Segmentation Anything(SAM)によるゼロショットセグメンテーション|使い方
Aru
Aru's テクログ(Aruaru0)

いつのまにかYOLO11が登場していましたので、以前YOLOv8/v9やった独自のカスタムデータ(オリジナルデータ)を使った物体検出(Object Detection)の学習と推論をやってみました。本記事も、前回と同じデータセットを使ってYOLOv11での学習を行いました。

今回紹介するのは、Ultralytics社のgithubリポジトリにあるYOLO11です。YOLOv8/v9についてはウォッチしていたのですが、最近は大規模言語モデル(LLM)の方を追っかけていたら、いつの間にか11にアップしていました。

この記事では、YOLO11のライブラリの使い方を中心に解説します。YOLO11の技術的な改善点については触れません。興味のある方は以下の論文を参照してみてください。
arXiv: https://arxiv.org/abs/2410.17725

YOLO11も以前のモデルと同様に、物体検出(Detect)、セグメンテーション、姿勢推定、物体追跡などの複数のタスクに対応しています。
今回は、このYOLO11を使って、自分で用意したデータを学習し、学習した結果を用いて推論するという一連の流れをPythonを使って行います。
なお、学習・推論のコードはKaggle Notebookに公開していますので参考にしてください。
以下は、公式にある性能グラフです。YOLOv8→v9→v10→11と性能がアップしていることがわかります。また、同じ性能であればYOLO11が高速です。
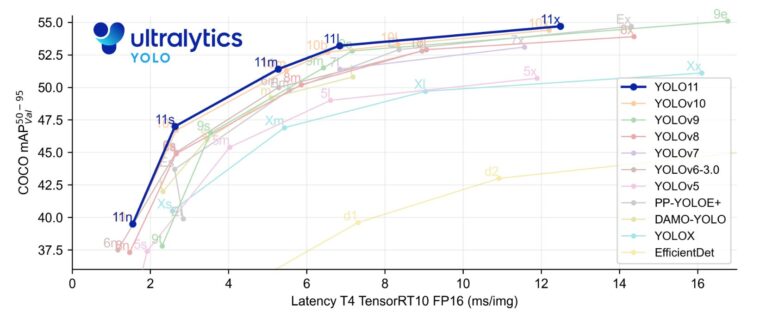
この速度で進化されると、自分でモデルを作ったり、改良したりするより公開モデルをそのまま利用した方が良い気さえしてきます。
モデルの一覧は以下の通りです。
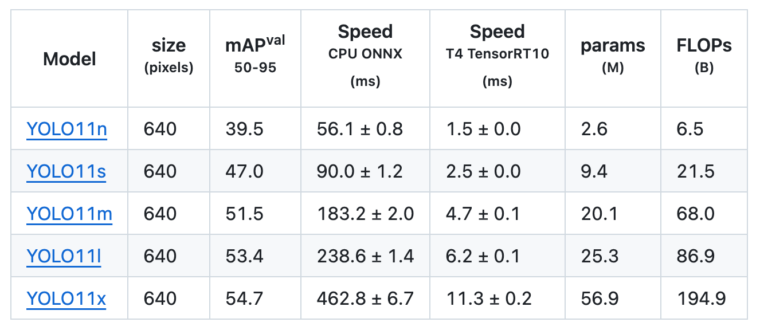
YOLOv8nとYOLOv9nを比較すると、mAPが37.3→39.5にアップ、CPUでの速度は80.4ms→56.1msとスピードアップ、パラメータ数も3.2M→2.6Mと小さくなっています。
もちろんOBB(Oriented Bounding Box)にも対応していますので応用範囲も広いです。
OBBは回転したバウンディングボックスのことです(縦横水平垂直ではなく、斜め角度の枠などを表現可能です)。厳密に枠をつけたい場合に利用します
今回も、kaggleのCar Object Detectionデータセットを利用して学習を行います。このデータは車両にアノテーションが行われたデータです。
自分で画像を収集した場合は、自身でアノテーションを行わなければなりません。YOLOフォーマットでアノテーションを行う場合、LabelStudioやLabelImgが便利です。LabelImgはサポートが終了していますが、ちょっとしたアノテーションには便利が良いので個人でちょっとアノテーションする場合はこちらがおすすめです。
アノテーションの方法については、以下の記事を参考にしてください



YOLO11を利用するにはultralyticsのYOLOパッケージをインストールする必要があります。
そのほかにもPython>=3.8, Pytorch>=1.8が必要になりますが、Kaggle NotebookやCoogle Colabの場合はこれらはインストール済みなので、ultralyticsだけインストールすればOKです。
Notebookの先頭で以下のコマンドを実行してインストールします。
# install yolov8
!pip install ultralyticsultralyticsからYOLOを、また必要なパッケージをインポートします。必要なパッケージはコード実行に必要となるものです(必要のないものも含まれているかもしれせんが問題ありません)
