
Google ColabでGUI|gradioを利用したウェブアプリの作り方を解説
Aru
Aru's テクログ(Aruaru0)

Kaggleのコンペティションでは、表形式データ(テーブルデータ)に対する予測手段として「TabNet」を目にすることがあります。この記事では、TabNetを用いた回帰問題の解き方を、具体例を交えながら詳しく解説します。本記事では、使い方を中心に解説しますので、詳しいアーキテクチャについては論文等を参照してください(arXiv:1980.07442)
TabNetでクラス分類を行う方法については以下の記事を参照してください

TabNet(Tabular Neural Network)は、ディープニューラルネットワーク(DNN)の一種で、名前の通り「表形式のデータ(タブラーデータ)」を処理するために設計されたモデルです。
DNNは通常、画像やテキストの処理に使われることが一般的ですが、TabNetは表形式のデータに焦点を当て、その特有の特性に適したネットワーク構造とトレーニング手法を提供します。
TabNetは、以下の主な特徴を持っています

TabNetの概要として書かれているものをピックしてみましたが、Attention機構以外いまいちピンときていません。
今回利用したのは、TabNetのPytorch実装です。リンクは以下になります。
ソースコード(github): https://github.com/dreamquark-ai/tabnet/tree/develop
ドキュメント: https://dreamquark-ai.github.io/tabnet/index.html
READMEを読むと、ライブラリの改善のために、論文とは異なる部分が存在する可能性があるそうです。
なお、Google Colab上で動作するコードをここに置いています。
インストールはpipで行うことができます。以下のコードをコマンドラインより実行してください。
pip install pytorch-tabnetGoogle Colabなどで試す場合は、!を先頭につけてセルに入力し実行してください。
!pip install pytorch-tabnet今回のコードで利用するライブラリをインポートしておきます。
numpy, pandas, matplotlib…と、この手の実験を行う場合にお馴染みのライブラリになります。なお、tabnetの引数にpytorchの関数を渡しますので、torchもインポートしておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from pytorch_tabnet.tab_model import TabNetRegressor
from pytorch_tabnet.pretraining import TabNetPretrainer
