

Pandasのlocとilocの違いと使い分けを詳しく解説|Python
Aru
Aru's テクログ(Aruaru0)

YOLO-NASはYOLOv8の公開から5ヶ月後に公開された物体検出のモデルです。本記事では、YOLO-NASを用いたカスタムデータ(自作データ、オリジナルデータ)の学習と推論の方法について解説します。公式サンプルでの動作で苦労しましたが、カスタムデータでも学習・推論させることがなんとかできましたので、その手順を共有します。
YOLO-NASは2023年5月に登場した物体検出モデルです。
公式の発表では、YOLOv5、YOLOv6、YOLOv7、YOLOv8 などの他のモデルを上回る性能を実現しているそうです。また、姿勢推定用のYOLO-NAS-POSEも用意されています。
性能は以下のようになります。
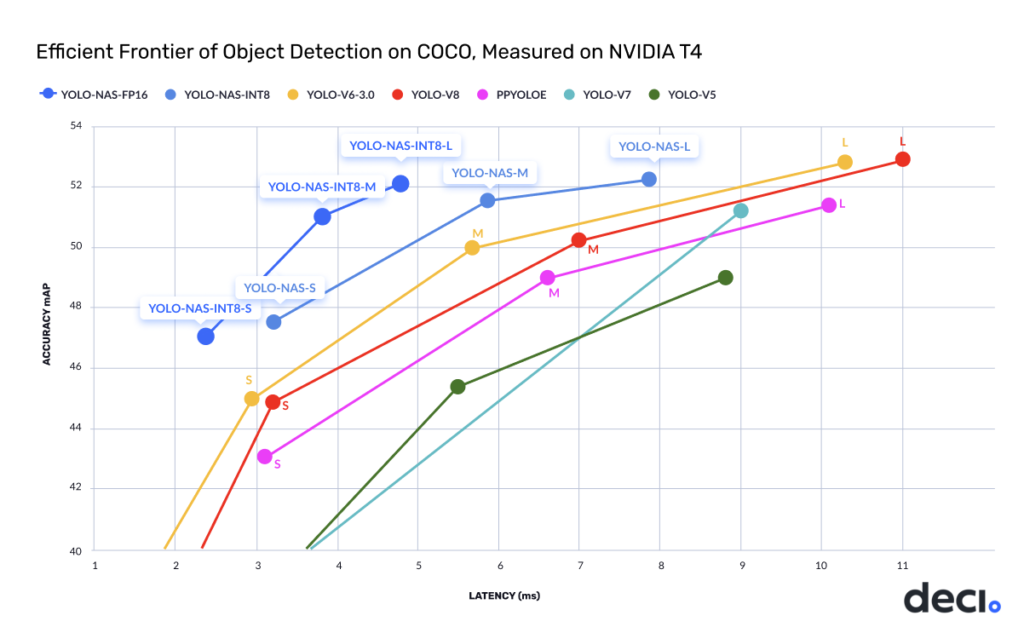
グラフを見る限り、高速(低レイテンシ)で高性能になっているように見えます(同じ性能ならYOLO-NASの方が高速)。
公式Github : https://github.com/Deci-AI/super-gradients
ここでは、YOLO-NASを使って物体検出の学習と推論を行わせてみます。
利用するデータセットは、YOLOv8の物体検知の学習と推論のテストを行った時と同じ、Car Object Detectionデータセットです。
以下、YOLO-NASでカスタムデータを学習させ、推論させる処理をPythonコードで行ってみます。
今回も、kaggle Notebookでコードを用意しています。
コードのリンクはこちらです

kaggleのアカウントがあれば、kaggle上でノートブックをコピーして実行できます。ぜひ、自分で動かしてみてください。
YOLO-NASのインストールは、以下のpipコマンドを実行するだけです。
!pip install super_gradientsまず、使いそうなライブラリを一通りインポートしています(使っていないものも含まれています)
import os
import random
import shutil
import numpy as np
import pandas as pd
import cv2
import yaml
import matplotlib.pyplot as plt
import glob
from sklearn.model_selection import train_test_split
from tqdm.notebook import tqdm次に、PyTorchと、YOLO-NAS関連のライブラリをインポートします
import torch
from super_gradients.training import dataloaders
from super_gradients.training.dataloaders.dataloaders import coco_detection_yolo_format_train, coco_detection_yolo_format_val
from super_gradients.training import models
from super_gradients.training.losses import PPYoloELoss
from super_gradients.training.metrics import DetectionMetrics_050
from super_gradients.training.models.detection_models.pp_yolo_e import PPYoloEPostPredictionCallback今回の学習では、データはkaggleのCar Object Detectionデータセットを利用しました。
このデータセットには、テスト用の画像フォルダと、トレーニング用の画像フォルダ、トレーニング画像のアノテーションデータがcsvファイル形式で格納されています。
YOLOv8の時と同様に、フォーマットの変換を行います。ちなみに、YOLO-NASのデータセットの格納フォーマットは、YOLOv8と同じで良いので、この手順はYOLOv8と同じになります。
まず、各種ディレクトリの設定を行います。TRAINは訓練用の画像データ、TESTは評価用の画像データの位置です。
DIR = "/kaggle/working/datasets/cars/"
IMAGES = DIR +"images/"
LABELS = DIR +"labels/"
TRAIN = "/kaggle/input/car-object-detection/data/training_images"
TEST = "/kaggle/input/car-object-detection/data/testing_images"まず、CSVファイルを読み込みます。
df = pd.read_csv("/kaggle/input/car-object-detection/data/train_solution_bounding_boxes (1).csv")
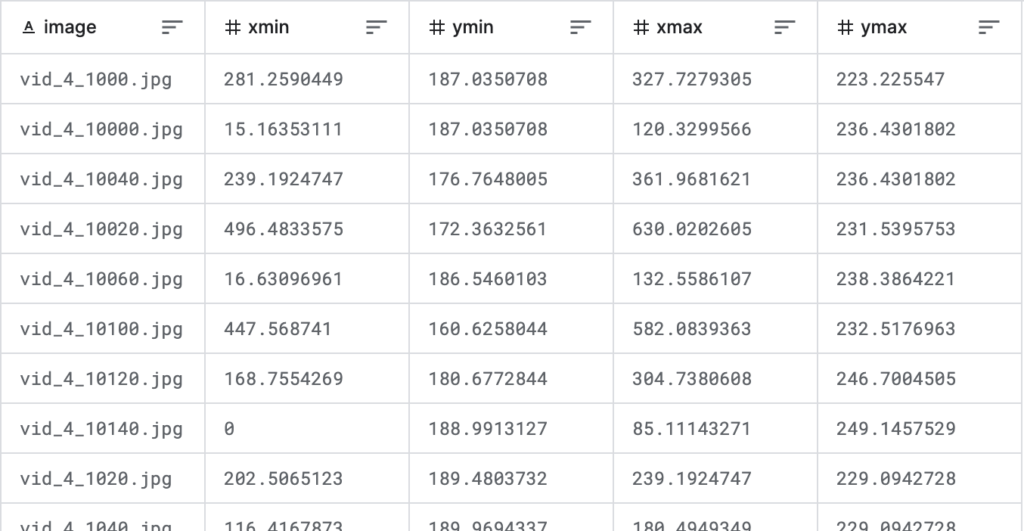
dfこのファイルは、各行はファイル名+枠情報になっていて、1ファイルに複数枠ある場合は、同じファイル名が複数行続く構成になっています(下図)。
訓練と評価用にファイル分割するためにunique()で一意なファイル名を取り出し、train_test_split関数を使って2つに分離しました。
比率は訓練:評価=8:2の割合です。
files = list(df.image.unique())
files_train, files_valid = train_test_split(files, test_size = 0.2)訓練と評価データを決めたので、次は、データセットフォルダを作成し、そこにファイルを配置していきます。