from ultralytics import YOLO
import os
import random
import shutil
import numpy as np
import pandas as pd
import cv2
import yaml
import matplotlib.pyplot as plt
import glob
from sklearn.model_selection import train_test_splitトレーニング用のデータセットを準備します。今回は、kaggleのCar Object Detectionデータセットを利用します。
このデータセットは、テスト用の画像フォルダと訓練用の画像フォルダが用意されており、それぞれjpegフォーマットで画像が格納されています。
また、アノテーションデータがcsvファイル形式で準備されています。
このため自分でアノテーションを行う必要はありません。
まずは、データのあるディレクトリ等を変数に設定しておきます。
IMAGESとLABELSはYOLOフォーマットに変換したデータを格納する場所です。また、TRAINとTESTは変換前のデータが格納された場所です。
DIR = "/kaggle/working/datasets/cars/"
IMAGES = DIR +"images/"
LABELS = DIR +"labels/"
TRAIN = "/kaggle/input/car-object-detection/data/training_images"
TEST = "/kaggle/input/car-object-detection/data/testing_images"次に、アノテーションデータが格納されたcsvファイルを読み込みます。
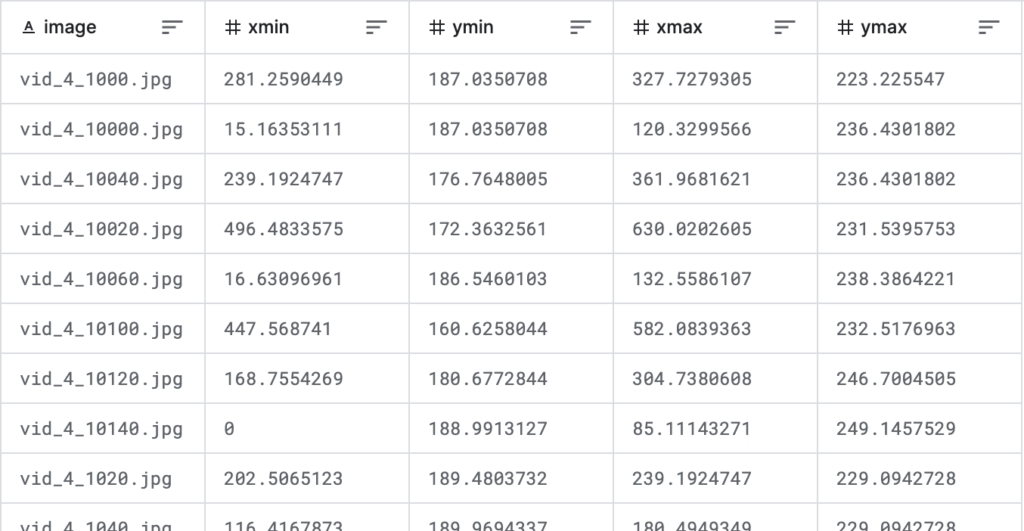
df = pd.read_csv("/kaggle/input/car-object-detection/data/train_solution_bounding_boxes (1).csv")
dfファイルの内容は以下のようになります。1列目は画像ファイル名、2列目〜5列目は枠の場所で、1行が1つの枠に対応しています。
提供されるファイルはtrainとtestだけですが、ここではtrainデータを訓練用(train)と評価用(validation)に分割します。これには、train_test_split関数を利用します。
ここでは、test_size=0.2とし訓練用と評価用を8:2の割合に分割しました。
files = list(df.image.unique())
files_train, files_valid = train_test_split(files, test_size = 0.2)次に、YOLOフォーマットで格納するフォルダにtrainとvalidフォルダを作成します。フォルダは画像(IMAGES)とラベル(LABELS)それぞれに用意します。
なお、exist_okは、すでにフォルダが存在している場合にエラーにならないように指定してます。
# make directories
os.makedirs(IMAGES+"train", exist_ok=True)
os.makedirs(LABELS+"train", exist_ok=True)
os.makedirs(IMAGES+"valid", exist_ok=True)
os.makedirs(LABELS+"valid", exist_ok=True)フォルダが準備できたら、画像ファイルをコピーしていきます。
train_filenameにファイル名が存在する場合には訓練用、そうでない場合は評価用のフォルダにコピーしています。
train_filename = set(files_train)
