

大規模言語モデル(LLM)パラメータ「temperature, top_k, top_p」について【初級 深層学習講座】
データ拡張(Data Augmentation)とは?手法と実装例【初級 深層学習講座】

Aru
この記事では、データ拡張(Data Augmentation)とはどのような処理なのか、その有効性や具体的な手法について、PyTorchのサンプルコードを使いながら解説します。データ拡張を利用することで、モデルの精度向上や汎化性能の向上が期待できます。本記事では、初心者の方でも理解しやすいように、データ拡張技術のわかりやすく解説しました。
Contents
データ拡張(Data Augmentation)とは
データ拡張とは
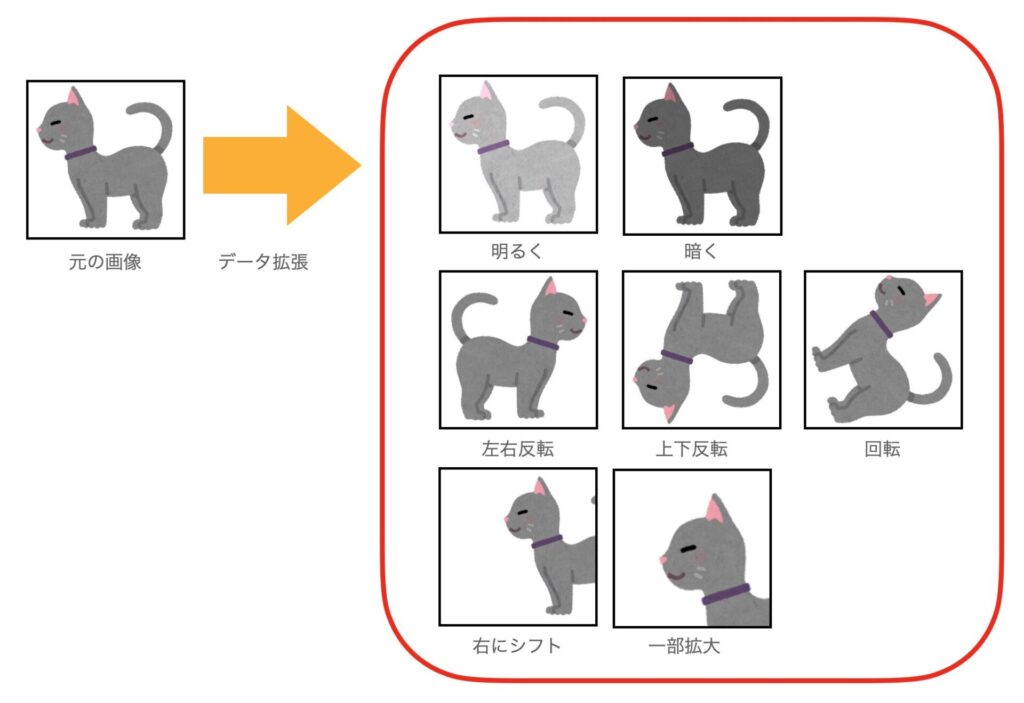
データ拡張(Data Augmentation)は、機械学習やディープラーニングにおいて、元のデータセットを変換することで新しいデータを生成する手法です。例えば、画像の反転などがこれにあたります。
データ拡張することで、データセットの多様性を増やすことができ、モデルの汎化性能を向上させることができます。
データ拡張の主な利点(メリット)は以下の通りです
- 過学習の軽減
モデルが訓練データに過度に適合してしまう過学習を防ぎます。データ拡張により、入力されるデータに変化が加えられるため、汎化性能を向上させます - データの不足への対処
実際のデータセットが限られている場合、データ拡張によって訓練データの量を増やすことができます - ロバスト性の向上
データ拡張で元データを変換することで、ノイズや変換に対してロバストな学習を行うことが可能となります。これにより、モデルが実環境で適切に機能する可能性が高まります。
データ拡張は、画像処理、自然言語処理、音声処理など、さまざまな機械学習タスクで広く使用されています。
PyTorchでのデータ拡張の実装方法
PyTorchでは、自作のデータセット内でデータ拡張を行う場合、torchvision.transformsモジュールやalbumentationを利用することが一般的です(詳細は下記のリンク参照)。このモジュールは画像データに対する様々な変換処理を提供しており、これらの変換を組み合わせてデータ拡張を実現します。
あわせて読みたい