まず、YOLOv8形式で、ファイルを置くためのフォルダを作成します。
# make directories
os.makedirs(IMAGES+"train", exist_ok=True)
os.makedirs(LABELS+"train", exist_ok=True)
os.makedirs(IMAGES+"valid", exist_ok=True)
os.makedirs(LABELS+"valid", exist_ok=True)各画像ファイルを訓練、評価のフォルダに分けてコピーします。どちらに、割り振られるかは、if文で判定しています。
train_filename = set(files_train)
valid_filename = set(files_valid)
for file in glob.glob(TRAIN+"/*"):
fname =os.path.basename(file)
if fname in train_filename:
shutil.copy(file, IMAGES+"train")
elif fname in valid_filename:
shutil.copy(file, IMAGES+"valid")CSVデータの情報を、YOLOv8の情報(クラスID, X中心、Y中心、W、H)のフォーマットに変換し、画像ファイルと同名のテキストファイルに格納します。
元のデータが676×380のサイズでの(xmin, ymin)-(xmax, ymax)のデータなので、これを(クラスID, X中心、Y中心、W、H)に変換すると同時に、スケールも0.0〜1.0に変換しています。
YOLOのフォーマットでは、アノテーションデータは以下のフォーマットになります(xy座標と幅は、画像の幅、高さを1とした値(0~1)になります)
クラスID X中心 Y中心 W H
クラスID X中心 Y中心 W H
クラスID X中心 Y中心 W H
: (オブジェクトの数だけ繰り返し)for _, row in df.iterrows():
image_file = row['image']
class_id = "0"
x = row['xmin']
y = row['ymin']
width = row['xmax'] - row['xmin']
height = row['ymax'] - row['ymin']
x_center = x + (width / 2)
y_center = y + (height / 2)
x_center /= 676
y_center /= 380
width /= 676
height /= 380
if image_file in train_filename:
annotation_file = os.path.join(LABELS) + "train/" + image_file.replace('.jpg', '.txt')
else:
annotation_file = os.path.join(LABELS) + "valid/" + image_file.replace('.jpg', '.txt')
with open(annotation_file, 'a') as ann_file:
ann_file.write(f"{class_id} {x_center} {y_center} {width} {height}\n")変換後のフォルダ構成は、以下のようになります
datasets
└── cars
├── images
│ ├── train
│ │ ├── xxxx.jpg
│ │ └── xxxx.jpg
│ └── val
│ ├── xxxx.jpg
│ └── xxxx.jpg
└── labels
├── train
│ ├── xxxx.txt
│ └── xxxx.txt
└── val
├── xxxx.txt
└── xxxx.txt以上で、データセットの準備は完了です。
独自のデータにラベルをつけて学習させたい方は、アノテーションを行う必要があります。アノテーションの方法については以下の記事を参考にしてください。labelimgとLabelStudioの2つを紹介しています。


YOLO-NASのデータセットとデータローダーを定義します。
まずは、データセット関連の情報を定義しておきます。
dataset_params = {
'data_dir':'/kaggle/working/datasets/cars',
'train_images_dir':'images/train',
'train_labels_dir':'labels/train',
'val_images_dir':'images/valid',
'val_labels_dir':'labels/valid',
'test_images_dir':'images/valid',
'test_labels_dir':'labels/valid',
'classes': ['car']
}次に、YOLO-NASのパラメータを設定します。こちらは、利用するモデル、CPUとGPUのデバイス設定、バッチサイズ、最大エポック数、結果の格納フォルダなどの情報になります。
MODEL_ARCH = 'yolo_nas_l'
DEVICE = 'cuda' if torch.cuda.is_available() else "cpu"
BATCH_SIZE = 8
MAX_EPOCHS = 10
CHECKPOINT_DIR = f'/kaggle/working'
EXPERIMENT_NAME = f'yolo_nas_car'データセットのフォルダ情報に基づいて、訓練データ、検証データ、テストデータの3つのデータローダを生成します。
