Pythonでカラーノイズ(ピンクノイズ、ホワイトノイズ)を生成する|サウンドデータ
Aru
Aru's テクログ(Aruaru0)

データセット内にノイズラベルがあると、機械学習のモデルの性能に悪影響を与えることがあります。この記事ではCleanlabという強力なライブラリを用いて、データセット内のノイズラベルを効率よく検出し、データセットの品質を向上させる方法について解説します。
ディープラーニングのモデルの性能を引き出すためには、学習に用いるデータセットのクオリティ(品質)も重要です。もし、正解ラベルをつけ間違ったデータなどがデータセット中に存在していると、その影響により精度が低下してしまうことがあります。
このような、ラベルの誤りや異常データを効率的に特定し、データ品質を向上させるためのツールとしてCleanlabがあります。
Cleanlabの公式サイト:https://docs.cleanlab.ai/v2.0.0/index.html
具体的には、Cleanlabはデータセット中のノイズラベルを検出するためのライブラリです。このライブラリを使えば、効率よくノイズラベルを検出することができ、データクレンジング処理を手軽に行うことができます。これにより、モデルの精度の向上させることが可能です。
Cleanlabを利用してデータクレンジングする手順は以下の通りです。
Cleanlabは、機械学習の実務においてデータ品質を維持するための強力なツールです。
ここでは、MNISTの手書き文字データを使って実際にノイズ画像の検出をやってみたいと思います。
MNISTの学習コードと手順については、他の記事で解説していますので、詳しくはそちらを参照してください。

ここでは、上記記事の手順で学習後のモデルに対してcleanlabを使ってノイズ画像の検出を試みてみます。
なお、今回の実験コードはこちらにあります(Google Colabで動作します)
cleanlabを利用するには、ライブラリのインストールが必要です。以下のコマンドを実行してcleanlabをインストールしてください。
!pip install cleanlabノイズ画像を検出するために、推論モードでモデルを実行しoutputsと正解ラベルy_gtを保存しておきます。
今回は、訓練データ(train_dataset)中のノイズデータを検索したいので、test_dataloaderが参照するデータセットにtrain_datasetを設定しています。
下記のコードを実行することで、全ての訓練画像のy_outputsに予測結果が、y_gtに正解ラベルが格納されます。

outputsにsoftmaxをかけて0~1のデータにしています。これは、cleanlabが0~1範囲の入力を期待しているためです。
test_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=False)
model.eval()
y_pred = []
y_gt = []
y_outputs = None
for batch in tqdm(test_loader):
inputs, targets = batch
with torch.no_grad() :
outputs = model(inputs.to(device))
y_gt += targets.tolist()
y_pred += outputs.argmax(axis=1).tolist()
if y_outputs is None:
y_outputs = outputs.detach().cpu().softmax(dim=1).numpy()
else:
y_outputs = np.vstack((y_outputs, outputs.detach().cpu().softmax(dim=1).numpy()))次に、cleanlabのfind_label_issues関数を実行します。
引数は、正解ラベル、予測結果、filter_by=xxxでモードです。モードはいくつかありますが、今回は「不正解のデータ(predicted_neq_given)」と、「prune_by_noise_rate」の2つのモードを利用してみました。
他にもオプションが多数あります。詳しくは公式サイトを確認してください。
import cleanlab
from cleanlab.filter import find_label_issues
# valid = find_label_issues(y_gt, y_outputs, filter_by="confident_learning")
print(f"正解と異なる推論データは{sum([1 if x != y else 0 for x, y in zip(y_gt, y_pred)])}個です")
valid = find_label_issues(y_gt, y_outputs, filter_by="predicted_neq_given")
print(f"predicted_neq_givenモードでノイズ画像を{sum(valid)}個発見しました")
valid = find_label_issues(y_gt, y_outputs, filter_by="prune_by_noise_rate")
print(f"prune_by_noise_rateモードでノイズ画像を{sum(valid)}個発見しました")実行すると、正解と推論結果が違うものが215個存在することがわかります。このように、predicted_neq_givenモードでは、正解と推論結果が異なるもの全てが検出されます。
prune_by_noise_rateでは、さらに少ない3つがノイズ画像として検出されました。
正解と異なる推論データは215個です
predicted_neq_givenモードでノイズ画像を215個発見しました
prune_by_noise_rateモードでノイズ画像を3個発見しました実際に、ノイズ画像と判定された3つの画像を表示してみます。以下は、表示させるコードです。
for idx, (gt, flg) in enumerate(zip(y_gt, valid)):
if flg == True :
img, label = train_dataset[idx]
plt.imshow(img.squeeze(), cmap="gray")
plt.title(f"gt={gt}")
plt.show()結果は以下になります。
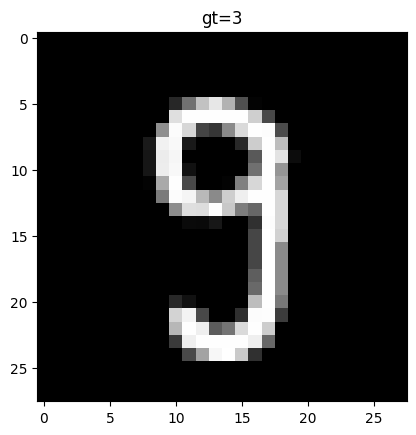
正解は3ですが、1つ目は9にしか見えないですね。
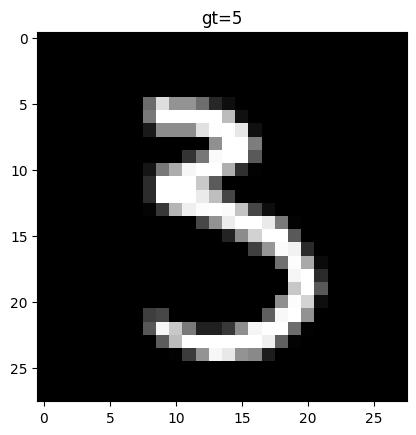
2つ目は、正解は5ですが、画像は3に見えます
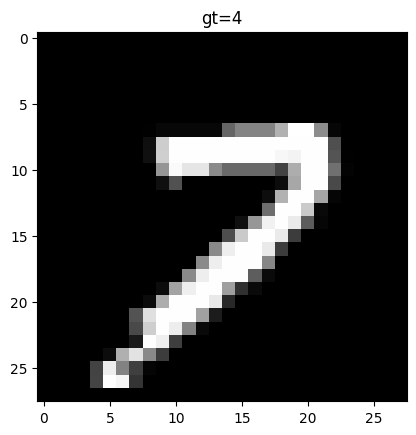
3つめは、正解は4ですが7に見えます
検出結果を確認してみると、この3つのデータは確かにノイズラベルのようです。
Cleanlabを実際に利用した学習フローでは、検出されたノイズラベルのデータを修正、または削除してクレンジングされたデータセットを作成し、それを用いて再度学習を行いますが、ここでは検出までで一旦〆たいと思います。
データセットの中からノイズデータを検出するcleanlabの使い方について解説しました。比較的手軽に利用できるので、使ってみるのも良いかもしれません。