshow(image)
plt.axis('on')
plt.show()

(x, y)の座標が表示されているので、これを使って、後で説明する点や矩形の指定が可能です。独自の画像でテストする際に参考にしてください。
画像中の1箇所の点を指定して、セグメンテーションする例です。
学習済みモデルの読み込みと、SamPredictorの生成、対象画像の設定を行っています。
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictor
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
predictor.set_image(image)次に、画像中の点を指定します。input_pointが画像中の点のリスト、input_labelが1の点は選択する点となります(ラベルに0を指定すると指定した点を除外する設定になります)。
input_point = np.array([[200, 200]])
input_label = np.array([1])
plt.figure(figsize=(5,5))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()点の場所を画像に重ねると、以下のようになります。

次のコードで、予測を行います。point_coordsに指定する点のリストを、point_labelsに0/1のラベルのリストを入力します。
今回は、複数マスク出力を行うので、multimask_output = Trueを指定しています。これにより信頼度の高い3つのマスクが出力されるようになります。
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)結果が、mask, scores, logitsに格納されます。
以下のコードはmask, scoreを可視化するものです。
for i, (mask, score) in enumerate(zip(masks, scores)):
plt.figure(figsize=(5,5))
plt.imshow(image)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"Mask {i+1}, Score: {score:.3f}", fontsize=18)
plt.axis('off')
plt.show()


logitsは、predict()のinput_maskパラメータの入力として利用できます。最もスコアの高いマスクを選択は、以下のコードで書けます。
best_mask = logits[np.argmax(scores), :, :] これを、以下のようにpredictの引数に指定することができます。
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
mask_input=mask_input[None, :, :],
multimask_output=False,
)
候補を出力せずに、マスクを1つだけ出力したい場合には、multimaks_output = Falseにします。
input_point = np.array([[120, 120]])
input_label = np.array([1])
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=False,
)
plt.figure(figsize=(5,5))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()上のコードを実行すると「耳の部分」が選択されます。

次の説明に繋げるために、耳だけが選択されるように、指定する点をずらしています。

★の位置で選択が変化するのは、場合によっては問題かも
1点指定では、耳だけしか選択されなかったので追加で、もう1点してしています。
2点目の追加は、input_point, input_labelに2点目の情報を追加するだけです。
input_point = np.array([[120, 120], [300, 450]])
input_label = np.array([1, 1])
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=False,
)
plt.figure(figsize=(5,5))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()2点指定することで、猫がセグメンテーションされました。

選択する点だけでなく、除外する点も指定することができます。除外する点はinput_labelに0を設定すればOKです。
ここでは、右足の部分を除外しています。
input_point = np.array([[120, 120], [300, 450], [200, 600]])
input_label = np.array([1, 1, 0])
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=False,
)
plt.figure(figsize=(5,5))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()すると、以下のようなマスクになります。

想像と少し違うセグメンテーションになりました。このあたりのコントロールは難しそうです。
領域を指定してセグメンテーションを行うこともできます。領域を指定する場合は、以下の情報を与えます。
[ 始点のx座標、始点のy座標、終点のx座標、終点のy座標 ]
以下が、矩形領域を指定してセグメンテーションするコードです。
input_box = np.array([0, 250, 200, 768])
masks, _, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box[None, :],
multimask_output=False,
)
plt.figure(figsize=(5, 5))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
plt.axis('off')
plt.show()緑枠の部分を指定すると、机とテーブルが選択されました。