訓練データはcoco_detection_yolo_format_train関数を、その他の2つはcoco_detection_yolo_format_val関数を使ってデータローダーを生成している点に注意してください。
訓練データと、検証・テストデータでは、生成時の関数が異なります
train_data = coco_detection_yolo_format_train(
dataset_params={
'data_dir': dataset_params['data_dir'],
'images_dir': dataset_params['train_images_dir'],
'labels_dir': dataset_params['train_labels_dir'],
'classes': dataset_params['classes']
},
dataloader_params={
'batch_size': BATCH_SIZE,
'num_workers': 1
}
)
val_data = coco_detection_yolo_format_val(
dataset_params={
'data_dir': dataset_params['data_dir'],
'images_dir': dataset_params['val_images_dir'],
'labels_dir': dataset_params['val_labels_dir'],
'classes': dataset_params['classes']
},
dataloader_params={
'batch_size': BATCH_SIZE,
'num_workers': 1
}
)
test_data = coco_detection_yolo_format_val(
dataset_params={
'data_dir': dataset_params['data_dir'],
'images_dir': dataset_params['test_images_dir'],
'labels_dir': dataset_params['test_labels_dir'],
'classes': dataset_params['classes']
},
dataloader_params={
'batch_size': BATCH_SIZE,
'num_workers': 1
}
)これで、データの準備が完了しました。
ここで、訓練データのデータ拡張を確認してみます。
train_data.dataset.transforms[DetectionMosaic('additional_samples_count': 3, 'non_empty_targets': False, 'prob': 1.0, 'input_dim': (640, 640), 'enable_mosaic': True, 'border_value': 114),
DetectionRandomAffine('additional_samples_count': 0, 'non_empty_targets': False, 'degrees': 10.0, 'translate': 0.1, 'scale': [0.1, 2], 'shear': 2.0, 'target_size': (640, 640), 'enable': True, 'filter_box_candidates': True, 'wh_thr': 2, 'ar_thr': 20, 'area_thr': 0.1, 'border_value': 114),
DetectionMixup('additional_samples_count': 1, 'non_empty_targets': True, 'input_dim': (640, 640), 'mixup_scale': [0.5, 1.5], 'prob': 1.0, 'enable_mixup': True, 'flip_prob': 0.5, 'border_value': 114),
DetectionHSV('additional_samples_count': 0, 'non_empty_targets': False, 'prob': 1.0, 'hgain': 5, 'sgain': 30, 'vgain': 30, 'bgr_channels': (0, 1, 2), '_additional_channels_warned': False),
DetectionHorizontalFlip('additional_samples_count': 0, 'non_empty_targets': False, 'prob': 0.5),
DetectionPaddedRescale('additional_samples_count': 0, 'non_empty_targets': False, 'swap': (2, 0, 1), 'input_dim': (640, 640), 'pad_value': 114),