import torch評価用のデータセットは、scikit-learnのmake_regressionを利用して作成します。
make_classificationについては以下の記事を参考にしてください

X, Y, coef = make_regression(
random_state=42,
n_samples=10000,
n_features=10,
n_informative=5,
noise=1,
bias=1.0,
coef=True)作成されたデータは、回帰問題のデータセットで、10個の特徴量を備えたものになります。n_formativeを5としたので、目的変数と相関を持つ特徴量は5つになります。
これは、coefで確認できます。
以下のコードで特徴量の影響度合いを確認します。
for i, c in enumerate(coef):
print(f"feature {i} : {c}")結果をみると1,3,5,7,9番の特徴量が目的変数と相関があり、9→3→7→1→5の順で計数が大きいことがわかります。
出力結果
feature 0 : 0.0
feature 1 : 19.365117777553486
feature 2 : 0.0
feature 3 : 68.28011328758366
feature 4 : 0.0
feature 5 : 8.88918861576965
feature 6 : 0.0
feature 7 : 29.506960083972224
feature 8 : 0.0
feature 9 : 78.46795175040386TabNetにカテゴリデータを入力する場合には、エンコードして数値データに変換する必要があります。カテゴリデータに変換する方法は、以下の記事を参考にしてください。

TabNetに特徴量がカテゴリ変数であることを伝えるには、以下の引数を利用します
cat_idxs | カテゴリ変数の列のインデックスのリスト |
cat_dims | 各カテゴリ変数のカテゴリ数のリスト |
cat_emb_dim | 各カテゴリ変数の埋め込みサイズのリスト |
ここでは、 train:valid:test=0.7:0.15:0.15に分割します。また、y_train, y_valid, y_testをn行1列のデータに変換します。
train_rate, val_rate, test_rate = 0.7, 0.15, 0.15
X_train, X_test, y_train, y_test = train_test_split(X, Y, train_size=train_rate, random_state=42)
X_valid, X_test, y_valid, y_test = train_test_split(X_test, y_test, test_size=test_rate/(test_rate+val_rate), random_state=42)
