
機械学習とデータ分析の前処理 | scikit-learnを使ったデータのスケーリング方法
Aru
Aru's テクログ(Aruaru0)

YOLOv8.2がリリースされ、新たに追加されたYOLO-Worldモデルは、ゼロショットの物体検出機能を持つことで注目を集めています。本記事では、ゼロショット物体検出能力を検証するために、YOLO-Worldを使って物体検出を行い、その実力を確認してみました。ゼロショット物体検出の実力がどの程度か興味がある方は一読ください。
Ultralytics社のYOLOモデルです。2024年4月時点での最新モデルはYOLOv8.2になります。
YOLOv8.2では、YOLOv8-Worldモデルがサポートされました。YOLOv8は学習せずに物体を検知できるゼロショットの物体検出を実現しています。
具体的には、自然言語(英語)で検出したい物体を指示し、それを検出する能力を備えています。このため、これまでの物体検出モデルと異なり、追加学習・再学習なしに物体検出を行うことが可能です。
YOLOv8については、以下の記事に詳しく説明しています。

公式によるとYOLOv8-Worldの特徴は以下の通りです。
ちょっと意味不明な部分もありますが、要は高性能で、プロンプトで指定した物体を検出できる物体検出モデルだということです。
また、性能は以下の通りです

ここでは、このモデルを使って、いろいろ遊んでみたいと思います。
YOLOv8のインストールは簡単です。Python(3.8以上)とPyTorch(1.8以上)がインストールされていれば、以下のコマンドを実行すればOKです。
pip install ultralyticsライブラリのインポートも1行です。YOLOWorldをインポートします。
from ultralytics import YOLOWorldモデルの読み込みと生成は以下のコードになります。
model = YOLOWorld('yolov8s-world.pt')上記のコードではyolov8s-worldのモデルを利用していますが、以下のモデルが用意されています。s→m→l→xとモデルが大きくなり、検出精度も向上しますが、処理速度は遅くなります。今回は、sモデルを利用しました。
yolov8s-world
yolov8s-worldv2
yolov8m-world
yolov8m-worldv2
yolov8l-world
yolov8l-worldv2
yolov8x-world
yolov8x-worldv2 物体検出を行う場合は、以下のようになります。
results = model.predict("xxx.jpg")なお、物体追跡を行う場合は以下になります。
results = model.track('xxx.mp4')物体検出(predict)・追跡(track)のオプションなどについては以下の記事に書いていますのでそちらを参考にしてください。
上記のコードでは、デフォルトで学習した物体が検出されます。
YOLO-Worldを使うなら、自然言語(英語)で検出したい物体を指示し、それを検出したいです。自然言語で物体を指示し、検出する場合は以下のようになります。
set_classesであらかじめ検出したい物体のリストを設定しておくことで、predict/trackで検出される物体を指定することができます。
model.set_classes(['person'])
results = model.predict("test2.jpg")使い方は以上になります。以下では、実際にいろいろ試してみます。
モデルを読み込んで、set_classでクラスを設定してsaveで保存することで、検出する物体をカスタムしたモデルを保存できます。
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['person'])
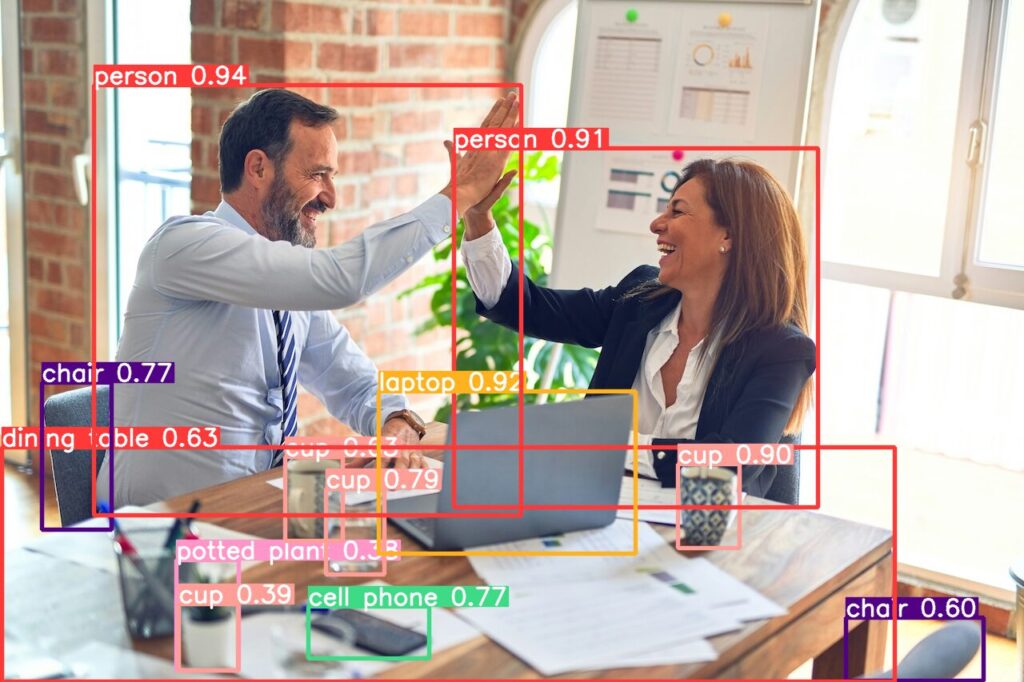
model.save("custom_yolov8s.pt")以下の画像で物体検出を試してみます。