valid_filename = set(files_valid)
for file in glob.glob(TRAIN+"/*"):
fname =os.path.basename(file)
if fname in train_filename:
shutil.copy(file, IMAGES+"train")
elif fname in valid_filename:
shutil.copy(file, IMAGES+"valid")画像をコピーしたら、YOLOフォーマットのアノテーションデータを作成します。
YOLOフォーマットでは、画像ファイルと同名のテキスト(.txt)データを作成してそこに枠情報を配置していきます。
以下は、与えられたCSVデータからアノテーションデータを作成するコードです。
YOLOフォーマットでは、(クラスID, X中心、Y中心、W、H)の順でテキストファイルに書き込みを行います。なお、元のデータは676×380のサイズでの(xmin, ymin)-(xmax, ymax)という座標になっていますが、YOLOフォーマットでは、中心座標と幅と高さ情報のデータが必要となりますので変換が必要です。また、スケールも画像の幅、高さを1.0としたスケールで指定する必要があります。
ここではCSVのデータを(クラスID, X中心、Y中心、W、H)に変換すると同時に、スケールも0.0〜1.0に変換しています。
for _, row in df.iterrows():
image_file = row['image']
class_id = "0"
x = row['xmin']
y = row['ymin']
width = row['xmax'] - row['xmin']
height = row['ymax'] - row['ymin']
x_center = x + (width / 2)
y_center = y + (height / 2)
x_center /= 676
y_center /= 380
width /= 676
height /= 380
if image_file in train_filename:
annotation_file = os.path.join(LABELS) + "train/" + image_file.replace('.jpg', '.txt')
else:
annotation_file = os.path.join(LABELS) + "valid/" + image_file.replace('.jpg', '.txt')
with open(annotation_file, 'a') as ann_file:
ann_file.write(f"{class_id} {x_center} {y_center} {width} {height}\n")YOLOのフォーマットでは、アノテーションデータは以下のフォーマットになります(xy座標と幅は、画像の幅、高さを1とした値(0~1)になります)
クラスID Xの中心 Yの中心 W H
クラスID Xの中心 Yの中心 W H
クラスID Xの中心 Yの中心 W H
: (オブジェクトの数だけ繰り返し)
下図は、フォーマット変換のイメージ図です。dfの内容を解析し、YOLOフォーマットに変換し、対応するtextファイルに書き出します。open(annotation_file, 'a')と追加モードでファイルをopenしているので、同じ画像に対する枠情報は1つのファイルに追記されることになります。
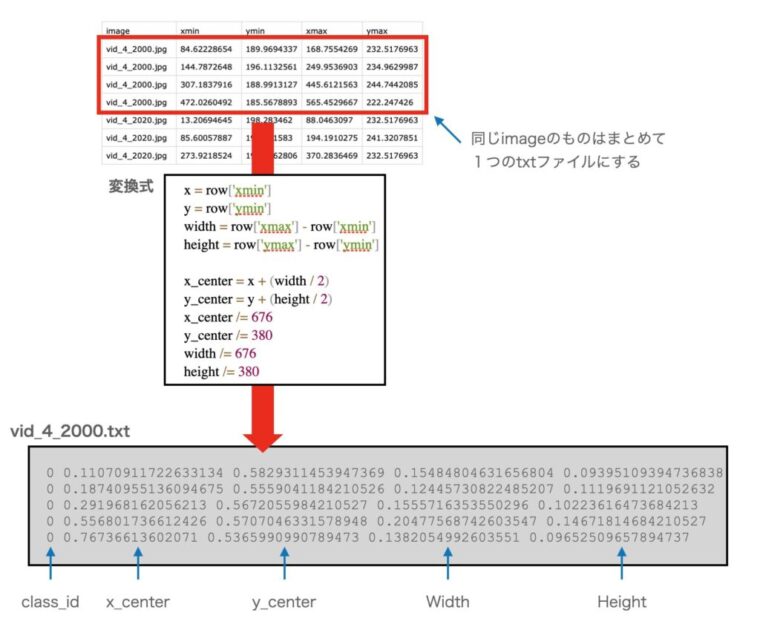
変換の処理を図示すると、以下のようなイメージなります。

変換後のフォルダ構成は以下のようになります。
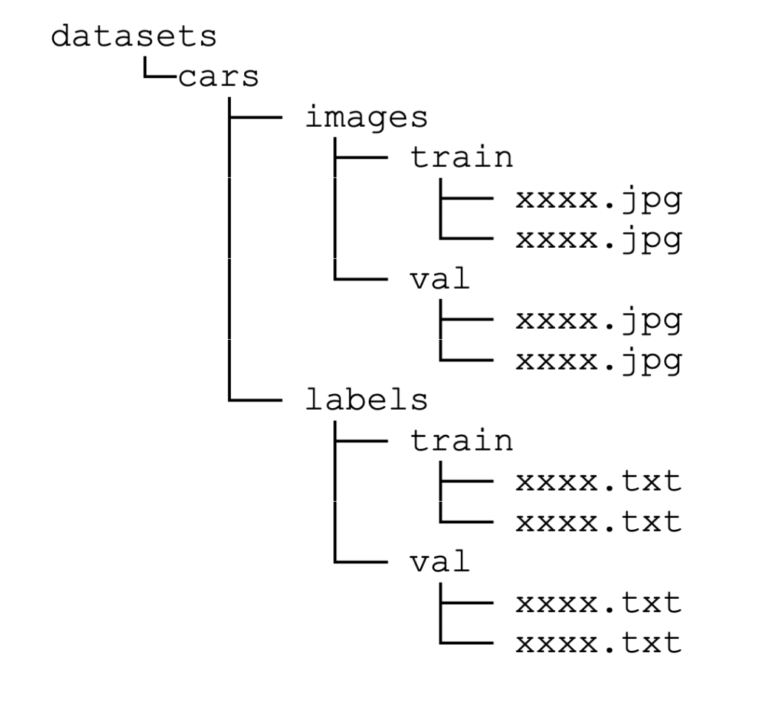