y_train = y_train.reshape(-1, 1)
y_valid = y_valid.reshape(-1, 1)
y_test = y_test.reshape(-1, 1)事前学習を行う場合は、TabNetPretrainerを使って行います。教師なし学習なので、y_train, y_validを渡さないことに注意してください。
今回の例では、事前学習をした方が結果が良かったです。クラス分類の場合は、事前学習をしない方が良かったので、事前学習した方がよいとは一概に言えないようです。
unsupervised_model = TabNetPretrainer(
optimizer_fn=torch.optim.Adam,
optimizer_params=dict(lr=2e-2),
mask_type='entmax'
)
unsupervised_model.fit(
X_train=X_train,
eval_set=[X_valid],
pretraining_ratio=0.8,
max_epochs = 100,
)学習コードはscikitlearnのインタフェースに似ているので、lightGBMやXGBoostなどを使ったことがある方はわかりやすいのではないかと思います。
各パラメータについては、公式ドキュメントを確認してください。
パラメータについては、PyTorchを使ってDNNの学習をしたことがあるのであれば迷わないかと思いますが、とりあえずデフォルトでよいと思います。
以下のソースコードでコメントアウトしている行のコメントを外せば、上で説明した事前学習の結果を使って学習が行われます。
tabnet_params = {
"optimizer_fn":torch.optim.Adam,
"optimizer_params":dict(lr=2e-2),
"scheduler_fn":torch.optim.lr_scheduler.ReduceLROnPlateau, #torch.optim.lr_scheduler.StepLR,
"mask_type":'entmax',
}
model = TabNetRegressor(**tabnet_params)
max_epochs = 100
model.fit(
X_train=X_train, y_train=y_train,
eval_set=[(X_train, y_train), (X_valid, y_valid)],
eval_name=['train', 'valid'],
eval_metric=['rmse'],
max_epochs=max_epochs , patience=20,
batch_size=1024, virtual_batch_size=128,
