木構造のグラフの重心を簡単に求める方法|Pythonによるアルゴリズム解説
Aru
Aru's テクログ(Aruaru0)

Union-Find(またはDisjoint Set Union, DSU)は、グループ管理を効率的に行うためのデータ構図です。グラフの処理や、クラスター分析などでよく利用されるデータ構造で、AtCoderなどの競技プログラミングの世界でも頻繁に利用されるデータ構造です。この記事では、PythonでUnionFindクラス(DSUクラス)を実装する方法と、使い方を解説します。

UnionFind(または、DSU, Disjoint Set Union)と呼ばれるデータ構造は、データの集合を素集合に分割して管理するデータ構造です(WikiPedia)。
このデータ構造を用いると、「ある要素XとYが同じ集合に含まれているか?」「要素Xと同じ集合に含まれている要素の個数」などを高速に求めることが可能です。
このデータ構造に対する基本操作は以下になります
merge(x, y)union(x,y),unite(x,y)などと書かれることもあります。xを含む集合と、yを含む集合を統合して1つの集合する処理です。merge(x, y)とmerge(y, z)を行うと、xとzは同じ集合に含まれるようになるのが特徴です。このように集合の結合を行うのがMergeです。leader(X)find(X)と書くこともあります。Xを含む集合の代表の要素を返します。同じ集合に含まれる要素であれば、代表の要素の値は同じになります。グラフとして考えると、これは根(Root)になります。また、これ以外に以下の操作を用意することもあります。
same(X, Y)size(X)groups()これらを高速に行うことができるUnion-Findは、知っておくと意外と実務でも重宝します。