検出する物体を指定しない場合、以下のような検出が行われます
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
results = model.predict("office.jpg")
results[0].show()人物・机・椅子・パソコン(ラップトップ)、カップ、スマホなどが検出されていることがわかります。デフォルトでは、これらのオブジェクトを検出できるようです。
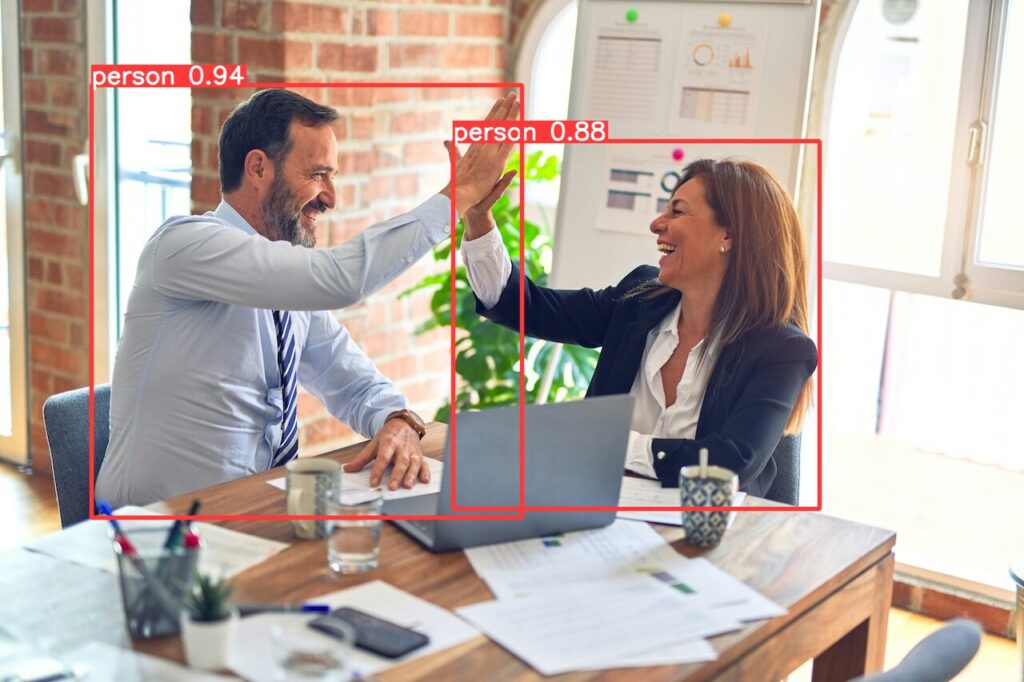
set_classesを利用して人物(person)だけを抜き出すように指示してみます。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['person'])
results = model.predict("office.jpg")
results[0].show()うまく、人だけを検出することができました。
次に、personの代わりにmanを使って検出してみます。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['man'])
results = model.predict("office.jpg")
results[0].show()すると左のひとだけが検出されました。驚いたことに、性別の判定も行なっているようです。

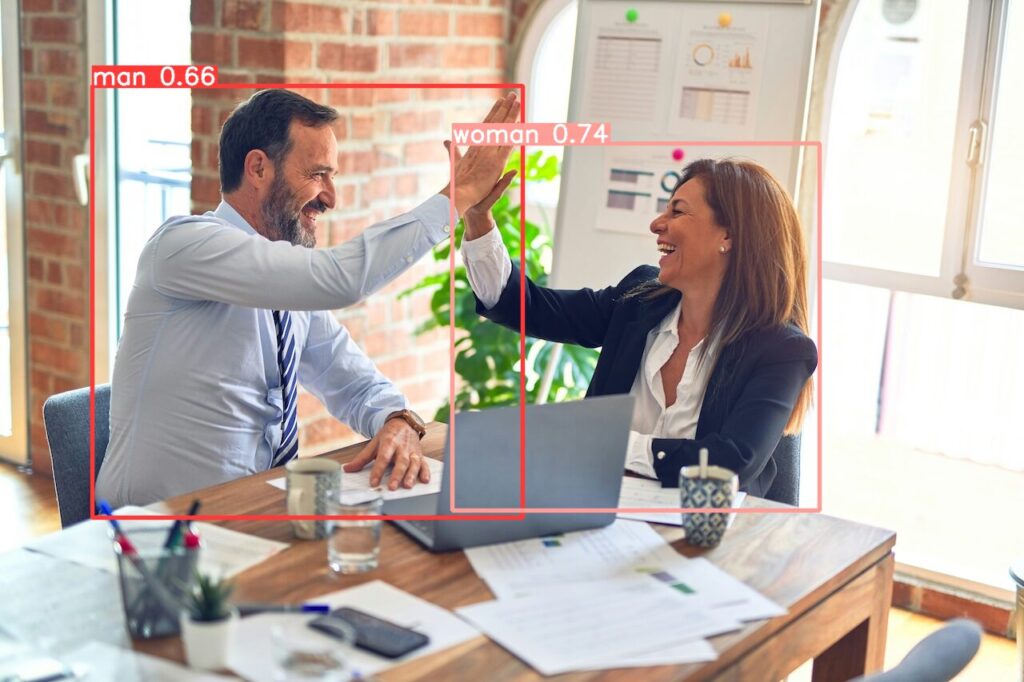
試しに、manとwomanで検出してみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['man', 'woman'])
results = model.predict("office.jpg")
results[0].show()すると、以下のような検出結果になりました。この結果は結構驚きました。自然言語で指定できるとは言え、検出結果がこんな感じで変化するとは考えていませんでした。
モデルは一体どのように学習しているんですかね。
次に、カップ(cup)だけを検出してみます。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['cup'])
results = model.predict("office.jpg")
results[0].show()以下のようにうまくいきました。

