
期待値を計算する動的計画法(AtCoder ABC402E 問題)を解く
Aru
Aru's テクログ(Aruaru0)

機械学習、データ分析の前処理として、データをスケーリングすることがあります。標準化などは、よく使われるスケーリングで、元のデータの平均$\mu$と偏差$\sigma$を使って$z = (x-\mu)/\sigma$という計算を行うものです。
ただ、スケーリングは、scikit-learn(sklearn)で提供されていますのでそちらを使った方が楽。ここではsklearnを使ったスケーリングのコード例をいくつか紹介。

前処理に関しては以下の記事も参考にしてください

自分がよく使うのは、主に以下の3つ。
| MinMaxScaler | 所定の範囲(0〜1など)に収まるようにMin/Maxでスケーリング |
| StandardScaler | 標準化 |
| RobustScaler | 外れ値に強いスケーリング |
どれも同じように使うことができるので、データに応じて使い分けします。
標準化については、次の記事もあわせて参照してください。

必要なライブラリを読み込みます
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
import numpy as np
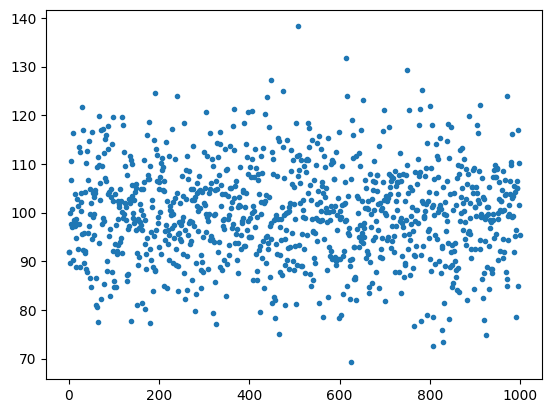
import matplotlib.pyplot as plt仮データを作成します。今回はnumpyでN(100,10)の分布で作成しています。
x = np.random.normal(100, 10, 1000).reshape(-1, 1)
plt.plot(x, '.')
plt.show()
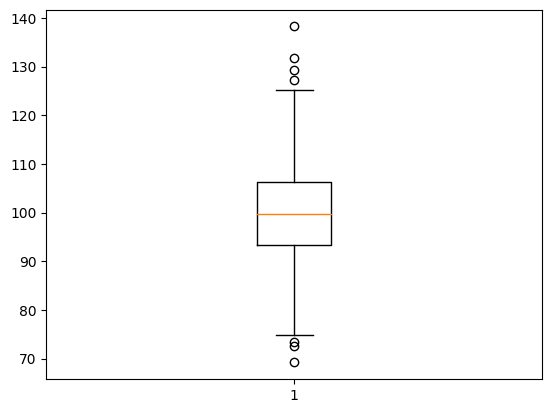
plt.boxplot(x)データの分布はこんな感じ。いかにも正規分布らしい分布です。
それぞれの手法で変換してみます。書き方はほとんど一緒なので一気に紹介。
#MinMax Scaler
scaler = MinMaxScaler()
y = scaler.fit_transform(x)
plt.plot(y, '.')
plt.show()
# Standard Scaler
scaler = StandardScaler()
y = scaler.fit_transform(x)
plt.plot(y, '.')
plt.show()
# RobustScaler
scaler = RobustScaler()
y = scaler.fit_transform(x)