DetectionTargetsFormatTransform('additional_samples_count': 0, 'non_empty_targets': False, 'input_format': OrderedDict([('bboxes', name=bboxes length=4 format=<super_gradients.training.datasets.data_formats.bbox_formats.xyxy.XYXYCoordinateFormat object at 0x7d042d709780>), ('labels', name=labels length=1)]), 'output_format': OrderedDict([('labels', name=labels length=1), ('bboxes', name=bboxes length=4 format=<super_gradients.training.datasets.data_formats.bbox_formats.cxcywh.CXCYWHCoordinateFormat object at 0x7d042d70a980>)]), 'min_bbox_edge_size': 1, 'input_dim': (640, 640), 'targets_format_converter': <super_gradients.training.datasets.data_formats.format_converter.ConcatenatedTensorFormatConverter object at 0x7d042c36ba90>)]赤文字にした部分のように、いくつかのデータ拡張がデフォルトで設定されていることがわかります。
実際に訓練データを出力してみます。
train_data.dataset.plot()以下のように、Mixupなどのデータ拡張が行われていることが確認できます。

簡単に確認できる関数があらかじめ用意されているのはいいかも
モデルを読み込みます。num_classesにクラス数を、事前学習の重みをcocoに設定しています。今回は、車だけなのでクラス数は1です。
model = models.get(
MODEL_ARCH,
num_classes=len(dataset_params['classes']),
pretrained_weights="coco"
)トレーニングパラメータの設定です。
細かなパラメータの説明を見つけられなかったので、説明は省きますが、ディープラーニングに取り組んでいる方は、パラメータ名でおおよその意味は理解できるかと思います。
YOLOv8と比較するとYOLO-NASはドキュメントがあまり準備されていない気がします。使いながらいろいろ試行錯誤する必要がありそうです。
train_params = {
'silent_mode': False,
"average_best_models":True,
"warmup_mode": "linear_epoch_step",
"warmup_initial_lr": 1e-6,
"lr_warmup_epochs": 3,
"initial_lr": 5e-4,
"lr_mode": "cosine",
"cosine_final_lr_ratio": 0.1,
"optimizer": "Adam",
"optimizer_params": {"weight_decay": 0.0001},
"zero_weight_decay_on_bias_and_bn": True,
"ema": True,
"ema_params": {"decay": 0.9, "decay_type": "threshold"},
"max_epochs": MAX_EPOCHS,
"mixed_precision": True,
"loss": PPYoloELoss(
use_static_assigner=False,
num_classes=len(dataset_params['classes']),
reg_max=16
),
"valid_metrics_list": [
DetectionMetrics_050(
score_thres=0.1,
top_k_predictions=300,
num_cls=len(dataset_params['classes']),
normalize_targets=True,
post_prediction_callback=PPYoloEPostPredictionCallback(
score_threshold=0.01,
nms_top_k=1000,
max_predictions=300,
nms_threshold=0.7
)
)
],
"metric_to_watch": 'mAP@0.50'
}次に、訓練用のオブジェクトを生成します。
from super_gradients.training import Trainer
trainer = Trainer(experiment_name=EXPERIMENT_NAME, ckpt_root_dir=CHECKPOINT_DIR)準備が整ったので、学習を行います。学習はtrainを呼び出すだけです。
trainer.train(model=model,
training_params=train_params,
train_loader=train_data,
valid_loader=val_data)学習のログは以下のような感じで出力されます。YOLOv8に比べると情報は見やすいですが、1Epoch分の情報が少し多いかなといった印象です。
:
(略)
:
===========================================================
Train epoch 9: 100%|██████████| 35/35 [00:24<00:00, 1.44it/s, PPYoloELoss/loss=1.48, PPYoloELoss/loss_cls=0.644, PPYoloELoss/loss_dfl=0.413, PPYoloELoss/loss_iou=0.419, gpu_mem=7.1]
Validating epoch 9: 100%|██████████| 9/9 [00:02<00:00, 4.13it/s]
===========================================================
SUMMARY OF EPOCH 9