個人的には、kaggleのコンペのデータ分析などに使うこと多いです。特に、Kaggleだと実行時間に制限があるので、検索処理を高速化できれば、その分他の解析処理ができるようになり有利です。
また、実務でも「知っていて良かった」というシチュエーションに何度か遭遇したのを覚えています。
UnionFindをPythonで実装します。今回はクラスとして実装することにします。
コード全体はここにあります。
実装ではUnionFindではなく、DSUとしています。AtCoderのライブラリに合わせた形です。
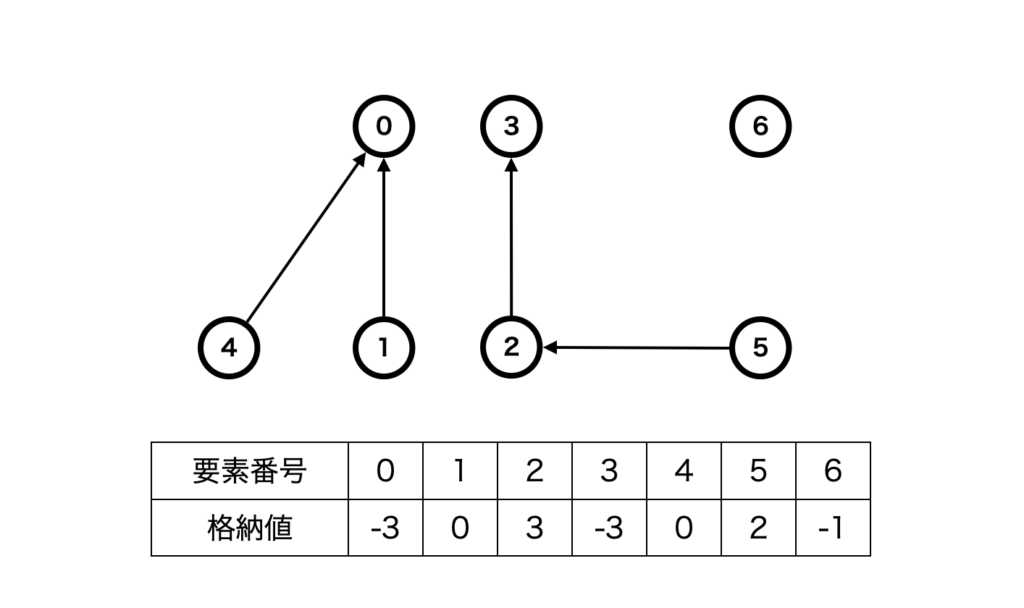
以下の図はデータ構造をグラフで表現したものです。
UnionFindのデータの実態はリストです。
例ではノードが7個あるので、サイズ7のリストなります。
管理する必要があるのは「親となる要素の番号」と「接続されているノード数」ですが、代表の要素(集合を代表するノード)に関しては「親となる要素の番号」は必要なく、また、それ以外のノードについては「接続されているノード数」を管理する必要がないので、代表ノードは要素数を、その他は親のノードを記録するようにすれば1つのリストで管理可能です。
このとき、要素数を負、親の要素の番号を正で表現することにすれば、要素数と要素番号を区別することができます。
下図では、要素0, 1, 4が同じ集合に、2, 3, 5が同じ集合に、そして6が単独の要素として示されています。集合の代表要素となる要素0, 3, 6には、それぞれの集合の要素数が格納されています(負数として)。他のノードは親のノードの要素番号が格納されています。
以下では、このような配列を生成するコードを実装します。
まずクラスの雛形を作成します。__init__()は、初期化を行う関数です。また、その他は、上で説明した関数になります。
class DSU:
def __init__(self, n) :
def merge(self, a, b) :
def same(self, a, b) :
def leader(self, a) :
def size(self, a) :
def groups(self) :__init__)初期化では、要素数nを受け取って、配列を初期化します。
引数は、要素数nです。最初は、すべての要素は別々の集合なので、配列は-1に初期化しておきます。こうすることで、それぞれが1個だけの集合だと定義されます。
def __init__(self, n) :
self.n = n
self.parentOrSize = [-1] * n 集合の代表要素の番号を返す関数です。
要素の値が負数になるまで再起的に呼び出せば、代表要素の番号を返すことができます。
def leader(self, a) :
if self.parentOrSize[a] < 0 :
return a
self.parentOrSize[a] = self.leader(self.parentOrSize[a])
return self.parentOrSize[a]集合aとbを結合する関数です。
それぞれの集合の代表(Leader)を調べて、片方を反対側の集合に繋げます。
これで全体が1つの集合となります。
サイズ比較してどちらを親にするか決める処理が入っていますが、これは、深さを小さくするためのテクニックです。
def merge(self, a, b) :
x, y = self.leader(a), self.leader(b)
if x == y :
return x
if -self.parentOrSize[x] < -self.parentOrSize[y] :
x, y = y, x
self.parentOrSize[x] += self.parentOrSize[y]
self.parentOrSize[y] = x
return x要素aとbの代表要素(Leader)が同じかどうか調べて返すだけです。
def same(self, a, b) :
return self.leader(a) == self.leader(b)要素数を返すSizeもLeaderが実装できていれば簡単に実装することができます。
def size(self, a) :
return -self.parentOrSize[self.leader(a)]グループをリスト化して返します。Leaderで親を調べて、親のリストに要素を加えていきます。前半部分はdict(辞書型)を使って、それぞれの要素がどの代表要素のグループに含まれるかを求めています。
最終的に、辞書をリストに変換してリストとして返しています。
def groups(self) :
m = {}
for i in range(self.n) :
x = self.leader(i)
if x in m :
m[x].append(i)
else :
m[x] = [i]
return list(m.values())以下のような使い方をします。
uf = DSU(要素数)という形で最初にインスタンスを生成します。
uf = DSU(10)
uf.merge(0, 1)
uf.merge(2, 3)
uf.merge(4, 5)
uf.merge(6, 7)
uf.merge(8, 9)
uf.merge(0, 3)
for e in range(10):
print(uf.leader(e), uf.leader(e))
print(uf.same(0, 1))
print(uf.same(2, 3))
print(uf.same(4, 5))
print(uf.same(6, 7))
print(uf.same(8, 9))
print(uf.same(1, 9))
print(uf.groups())出力結果
0 4
0 4
0 4
0 4
4 2
4 2
6 2
6 2
8 2
8 2
True
True
True
True
True
False
[[0, 1, 2, 3], [4, 5], [6, 7], [8, 9]]UnionFindは結構簡単に実装できるのに、かなり便利なデータ構造です。実装の流れを含め覚えておくと良いです。
以下に、コード全体をつけておきます。テンプレ的に使ってもらってもOKです。
#
# Disjoint Set Union: Union Find Tree
#
class DSU:
def __init__(self, n) :
self.n = n
self.parentOrSize = [-1] * n
def merge(self, a, b) :
x, y = self.leader(a), self.leader(b)
if x == y :
return x
if -self.parentOrSize[x] < -self.parentOrSize[y] :
x, y = y, x
self.parentOrSize[x] += self.parentOrSize[y]
self.parentOrSize[y] = x
return x
def same(self, a, b) :
return self.leader(a) == self.leader(b)
def leader(self, a) :
if self.parentOrSize[a] < 0 :
return a
self.parentOrSize[a] = self.leader(self.parentOrSize[a])
return self.parentOrSize[a]
def size(self, a) :
return -self.parentOrSize[self.leader(a)]
def groups(self) :
m = {}
for i in range(self.n) :
x = self.leader(i)
if x in m :
m[x].append(i)
else :
m[x] = [i]
return list(m.values())