num_workers=0,
drop_last=False,
augmentations=None,
from_unsupervised=unsupervised_model
)学習は遅いです。GPUを使ったら多少は高速になりますがLightGBMと比較するとかなり遅いです。
大規模データの場合は、学習結果をセーブ(clf.save_model(ファイル名))して、ロード(clf.load_model(ファイル名))して使う感じになりそうです。
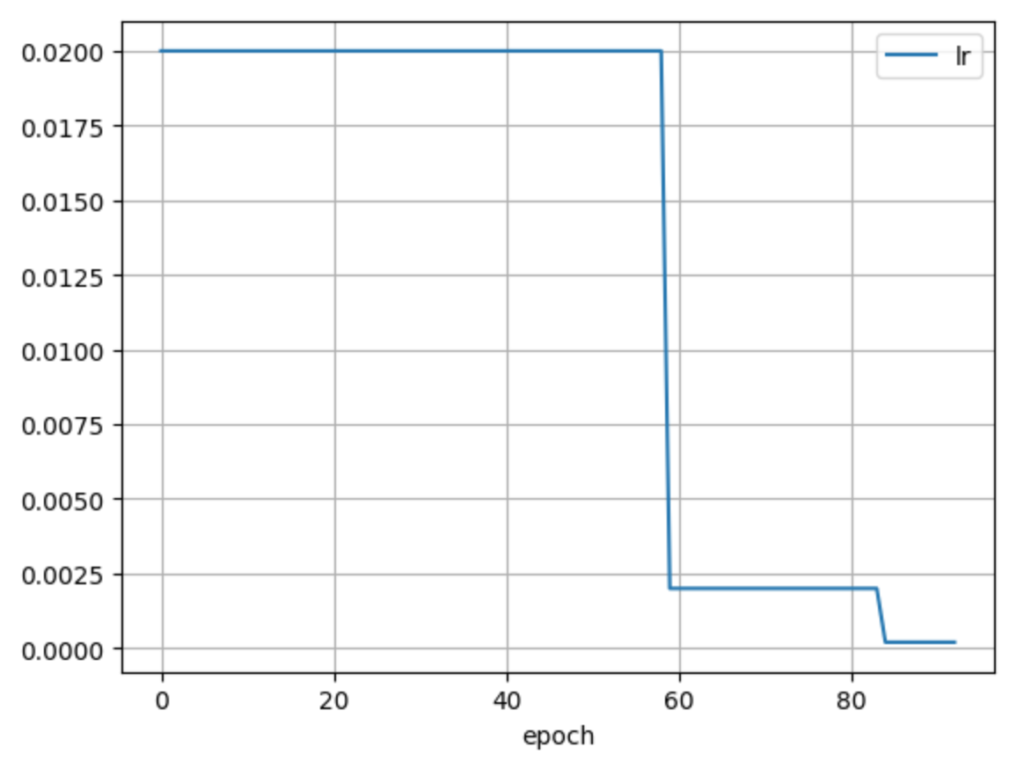
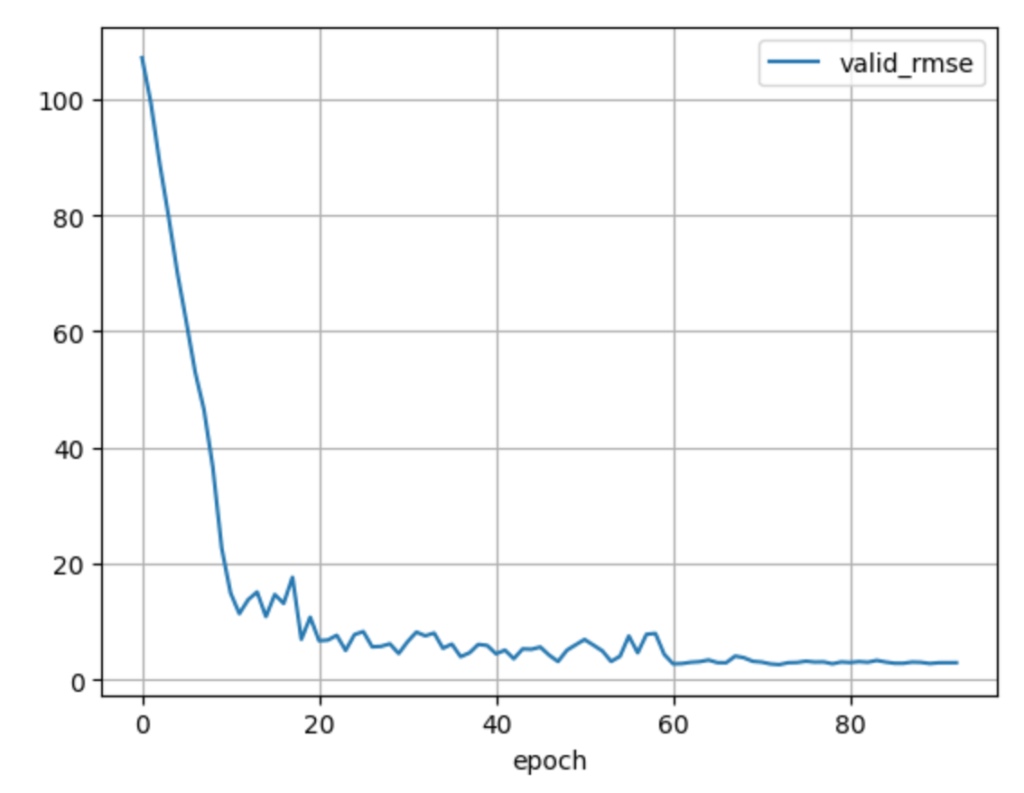
学習が完了したら、結果を確認してみます。valid_rmseがそれなりに収束していることが確認できると思います。
import matplotlib.pyplot as plt
for param in ['loss', 'lr', 'valid_rmse']:
plt.plot(model.history[param], label=param)
plt.xlabel('epoch')
plt.grid()
plt.legend()
plt.show()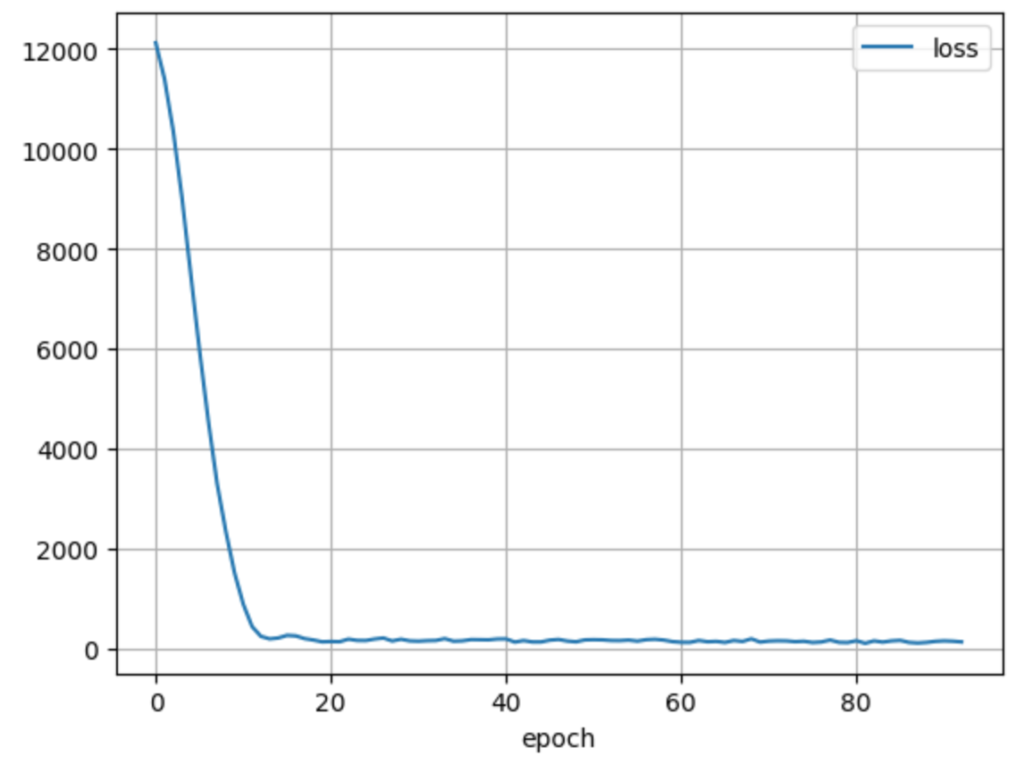
以下のコードで、検証データ、テストデータに対する予測ができます。
preds = model.predict(X_test)
test_mse = mean_squared_error(preds, y_test)
preds_valid = model.predict(X_valid)
valid_mse = mean_squared_error(preds_valid, y_valid)
print("valid_mse = ", valid_mse)
print("test_mse = ", test_mse)結果を見ると、test_mseで5.320とまずまずの結果であることがわかります。
実行結果
valid_mse = 6.746282744729993
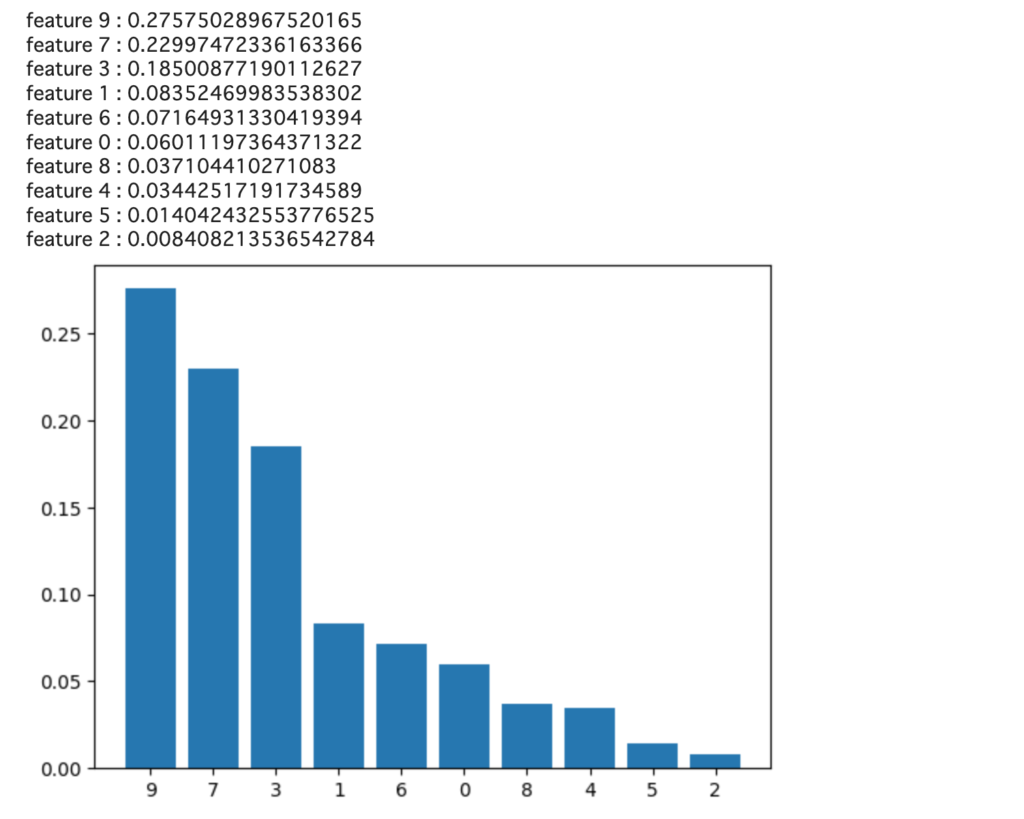
test_mse = 5.320123732256637TabNetでも、LightGBMなどと同様に特徴量の重要度を確認することが可能です。
importance = sorted([(i, n) for i, n in enumerate(model.feature_importances_)], key = lambda x: x[1], reverse = True)
label, y = [], []
for e in importance:
print(f"feature {e[0]} : {e[1]}")
label.append(e[0])
y.append(e[1])