検出枠に対応!torchvisionのデータ拡張(v2)の使い方を解説
あわせて読みたい

Albumentations:物体検出(枠)にも対応したデータ拡張ライブラリを解説
データ拡張のステップ
上記のライブラリを使ったデータ拡張の基本的な流れは以下のようになります。
- 変換の定義
transforms.Compose関数を使用して、適用したい変換処理のリストを定義します。このリスト内では、画像のランダムに回転(transforms.RandomRotation)、ランダムな水平反転(transforms.RandomHorizontalFlip)、リサイズ(transforms.Resize)、テンソルに変換(transforms.ToTensor)など、さまざまな変換を組み合わせることが可能です - データセットクラスのカスタマイズ
PyTorchでカスタムデータセットを作成する際には、torch.utils.data.Datasetを継承したクラスを定義します。このクラス内の__getitem__メソッドでは、データの読み込み、前処理、変換処理を行います。データ拡張はこの__getitem__メソッド内でtransformsによって定義された変換を適用することで実現されます
データ拡張を行うデータセットの実装例
以下は、PyTorchでカスタムデータセットにデータ拡張を適用する簡単な例です
下記の例では、データ拡張としてランダムな水平フリップと、ランダムな回転を行っています。また、最後にtorch.tensorへの変換を行っています。
from torch.utils.data import Dataset
from torchvision import transforms
from PIL import Image
class CustomDataset(Dataset):
def __init__(self, image_paths, transform=None):
self.image_paths = image_paths
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image_path = self.image_paths[idx]
image = Image.open(image_path)
if self.transform:
image = self.transform(image)
return image
# データ拡張の定義
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor()
])
# カスタムデータセットのインスタンス化
train_dataset = CustomDataset(image_paths=["path/to/image1.jpg", "path/to/image2.jpg"], transform=transform)
transformでは、ToTensor()でテンソルへの変換を行なっているため、出力される画像もテンソル型になります。
なお、上記の実装では、データを読み込むたびにデータ拡張がランダムに行われます。つまり、エポック毎に、データセット中の各画像に対するデータ拡張が変化することになります。これにより、モデルが訓練データに過度に適合してしまう過学習を抑制することができます。
test, validデータセットの場合は、一般的にデータ拡張は行いません。
しかしながら、上記のコードを使ってtest, valid用のデータセットを作成する場合、データのフォーマットをテンソルに変換する処理だけは行う必要があります(変換しないと、trainとtest,validでデータセットの出力フォーマットが異なることになる)。
以下は、validデータセットを定義する例です。以下の例のように、transformで、ToTensor()だけ呼び出すようにします。
transform = transforms.Compose([
transforms.ToTensor()
])
valid_dataset = CustomDataset(image_paths=["path/to/image1.jpg", "path/to/image2.jpg"], transform=transform)データ拡張の種類(画像・自然言語・音声)
データ拡張には、さまざまな種類があります。以下に一般的なデータ拡張の種類を挙げます。
以下は、一般的なデータ拡張の手法です。ここに説明した以外にも、いろいろなデータ拡張の手法が存在しています。
画像のデータ拡張
以下、画像のデータ拡張の種類について解説します。
画像のデータ拡張では、明るさや色調といったものを変換するものや、回転や反転、クロップといったものに分けることができます。
なお、物体検出(Object Detection)、セグメンテーション(Semantic Segmentation)の場合は、枠(Bounding Box)や、セグメンテーションマスクに対する処理も同時に行う必要があります。例えば、画像を反転させた場合は、枠の位置もずれるので反転に合わせて場所を補正する必要があります。
画像に関するデータ拡張は多数発表されていますが、以下は画像のデータ拡張の例です。
- 回転: 画像をある程度の角度で回転させる
- 反転: 画像を水平方向または垂直方向に反転させる
- クロップ: 画像からランダムな領域をクロップする
- ズーム: 画像内のオブジェクトをランダムに拡大または縮小する
- オフセット: 物体の位置をランダムにずらす
- 明るさ変換: 画像の明るさをランダムに変化させる
- 色調変換: 画像の色相、彩度、明度を変更する
- オフセット: 物体の位置をランダムにずらす
- アスペクト比変更: 画像内の物体のアスペクト比を変更する
- dropout/cutout: 画像内の一部領域をモザイク処理して物体の一部を隠す
- エラスティック変換: 画像をランダムに歪ませる
また、mix-upと呼ばれる手法もあります。これは、2つの画像をランダムに選択し、それらの画像と対応するラベルの重み付き平均を取ることで新しい画像を生成します。この手法はデータ拡張として使われるだけでなく、モデルの正則化にも役立ちます。
あわせて読みたい