以上でデータセットの準備は完了です。
実は、学習よりも、枠情報がない場合のアノテーションや、枠情報が存在してもYOLOフォーマットでないデータ場合のYOLOフォーマットに変換する作業が一番面倒だったりします。有名なフォーマットについては、コンバーターなどが存在していますのでそれを積極的に利用することをお勧めします。
枠情報がないデータを利用して学習する場合、アノテーション作業が必要になります。結構面倒ですが、ツールを使うことで大分楽になります。ちょっとしたあのーてションの場合には、LabelImg、本格的な場合はLabelStudioをお勧めします。これらのツールについては以下を参照してください。
先に説明した手順でデータセットを作成した場合は、以下のようなフォルダ構造ができているはずです。carsフォルダがデータセットのフォルダで、imagesとlabelsの下に画像と枠情報が格納されています。
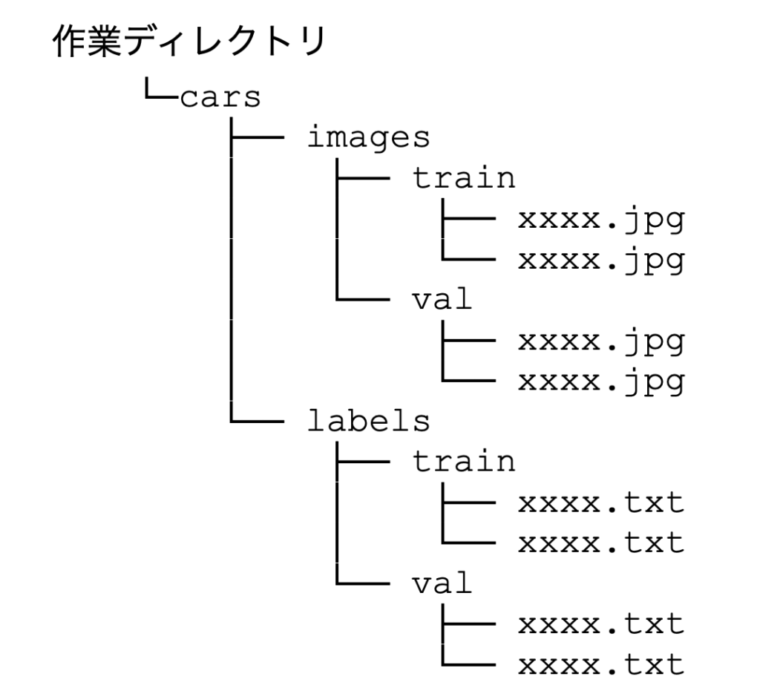
これらの設定をトレーニングに反映させるために、yamlファイル(設定ファイル)を作成します。Notebookでyamlファイルを作成するには、マジックコマンドを利用します。

1行目の%%writefileはファイルに書き出すためのマジックコマンドで、セルの内容が指定したファイル名で書き出されます。
下記は、trainとvalidのフォルダと、クラス数とクラス名を指定するyamlファイルを書き出すものです。
%%writefile dataset.yaml
# Path
path: ./cars
train: images/train
val: images/valid
# Classes
nc: 1
names: ['car']注意ポイント
学習中にwandbへアクセスしようとする場合は以下のコードでwandbを停止させてください。アカウントを持っている場合は、接続して、実験記録を保存させることで学習の記録してもOKです
# disable wandb
import wandb
wandb.init(mode="disabled")yamlファイルを作成したら、いよいよ学習です。
学習はモデルのtrain()を呼び出すだけです。あとは、訓練が終了するまで待ちます。
model = YOLO('yolo11n.pt')
model.train(data="dataset.yaml", epochs=100, batch=8)今回は、YOLO11のモデルの中で一番小さいモデルを選びましたが、yolo11n.pt以外に、以下のものを選ぶことができます。
モデルサイズはn→s→m→l→xの順番で大きくなり、サイズが大きくなるほど処理時間が大きくなるしGPUのメモリも必要になりますので注意してください。
train)の引数について以下は、trainに指定できる引数の一覧です。引数を指定するだけで、スケジューラを切り替えたり、ラベルスムージングのON/OFFができたりと、ハイパーパラメータの細かな調整が可能です。
| 引数 | 例 | 説明 |
|---|---|---|
model | None | モデル名またはモデルファイルへのパス, i.e. yolov8n.pt, yolov8n.yaml |
data | None | データファイルへのパス(xxxx.yamlファイル) |
epochs | 100 | EPOCH数 |
patience | 50 | 性能改善しないときに、早期打ち切りするまでのEPOCH数( Early Stopping) |
batch | 16 | バッチサイズ(-1で自動) |
imgsz | 640 | 入力の画像サイズ(整数 または w, h) |
save | True | 訓練中の予測結果とチェックポイントを保存 |
save_period | -1 | チェックポイントの間隔(EPOCH数、-1の場合は無効) |