plt.bar([i for i in range(len(y))], y, tick_label = label)
plt.show()結果を見ると9→7→3→1→6…の順に重要度が高いと結果となったようです。
目的変数と相関のある特徴は、1、3、5、7、9なので、5は無視されたように見えます。5は、もともとcoefも小さかったのでノイズに紛れたのかもしれません。
また、9、7、3の3つの特徴量が主に推論に使われたこともわかります。この3つはcoefが大きな3つと一致していますので、うまく特徴量が選択されたと解釈できます。
比較のために、LightGBMでも予測してみました。
from lightgbm import LGBMRegressor
lgb_params = {
'n_estimators': 10000,
'learning_rate': 0.01,
'random_state': 42,
'early_stopping_round': 100,
'metric': 'rmse'
}
lgb = LGBMRegressor(**lgb_params)
lgb.fit(X_train, y_train, eval_set=[(X_valid, y_valid)])preds = lgb.predict(X_test)
test_mse = mean_squared_error(preds, y_test)
preds_valid = lgb.predict(X_valid)
valid_mse = mean_squared_error(preds_valid, y_valid)
print("valid_mse = ", valid_mse)
print("test_mse = ", test_mse)結果はtest_mseで48.51と、かなりTabNetに劣る結果となりました。
実行結果
valid_auc = 48.71907754640076
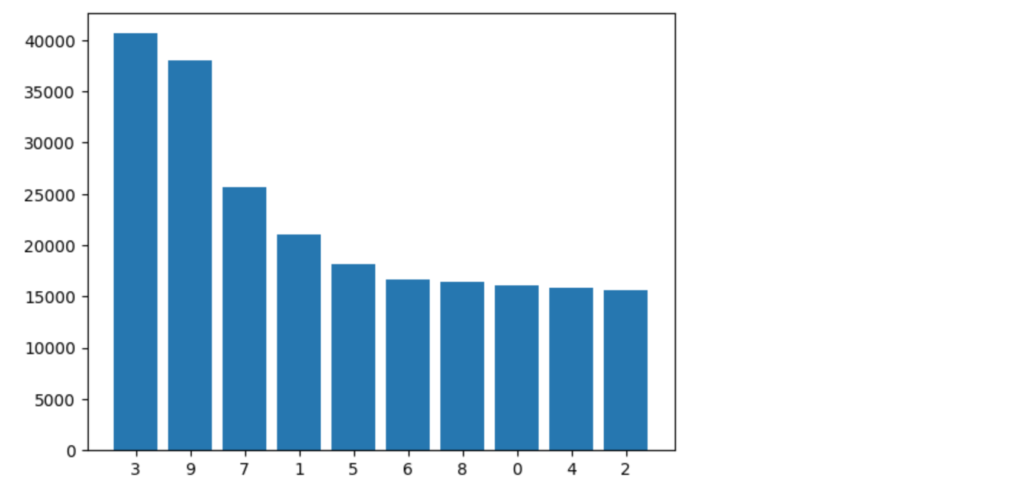
test_auc = 48.513214953676204LGBMの特徴量の重要度は以下のようになります。こちらは、3→9→7→1→5…の順となっています。
特徴量の選択は、LGBMの方が正しいようです。ただ、相関の無い0、2、5、6、8もそれなりに重要視していているため、ノイズ成分の影響を受けたと考えられます。
TabNet単体で利用するのもよいと思いますが、個人的な興味はLightGBMやCatBoostなどとのアンサンブルでしょうか。
最近人気のCatBoost, LightGBM, XGBoostはどれも勾配ブースティングを用いたものです。似たようなアルゴリズムをアンサンブルするより、異なるアルゴリズムの学習器をアンサンブルした方が良い結果が得られそうなので、TabNetはその選択肢の1つとなりそうです。