データ拡張(data augmentation)手法のmixupを解説|Pytorchでの実装方法【初級 深層学習講座】
自然言語処理(NLP)のデータ拡張
自然言語処理のデータ拡張では、テキストデータに対して変換や操作を行います。自然言語の場合、単語が変わっただけでも文章の意味が大きく変わることがあるため、画像と比較してデータ拡張は慎重に行わなければなりません。
以下は主なデータ拡張です。
- 類義語に置換:文章中の単語をランダムに選択した類義語に置換する
- ランダムな置換: 文章中の単語や文字をランダムに置換する
- ランダムな挿入: 文章中にランダムな単語やフレーズを挿入する
- ランダムな削除: 文章中の単語や文字をランダムに削除する
- ランダムな入れ替え: 文章内の単語の順序をランダムに入れ替える
- Back-Translation: テキストを外国語に翻訳し、再度元の言語に戻す。翻訳モデルを利用してデータを増やすことができる
最近では、Chat-GPTなどのLLMを利用して、文章を言い換えたりする手法もあります。他の言語モデルを利用してデータ拡張をする場合、処理時間に注意する必要があります。
音声のデータ拡張
音声のデータ拡張は、1次元の音声信号に対して行う手法と、スペクトログラム(画像)に変換したあとに行う手法があります
- 音声データに対する処理
- 音程変換: 音声の音程を変更する
- 音量変更:音量を変更する
- ノイズ追加: ホワイトノイズやピンクノイズなどのノイズを音声に追加する
- 時間的な歪み: 音声の速度を変更することによる時間的な歪みを加える
- スペクトログラムに対する処理
- 周波数マスキング:一部の周波数をマスクする
- dropout/cutout: 一部領域を矩形で隠す

オーディオデータのデータ拡張ライブラリとして、Audiomentationsがあります
推論時のデータ拡張(特殊なデータ拡張)
TTA(Test Time Augumentation)
学習時だけでなく、推論時にデータ拡張することも可能です。
TTA(Test Time Augmentation)は、モデルの推論時にデータ拡張を適用して、複数の変換済み画像に対して推論を行い、最終的な予測を複数の予測の平均などで統合する手法です。
通常は、推論時にはデータ拡張を適用せずに単一の入力画像に対して推論を行います。
しかし、TTAでは、推論時にも複数のデータ拡張を適用した画像に対して推論を行い、それらの結果を統合することで、よりロバストな予測を行うことが可能です。
具体的な手順は以下の通りです:
- テスト画像に対して複数のデータ拡張を適用する。
- 各拡張済み画像に対して、モデルを使用して推論を行う。
- すべての拡張済み画像の予測を統合する。一般的な方法には、予測の平均を取る、または投票を行うなどがあります。
TTAの利点は、単一の推論結果に比べて、より安定した予測を得ることができることです。特に、データ拡張によって生じるクラスの位置やスケールの不確実性を軽減することができます。
一方で、計算コストが増加する可能性があるため、リアルタイム性が求められる場合には注意が必要です。
あわせて読みたい

TTA(Test Time Augmentation)とは?PyTorchでの実装方法
まとめ
以上、データ拡張について解説しました。
ディープラーニングでは、データ拡張は精度向上のための重要なテクニックの1つとなります。うまく利用して精度アップをめざしましょう。



ディープラーニングに関する記事一覧はこちら

ディープラーニング関連の記事一覧
ABOUT ME

専門分野は並列処理・画像処理・機械学習・ディープラーニング。プログラミング言語はC, C++, Go, Pythonを中心として色々利用。現在は、Kaggle, 競プロなどをしながら悠々自適に活動中
保有資格:CFP, マンション管理士、管理業務主任、宅建士など