cache | False | キャッシュあり・なし |
device | None | デバイス GPUの場合、device=cudaの場合は0,1,2,3。マルチCPUの場合は[0,1]など CPUの場合、device=’cpu’。 M1/M2Macの場合、device=’mps’が利用可能 |
workers | 8 | ワーカースレッドの数 |
project | None | プロジェクト名 |
name | None | 実験名 |
exist_ok | False | 同じ実験がある場合、記録を上書きするかどうか |
pretrained | False | トレーニング済みモデルを利用するかどうか |
optimizer | 'auto' | オプティマイザ SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto |
verbose | False | 詳細出力をするかどうか |
seed | 0 | 乱数のシード |
deterministic | True | deterministicモードを有効にするかどうか。再現性に影響 |
single_cls | False | マルチクラスデータをシングルクラスとして訓練するかどうか |
rect | False | rectangular training with each batch collated for minimum padding |
cos_lr | False | コサインスケジューラを使用するかどうか |
close_mosaic | 0 | (int) 最終EPOCHではモザイクオーグメンテーションを無効にする |
resume | False | 訓練を最後のチェックポイントから再開する |
amp | True | Automatic Mixed Precision (AMP) を使うかどうか |
fraction | 1.0 | 訓練に使うデータセットの割合 (デフォルトは全部(1.0)) |
profile | False | profile ONNX and TensorRT speeds during training for loggers |
lr0 | 0.01 | 初期の学習率 |
lrf | 0.01 | 最後の学習率 |
momentum | 0.937 | SGD momentum/Adam beta1 |
weight_decay | 0.0005 | optimizer weight decay 5e-4 |
warmup_epochs | 3.0 | ウォームアップEPOCH数 |
warmup_momentum | 0.8 | ウォームアップ時の初期momentum |
warmup_bias_lr | 0.1 | ウォームアップ時の初期lr |
box | 7.5 | box lossのgain |
cls | 0.5 | cls(クラス) lossのgain (scale with pixels) |
dfl | 1.5 | dfl lossの gain |
pose | 12.0 | pose loss のgain (pose-only) |
kobj | 2.0 | keypoint obj lossの gain (pose-only) |
label_smoothing | 0.0 | ラベルスムージング |
nbs | 64 | nominal batch size |
overlap_mask | True | masks should overlap during training (segment train only) |
mask_ratio | 4 | mask downsample ratio (segment train only) |
dropout | 0.0 | ドロップアウト率 (classify train only) |