plt.plot(y, '.')フィッテイングと変換の両方を同時に行う場合は、fit_transformを、フィッティングだけ行いたい場合にはfitを、変換だけ行いたい場合はtransformをそれぞれ用います。私がよく行う使い方は、トレーニングデータに対してfit_transformを実行し、テストデータも同じように変換したい場合はtransformだけを使用する方法です。
変換結果が以下になります。
| MinMaxScaler | 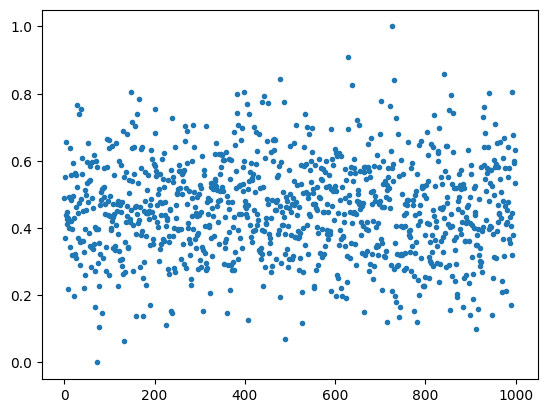 |
| StandardScaler | |
| RobustScaler | |
スケーリング結果を見ると、どれも似たように見えるかもしれませんが、y軸の範囲に注目してください。それぞれ、スケーリングが異なることがわかるかと思います。
RobustScalerの効果がわかりにくいので、元データに少しノイズ(外れ値を追加したデータを作成して同様に変換を行ってみました。元のデータは以下のような感じです。
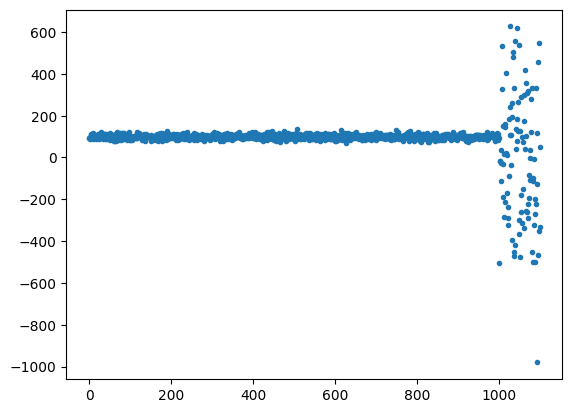
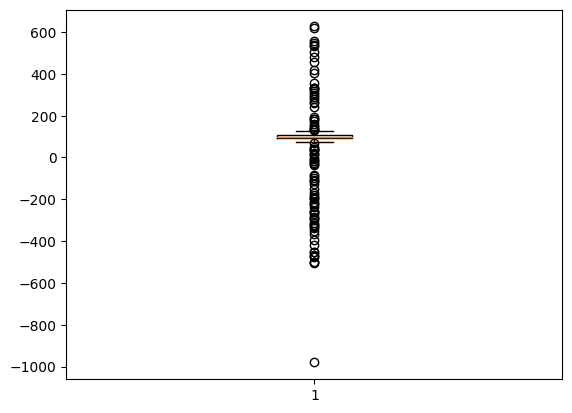
これをスケーリングすると、以下のようになります。y軸を見ると、MinMaxScalerは外れ値を含めて0〜1の範囲にスケーリングされるため、0.7付近に正常値が全て集められていることがわかります。一方、StandardScalerは外れ値のせいで正常値の範囲がずいぶん小さくなってしまっていることがわかります。これらと比べると、RobustScalerは全体の範囲が-80〜40と広く取られ、正常値の範囲もそれに伴ってある程度確保されていることがわかります。大きな外れ値が存在する入力データなどでは、RobustScalerを用いると良さそうです。
| MinMaxScaler | 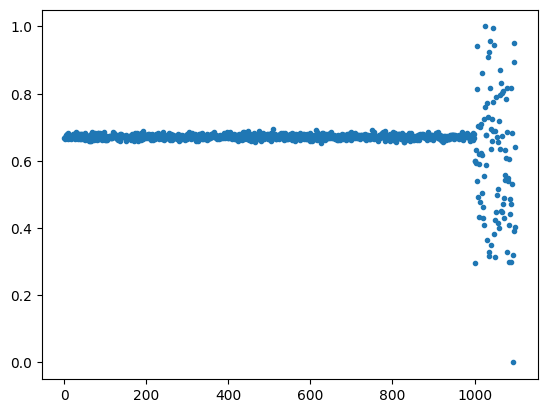 |
| StandardScaler | 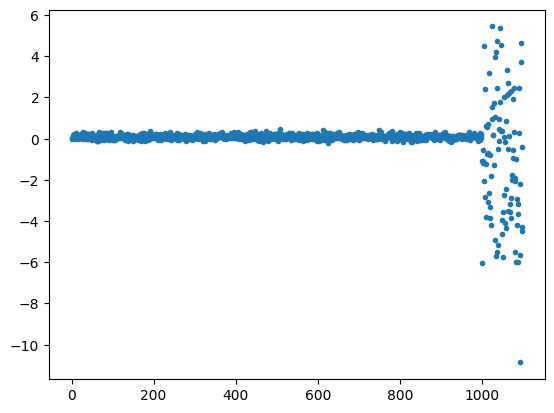 |
| RobustScaler | 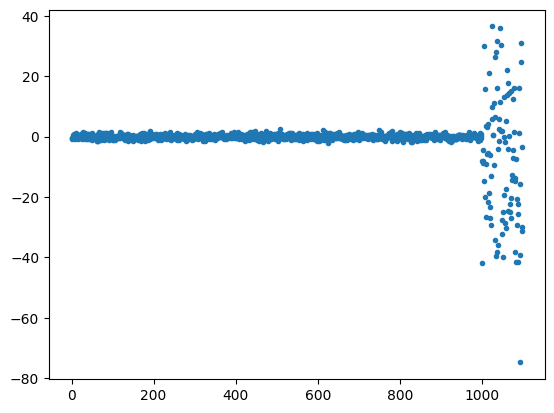 |
また、これらの関数の入力はpandasのデータフレームでも良いです。データフレームの場合、以下のように書けば列をまとめてスケーリングすることができます(例では、sel_colsにスケーリングしたい列名の一覧が入っている前提です)。
scaler = RobustScaler().set_output(transform="pandas")
df[sel_cols] = scaler.fit_transform(df[sel_cols])