狙った物体だけを検出できるというのは、結構便利かもしれません。
次に試したのは以下のような道路の画像です。

まず、車(car)だけを検出してみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['car'])
results = model.predict("traffic.jpg")
results[0].show()できるとは思っていましたが、車を全て検出することができました。

次は、黄色い車(yellow car)だけを検出できるかやってみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['yellow car'])
results = model.predict("traffic.jpg", conf=0.05)
results[0].show()できないだろうと思っていたのですが、見事に黄色い車だけ検出することができました。ちなみに、黒い車、白い車なども試してみましたが、一応検出はするのですが精度がイマイチで他の色の車も検出されていました。
黄色は特にうまく検出できたようです。

信号機(traffic light)も検出してみました。こちらは、そのままではうまくいかなかったので、conf=0.05とかなり信頼度が低くても検出するようにパラメータ調整しています。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['traffic light'])
results = model.predict("traffic.jpg", conf=0.05)
results[0].show()パラメータ調整すると、一応、信号機をいくつか見つけることができました。さすがに画像に対して小さすぎたのかもしれません。

次に試したのは、室内の画像です。結構、いろいろ散らばっていて検出のしがいがある画像です。

とりあえず、conf=0.01にして信頼度が低くても検出するようにしてみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
results = model.predict("kidsroom.jpg", conf=0.01)
results[0].show()すると、以下のように大量の物体を検出することができました。信頼度を無視すると、モデルはこれくらいのものを検出することができるようです。

人(person)を検出してみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['person'])
results = model.predict("kidsroom.jpg")
results[0].show()かなり高い信頼度で3人をみつけることができました。

次は子供(kid)だけ検出してみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['kid'])
results = model.predict("kidsroom.jpg", conf=0.01)
results[0].show()普通には検出できませんでしたが、confを小さな値にすることで検出されました。一応、kidを理解しているようです。

子供(kid)とおもちゃ(toy)で検出してみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['kid', 'toy'])
results = model.predict("kidsroom.jpg", conf=0.01)
results[0].show()閾値を下げると床に転がっているおもちゃに対して枠がついています(枠が多すぎて、全部正解かは不明)。

最後にドア(door)、ピアノ(piano)、ギター(guitar)の検出を行ってみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['door','piano', 'guitar'])
results = model.predict("kidsroom.jpg", conf=0.01)
results[0].show()ピアノとギターは見つけることができたようです。また、家具をドアをまちがっています。
ただ、この家具はconf=0.01で指示なしで検出させた時には枠がついていなかったものです。このあたり、どういう動きをしているのか興味深いです。


set_classのパターンをいろいろ変更すると左側のドアを検出することもありました。挙動がよくわからない部分もあるようです。
動画での検出もやってみました。
from ultralytics import YOLOWorld
model = YOLOWorld('yolov8s-world.pt')
model.set_classes(['cat'])
results = model.track('test2.mp4', show=True)猫だけを追跡するようにしています。

同じ画像を、YOLOv8で物体検出する例が下記の記事にあります。猫だけが追跡対象になっているのを確認することができます。
ちなみに、Macbook Air M2(16GB)で、640×480サイズの画像を100~150msくらいで処理できています。なので、この動画を10fps前後で処理できたことになります。思ったより高速です。
M2プロセッサの場合は、内蔵GPUが利用されるのでCPU単独と比較すると少し高速です。
以上、YOLOv8-Worldモデルを使ってみました。再学習をせずに、自然言語で物体を支持して検出できるというのは結構新鮮です。性能的には再学習させた方が良いとは思いますが、再学習せずに手軽にアプリに物体検出を組み込めるようになるのは大きいなと感じます。