val | True | 訓練中に検証を行うかどうかのフラグ |
YOLO11の学習の結果はグラフ形式で格納されています。
格納場所とファイル名は.run/detect/train/result.pngです。
以下のコードはこのファイルを読み込み、表示するものです。
from IPython.display import Image
Image("/kaggle/working/runs/detect/train/results.png")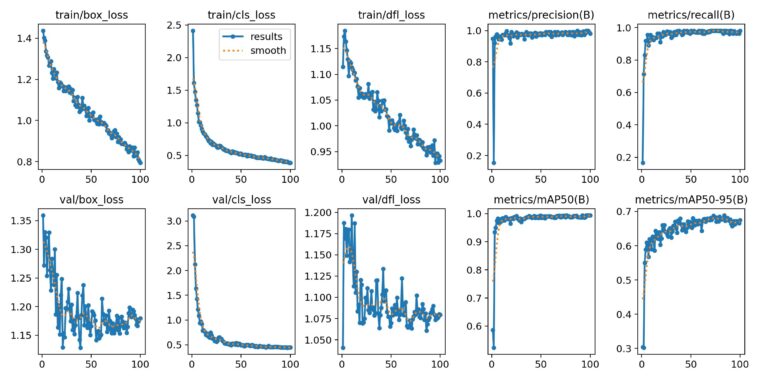
結果を見ると、train lossは順調に下がっていることがわかります。また、val lossは若干乱れていますが、徐々に収束しています。今回100epoch学習させましたが、学習回数を増やせばまだまだ学習する雰囲気があります。ただ、mAP50は10epoch付近で1.0に近くなっているので、10epoch程度である程度学習ができていることもわかります。
物体検出ではmAPで評価することが多いです
学習したモデルを実際に使って推論してみます。
YOLO11の場合、推論コードもシンプルです。まず、学習したパラメータを読み込んでモデルを生成し、引数に画像ファイルやフォルダを指定して呼び出すだけです。
今回は、データセットのtesting_imagesフォルダにある画像を利用しました。この画像はトレーニングには利用していない画像です。
また、引数でconf=0.2, iou=0.5として検出の閾値を設定しています。confはクラスの確らしさ、iouは枠の確らしさの閾値で、これを超えたものだけが検出されることになります。
model = YOLO('./runs/detect/train/weights/last.pt')
ret = model("/kaggle/input/car-object-detection/data/testing_images",save=True, conf=0.2, iou=0.5)処理結果は、./runs/detect/predictに格納されます。以下のコードは、格納されている画像のいくつかを表示するものです。
# display result
files = glob.glob("./runs/detect/predict/*")
for i in range(0, 30, 3):
img = Image(files[i])
display(img)結果を見ると、きちんと車に枠が付いているようです。枠の上の数値は枠の確らしさです。

車が写っていない画像では、誤検出も起きていないようです。



以下は、推論時のパラメータの一覧です。
推論側もかなりのパラメータを指定可能です。
| 引数 | 例 | 説明 |
|---|---|---|
source | 'ultralytics/assets' | ソース画像/映像データのディレクトリ |
conf | 0.25 | 検出するオブジェクトの閾値 |
iou | 0.7 | NMSの交差判定のIoUの閾値 |
half | False | FP16を利用するかどうかのフラグ |
device | None | 実行するデバイス。GPU(cuda) = 0/1/2/3または”cpu” |
show | False | 結果を表示(可能な場合) |
save | False | 結果画像を保存するかどうか |
save_txt | False | 結果をテキストファイルで保存するかどうか |
save_conf | False | 結果に信頼度スコアを含めて保存するかどうか |
save_crop | False | 結果に切り取った画像を含めて保存するかどうか |
hide_labels | False | ラベルを隠す(非表示にする) |
hide_conf | False | 信頼度スコアを隠す(非表示にする) |
