
大規模言語モデル(LLM)パラメータ「temperature, top_k, top_p」について【初級 深層学習講座】
LLM(大規模言語モデル)の仕組みを分かりやすく解説|推論処理を理解しよう

Aru
複雑そうに見えるChatGPTなどのLLM(大規模言語モデル)ですが、動作の基本を理解するだけであればそこまで難しくありません。そこで、この記事では、LLMが文章を生成するプロセスについて初心者でもわかりやすく解説します。
大規模言語モデル(LLM)とは
大規模言語モデル(LLM:Large Language Model)は、大量の文章を学習し、言葉の理解や生成を行うディープラーニングによって構築された言語モデルです。大規模という名前が示すように、数百万から数十億ものパラメータを持ち、大量のデータを使って学んでいる点が、従来の言語モデルと大きく異なります。
このLLMは、例えば以下のようなサービズで利用されています。
- カスタマーサポートのチャットボット
- 文章の作成・校正
- 文章の要約
- 文章の校正
- プログラミングのアシスタント(コード生成、バグチェックなど)
既にさまざまな分野で使われているLLMですが、今後はさらに広い用途での活用が期待されています。
LLMの基本的な機能は、入力されたテキストの文脈を理解し、それに基づいて文章を生成するというものです。
実際には、LLMはどのように応答を生成しているのでしょうか?
この記事では、LLMが応答を生成する流れについて、わかりやすく概要を解説したいと思います。
LLMがどういった流れで文章を生成するのかを理解する助けになればと思います。
LLMの応答の生成の流れ
文章生成の流れ
大規模言語モデルは、入力された文章に続く単語を予測するプロセスを繰り返して応答を生成します。具体的には、以下のような処理になります。
大規模言語モデルでは、いきなり文章を生成しているのではなく、入力された文章に続く「単語」を予測するプロセスを繰り返して応答を生成しています。
- 入力の受け取り
ユーザーからの入力(プロンプト)を受け取る - 次の単語の予測
入力の最後の単語やフレーズに続く単語を予測します。具体的には、入力に続く最も適切な単語を確率的に予測します。つまり、学習した大規模なテキストデータに基づいて統計的にどの単語が次に来るのかを推測していることになります。 - 単語の追加
予測した次に来そうな単語を、入力された文章につなげて新しい入力を作ります - 繰り返し
作成した新しい入力(元のプロンプトに予測された単語を追加したもの)で②〜③を繰り返します。
上記の処理を続けていくうちに、応答文章を生成することができます。最終的には、ユーザーからの入力を除いた、生成した部分の単語列(文章)を出力します。

質問に対する回答も同じ原理です。
基本的には「〜について教えてください」という文章に続く単語を予測しているだけです。
チャット時の入力について興味がある方は以下の記事を確認してみてください。

HuggingFaceの大規模言語モデル(LLM)のチャットテンプレートの使い方
具体例
上記の動作を具体例で説明すると、以下のようになります。
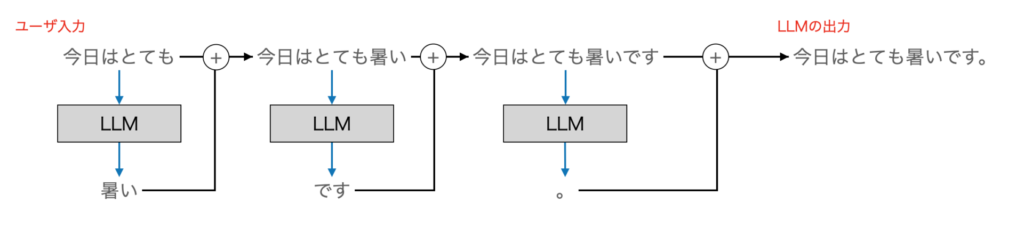
- ユーザー入力:「今日はとても」
- 次の単語の予測:「暑い」
- 新しい入力:「今日はとても暑い」
- 次の単語の予測:「です」
- 新しい入力:「今日はとても暑いです」
- 次の単語の予測:「。」
上記を図示したものが下の図になります。最初の入力は「今日はとても」です。LLMはこれに続く単語を予測します。例では「暑い」を次の単語として予測しています。
次に、「今日はとても暑い」の次の単語を予測します。ここでは、「です」を予測し、これを続けて「今日はとても暑いです」という文章を生成しています。
このように、「次の単語を予測して繋げる」という処理を繰り返し行うことで文章を生成するのがLLMです。
生成のまとめ
ここで説明したように、LLMでは予測された単語を次々と結合して、最終的な応答を生成します。極論すると、確率的に単語を選んで連結しただけです。しかしながら、モデルが大規模なデータを学習しているため、自然な文章を生成できるわけです。
文章入力から予測までの詳しい説明
次の単語の予測(より詳しい説明)
ここでは、予測手順を技術的な用語を使いながら解説したいと思います。
- トークン化
入力文を最小単位に分別し、トークン(番号)に変換します - LLMでの予測
- トークン(番号)をベクトルに変換
- 各トークン間の関連性を計算
- 特徴量を抽出
- 特徴量から次の次のトークン(番号)を予測
- 次のトークンと確率を出力
- 確率に基づいてトークンを選択し、トークン(番号)を文字に変換
- 文字列を出力
かなり単純化して説明していますが、実際に行われている処理の流れは、おおよそ上記の通りです。
「今日はとても」→「今日はとても暑い」の流れ
下図は「今日はとても」を入力して「今日はとても暑い」が出力される例です。
下記の例は、あくまでサンプルで実際のトークンの分割やトークンの番号は下記とは異なります。
「今日はとても」は、「今日」「は」「とても」に分割され、例えば、7031, 1314, 2725というトークン(番号)に変換されます。これをLLMに入力すると予測が行われ、7031, 1314, 2725, 640といった出力が得られます。これを文字列に変換すると「今日はとても暑い」になります。

ちなみに、文字列をトークンに変換する処理はTokenizerで処理されます。このTokenizerについては、以下の記事で解説していますので興味があれば参考にしてください。
あわせて読みたい

Hugging FaceのTokenizerを理解する|動作まとめ
まとめ
以上、LLMの動きについて簡単に説明しました。基本的に、「与えられた入力文章に対して、尤もらしい次の単語を予測」を繰り返して文章を生成するのがLLMの基本動作になります。
「次の単語を予測する」という単純なものですが、大量のデータを学習させることで自然な文章を生成することが可能になっています。実際にChatGPTなどを使ってみても驚くほど自然な回答が出力されます。



ディープラーニングに関する記事一覧はこちら

ディープラーニング関連の記事一覧
ABOUT ME

専門分野は並列処理・画像処理・機械学習・ディープラーニング。プログラミング言語はC, C++, Go, Pythonを中心として色々利用。現在は、Kaggle, 競プロなどをしながら悠々自適に活動中
保有資格:CFP, マンション管理士、管理業務主任、宅建士など