├── Train
│ ├── Ppyoloeloss/loss_cls = 0.6437
│ │ ├── Epoch N-1 = 0.6577 (↘ -0.014)
│ │ └── Best until now = 0.6577 (↘ -0.014)
│ ├── Ppyoloeloss/loss_iou = 0.4194
│ │ ├── Epoch N-1 = 0.4303 (↘ -0.0108)
│ │ └── Best until now = 0.4303 (↘ -0.0108)
│ ├── Ppyoloeloss/loss_dfl = 0.4129
│ │ ├── Epoch N-1 = 0.42 (↘ -0.0071)
│ │ └── Best until now = 0.42 (↘ -0.0071)
│ └── Ppyoloeloss/loss = 1.476
│ ├── Epoch N-1 = 1.5079 (↘ -0.0319)
│ └── Best until now = 1.5079 (↘ -0.0319)
└── Validation
├── Ppyoloeloss/loss_cls = 0.6207
│ ├── Epoch N-1 = 0.642 (↘ -0.0213)
│ └── Best until now = 0.6276 (↘ -0.0069)
├── Ppyoloeloss/loss_iou = 0.4049
│ ├── Epoch N-1 = 0.4101 (↘ -0.0052)
│ └── Best until now = 0.4092 (↘ -0.0044)
├── Ppyoloeloss/loss_dfl = 0.4069
│ ├── Epoch N-1 = 0.4172 (↘ -0.0104)
│ └── Best until now = 0.4152 (↘ -0.0083)
├── Ppyoloeloss/loss = 1.4324
│ ├── Epoch N-1 = 1.4693 (↘ -0.0369)
│ └── Best until now = 1.462 (↘ -0.0296)
├── Precision@0.50 = 0.2323
│ ├── Epoch N-1 = 0.1419 (↗ 0.0903)
│ └── Best until now = 0.2022 (↗ 0.03)
├── Recall@0.50 = 1.0
│ ├── Epoch N-1 = 1.0 (= 0.0)
│ └── Best until now = 1.0 (= 0.0)
├── Map@0.50 = 0.9887
│ ├── Epoch N-1 = 0.9928 (↘ -0.004)
│ └── Best until now = 0.996 (↘ -0.0072)
└── F1@0.50 = 0.377
├── Epoch N-1 = 0.2486 (↗ 0.1284)
└── Best until now = 0.3364 (↗ 0.0405)
===========================================================
[2023-11-28 04:54:10] INFO - sg_trainer.py - RUNNING ADDITIONAL TEST ON THE AVERAGED MODEL...
Validating epoch 10: 100%|██████████| 9/9 [00:02<00:00, 4.05it/s]学習した結果は{CHECKPOINT_DIR}/{EXPERIMENT_NAME}フォルダの下に実験番号(?)のフォルダができてそこに格納されます。
average_model.pth、ckpt_best.pth、ckpt_latest.pthの3つのモデルが作成されますが、ここでは、average_model.pthを読み込んでいます。
average_model.pthの説明を見つけられませんでしたが、公式のサンプルもこれを読み込んでいるのでこちらを使いました。
ckpt_best.pthを使っても良いと思います。
フォルダ名が自動で生成されているので、globを使って検索しています。
file = glob.glob(f"{CHECKPOINT_DIR}/{EXPERIMENT_NAME}/*/average_model.pth")
file学習したパラメータをモデルに読み込みます。
best_model = models.get(
MODEL_ARCH,
num_classes=len(dataset_params['classes']),
checkpoint_path=file[0]
).to(DEVICE)最後にテストデータの何枚かに対して、推論を行います。
# display result
files = glob.glob(f"{dataset_params['data_dir']}/{dataset_params['test_images_dir']}/*")
for i in range(0, 30, 3):
print(files[i])
img = files[i]
best_model.predict(img).show()下の画像は結果のうち、数枚を抜き出したものです。結果を見ると、車をうまく検出できていそうです(ただ、二枚目の映像は、左端には2台の車が重なってそうですが1台しか検出できていません)。


YOLOv8の後に発表されたYOLO-NASで学習と推論を行ってみました。正直なところ、YOLOv8より性能が優れているかどうかわかりません。
性能以外の面、例えばドキュメントの充実度などを比較すると、YOLOv8の方がいいかなと言う印象です。実際、YOLOv8はアップデートが頻繁に行われていますし、メインで使うならYOLOv8かなと思います。