点の指定と同様に、複数の枠を指定してセグメンテーションを行うこともできます。下記の例は、3つの矩形を指定した例です。
input_boxes = torch.tensor([
[0, 250, 150, 600],
[50, 50, 400, 650],
[80, 550, 512, 768]
], device=predictor.device)
transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes, image.shape[:2])
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
plt.figure(figsize=(5, 5))
plt.imshow(image)
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box in input_boxes:
show_box(box.cpu().numpy(), plt.gca())
plt.axis('off')
plt.show()枠を3つ指定したので、3つのマスクが出力されています。それぞれ、猫、椅子、本の部分です。
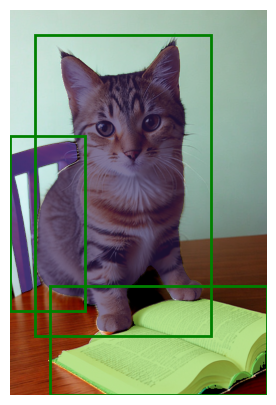
この例では、選択したかったものがうまく選択されマスクが生成されました。
矩形と点を組み合わせて領域を選択することも可能です。以下の例では、矩形と、除外する点を指定しています。
input_box = np.array([0, 250, 200, 768])
input_point = np.array([[20, 700]])
input_label = np.array([0])
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
box=input_box,
multimask_output=False,
)
plt.figure(figsize=(5, 5))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()
SAMでは、画像全体を自動的にセグメンテーションさせることもできます。ここでは、画像全体のセグメンテーションを行ってみます。
全体のセグメンテーションには、SamAutomaticMaskGeneratorを使います。
パラメータ指定により細かな設定が可能です。パラメータについては、こちらのブログが参考になります。
今回はpred_iou_threshを0.98に設定しました。
コメントアウトしているpoints_per_sideを大きくすると、より細かく画像を見るようになりますが、処理は重くなります。
画面にグリッドを作って、各点が指定されたとしてセグメンテーションをしているような感じです。points_per_sideで、グリッドを増やすと、それだけ処理がかかります
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator_ = SamAutomaticMaskGenerator(
model=sam,
pred_iou_thresh = 0.98,
# points_per_side = 32,
)
masks = mask_generator_.generate(image)
print(len(masks))この例では、12個のセグメントが見つかりました。閾値次第で、マスクの数は変化しますので、色々閾値を変化させて実行してみるのも面白いかもしれません。
12描画用のヘルパー関数です。
import torch
import numpy as np
import matplotlib.pyplot as plt
import torchvision.transforms.functional as F
plt.rcParams["savefig.bbox"] = 'tight'
def show(imgs):
if not isinstance(imgs, list):
imgs = [imgs]
fig, axs = plt.subplots(ncols=len(imgs), squeeze=False)
for i, img in enumerate(imgs):
img = img.detach()
img = F.to_pil_image(img)
axs[0, i].imshow(np.asarray(img))
axs[0, i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])結果を表示しています。
from torchvision.utils import draw_segmentation_masks
n = len(masks)
m = 3
flg, axes = plt.subplots(nrows = (n+m//2)//m, ncols = m, tight_layout=True, figsize=(3*m, 2*(n+m//2)//m))
for i in range(len(masks)) :
img = torch.tensor(image).permute(2,0,1)
mask = torch.tensor(masks[i]['segmentation'])
x = draw_segmentation_masks(img, mask, colors="yellow")
axes[i//m, i%m].imshow(x.permute(1,2,0))
axes[i//m, i%m].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
px, py = masks[i]['point_coords'][0]
input_point = np.array([[int(px), int(py)]])
input_label = np.array([0])
show_points(input_point, input_label, axes[i//m, i%m], marker_size=100)
# if i == 6 : break
plt.show()★の点が選択された点、黄色い部分が生成されたマスクです。1枚目と2枚目が猫で、若干2枚目の方が境界部分が綺麗にマスクされているように見えます。2枚目は壁でしょうか。
選択に納得がいくものと、微妙な感じのものが混ざっている感じです。

画像に重畳させずにマスクだけ表示させたのが次の結果になります。
n = len(masks)
m = 3
flg, axes = plt.subplots(nrows = (n+m//2)//m, ncols = m, tight_layout=True, figsize=(3*m, 2*(n+m//2)//m))
for i in range(len(masks)) :
x = torch.tensor(masks[i]['segmentation']).float()
axes[i//m, i%m].imshow(x)
axes[i//m, i%m].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
# if i == 10 : break
plt.show()

SAMの利用方法としては、点や矩形を指定して領域内の物体を抽出するのがメインとなるのではないでしょうか。
例えば、フォトレタッチソフト(Photoshopなど)のように、画像内のオブジェクトを選択して、不要なオブジェクトを除去したり、必要なオブジェクトを強調したりする目的には使いやすそうです。
また、学習用のアノテーションデータの作成などにも使えそうです。この場合は、中央に写っているオブジェクトを選択するようにして、回転台などでオブジェクトを回転させれば、簡単にオブジェクトだけを切り出して、各方向からみたデータのアノテーションを行えそうな気がします。
場所を選択して、切り出すという用途には色々使えそうです。
逆に画像全体の自動的なセグメンテーションについては、利用が難しそうです。
というのも、セグメントを抽出したあとに、目的の部分を探すのに苦労しそうだからです。例えば、今回の場合で、「本」を取り出したい場合、本のセグメントは11枚目です。
「検出されたセグメントから目的のオブジェクトのセグメントをどうやって見つける」かというのは課題になりそうです。
また、動画の場合、毎回同じマスクに目的のオブジェクトのセグメントが出現するかもわかりません。毎回違う場所に出現する目的のセグメントをどうやって見つけるのかも問題になりそうです。
自動的なセグメンテーションを利用する場合は、別途、クラス分類や、追跡などと行ったアルゴリズムとの組み合わせが必要となるかもしれません。
追跡、クラス分類などと組み合わせるのであれば、ゼロショットのセグメンテーションでなく、セグメンテーションのモデルをファインチューニングさせた方が良い気もします。
直感的に、高精度のセグメンテーションが求められるアプリケーションに適応させるのは苦労するかもしれません。
以上、Meta社のSAMの使い方を解説しました。
ゼロショットを前提としているので今回はトレーニングはしていません。公式の資料も見つけられなかったのでファインチューニングが可能かどうかも確認できまてませんが、そもそもチューニングなしで使うことを前提としているモデルのような気もします。


{kind=link}