max_det | 300 | 最大検出数 |
vid_stride | False | video frame-rate stride |
line_width | None | バウンディングボックスのライン幅。Noneの場合は画像サイズに合わせて自動調整 |
visualize | False | モデルの特徴を可視化するかどうか |
augment | False | データ拡張を予測で利用するかどうか |
agnostic_nms | False | class-agnostic NMS |
retina_masks | False | 高解像度のセグメンテーションマスクを利用するかどうか |
classes | None | filter results by class, i.e. class=0, or class=[0,2,3] |
boxes | True | セグメンテーションに枠を表示するかどうか |
ソース(source)として設定できるのは以下になります。これをみるとYoutubeやrtspから直接入力することができるようです。
| ソース名 | 例 | データ型 | コメント |
|---|---|---|---|
| image | 'image.jpg' | str or Path | 単一の画像ファイル |
| URL | 'https://ultralytics.com/images/bus.jpg' | str | 画像のURL |
| screenshot | 'screen' | str | スクリーンショットのキャプチャ |
| PIL | Image.open('im.jpg') | PIL.Image | RGB画像(Height、Width, Channel)フォーマット |
| OpenCV | cv2.imread('im.jpg') | np.ndarray of uint8 (0-255) | BGR画像(Height、Width, Channel)フォーマット |
| numpy | np.zeros((640,1280,3)) | np.ndarray of uint8 (0-255) | BGR画像(Height、Width, Channel)フォーマット |
| torch | torch.zeros(16,3,320,640) | torch.Tensor of float32 (0.0-1.0) | RGB画像(Batch, Channel, Height, Width)フォーマット |
| CSV | 'sources.csv' | str or Path | 画像、ビデオ、またはディレクトリへのパスを含むCSVファイル |
| video | 'video.mp4' | str or Path | MP4、AVIなどのビデオファイル |
| directory | 'path/' | str or Path | 画像または動画を含むディレクトリへのパス |
| glob | 'path/*.jpg' | str | ワイルドカードなどを含んだ画像ファイル名 (*.jpgなど) |
| YouTube | 'https://youtu.be/Zgi9g1ksQHc' | str | YoutubeのURL |
| stream | 'rtsp://example.com/media.mp4' | str | RTSP, RTMPのURLやIPアドレス(WebカメラなどのRTSPアドレス) |
今回はYOLO11を使って、独自データの学習と推論を行ってみました。基本的にはYOLOv8とほとんど同じコードで学習・推論することができました。ultralyticsのYOLOはモデル名だけ入れ替えればYOLOv8と同じように使うことができるようです。
なので、以前のYOLOで作ったアプリも簡単にアップデートすることができそうです。