深層学習の指標Perplexityを解説【初級 深層学習講座】
Aru
Aru's テクログ(Aruaru0)

M5搭載のMacBook Airが機械学習用途にどこまで使えるのかを検証しました。以前行ったM4 Max搭載MacBook Proのベンチマークと同じ条件で測定し、実用面での性能差を比較しています。
持ち歩き用のMacBook Airを更新したので、ディープラーニング関連の性能チェックをしてみました。MacBook Neo, MacBook Air(M5)の通常のベンチマークは巷にあふれていますが、機械学習系は少ないので参考になればと思います。
M4Maxのベンチマークは以下の記事を参考にしてください。

最初に評価結果です。結論から言うと、以下のような用途であれば十分な性能だと感じました
一方で、大規模な学習を行う場合は、上位機種やクラウドGPUの利用が適していると思います。
本機は、あくまで“ちょっとした機械学習環境”として優秀なマシンという位置づけです。
今回ベンチマークするのは、10コアCPU, 10コアGPUのモデルになります。
13インチ MacBook Air M5(10CPU, 10GPU)
メモリ 24GB, SSD 1TB
ベンチマークを行ったプログラムはM4Maxと同じです。
このプログラムは、CIFAR-10という10種類の「物体カラー写真」(乗り物や動物など)の画像データセットを学習データとして、ResNet18という画像識別(クラス分類)のモデルを学習させる典型的なものになります。ResNet18はtorchvisionにモデルが用意されているのでそれを読み込んでいます。

前回のベンチマークと同様に、multiprocessing_context="fork"を設定しています。これは、macOSのPythonのマルチプロセッシングの起動と終了処理の速度問題を解消するためです。
また、CPUの数が10になっているので、num_workersを10にして実行しています。コードは以下の通りです。
import torch
from torch.nn import CrossEntropyLoss
from torch.optim import SGD
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
from torchvision import transforms as tt
from torchvision.models import resnet18
import os
from argparse import ArgumentParser
import time
def main(device):
# ResNetのハイパーパラメータ
n_epoch = 5 # エポック数
batch_size = 512 # ミニバッチサイズ
momentum = 0.9 # SGDのmomentum
lr = 0.01 # 学習率
weight_decay = 0.00005 # weight decay
worker_setting = {"num_workers": 10,
"multiprocessing_context":"fork"}
# 訓練データとテストデータを用意
mean = (0.491, 0.482, 0.446)
std = (0.247, 0.243, 0.261)
train_transform = tt.Compose([
tt.RandomHorizontalFlip(p=0.5),
tt.RandomCrop(size=32, padding=4, padding_mode='reflect'),
tt.ToTensor(),
tt.Normalize(mean=mean, std=std)
])
test_transform = tt.Compose([tt.ToTensor(), tt.Normalize(mean, std)])
root = os.path.dirname(os.path.abspath(__file__))
train_set = CIFAR10(root=root, train=True,
download=True, transform=train_transform)
train_loader = DataLoader(train_set, batch_size=batch_size,
shuffle=True, **worker_setting)
# ResNetの準備
resnet = resnet18()
resnet.fc = torch.nn.Linear(resnet.fc.in_features, 10)
# 訓練
criterion = CrossEntropyLoss()
optimizer = SGD(resnet.parameters(), lr=lr,
momentum=momentum, weight_decay=weight_decay)
train_start_time = time.time()
resnet.to(device)
resnet.train()
for epoch in range(1, n_epoch+1):
train_loss = 0.0
for inputs, labels in train_loader:
inputs = inputs.to(device)
optimizer.zero_grad()
outputs = resnet(inputs)
labels = labels.to(device)
loss = criterion(outputs, labels)
loss.backward()
train_loss += loss.item()
optimizer.step()
print('Epoch {} / {}: time = {:.2f}[s], loss = {:.2f}'.format(
epoch, n_epoch, time.time() - train_start_time, train_loss))
print('Train time on {}: {:.2f}[s] (Train loss = {:.2f})'.format(
device, time.time() - train_start_time, train_loss))
# 評価
test_set = CIFAR10(root=root, train=False, download=True,
transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size,
shuffle=False, **worker_setting)
test_loss = 0.0
test_start_time = time.time()
resnet.eval()
for inputs, labels in test_loader:
inputs = inputs.to(device)
outputs = resnet(inputs)
labels = labels.to(device)
loss = criterion(outputs, labels)
test_loss += loss.item()
print('Test time on {}: {:.2f}[s](Test loss = {:.2f})'.format(
device, time.time() - test_start_time, test_loss))
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--device', type=str, default='mps',
choices=['cpu', 'mps', 'cuda'])
args = parser.parse_args()
device = torch.device(args.device)
main(device)
実行結果は以下のようになります。
Epoch 1 / 5: time = 10.56[s], loss = 171.88
Epoch 2 / 5: time = 21.05[s], loss = 139.11
Epoch 3 / 5: time = 31.49[s], loss = 124.26
Epoch 4 / 5: time = 41.92[s], loss = 113.71
Epoch 5 / 5: time = 52.37[s], loss = 105.69
Train time on mps: 52.37[s] (Train loss = 105.69)
Test time on mps: 0.85[s](Test loss = 20.38)処理時間は52.37秒です。
ベンチマークの結果です。比較のためにGoogle Colab(T4)も入れています。この結果を見ると、すでに無料で使えるGoogle ColabのGPUより高速に処理できていることがわかります。ResNet18は、小さいモデルですが、一応まともなモデル(実用レベル)ですが、MacBook Airで十分学習できるようです。さすがにM4Maxには敵いませんが価格差を考えると十分だと思いました。
| 学習処理の時間 | |
| MacBook Air(M5) | 52.37秒 |
| MacBook Pro(M4Max) | 21.16秒 |
| Google Colab(T4) | 141.67秒 |
YOLOv8は軽量・高精度な物体検出モデルで、実務での利用例が多いモデルです。ここでは、このYOLOv8の学習の実験を行いました。コードや手順は以下の記事と同じです。

CPUで学習した結果です。
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 0G 1.45 2.718 1.204 5 640: 100% ━━━━━━━━━━━━ 36/36 1.4it/s 25.1s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 5/5 1.1it/s 4.5s
all 71 100 0.0046 0.98 0.038 0.0174
(略)
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 0G 1.154 0.983 1.07 6 640: 100% ━━━━━━━━━━━━ 36/36 1.2it/s 29.2s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 5/5 1.1it/s 4.6s
all 71 100 0.981 0.98 0.994 0.669
(略)
Ultralytics 8.4.24 🚀 Python-3.14.3 torch-2.10.0 CPU (Apple M5)
Model summary (fused): 73 layers, 3,005,843 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 5/5 1.1it/s 4.4s
all 71 100 0.981 0.98 0.994 0.669
Speed: 0.1ms preprocess, 59.1ms inference, 0.0ms loss, 0.5ms
323.411288022995sec.GPUで学習した結果です。
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 2.25G 1.453 2.696 1.207 5 640: 100% ━━━━━━━━━━━━ 36/36 2.8it/s 12.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 5/5 2.1it/s 2.4s
all 71 100 0.00455 0.97 0.0502 0.0313
(略)
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 2.24G 1.161 0.9894 1.076 6 640: 100% ━━━━━━━━━━━━ 36/36 3.0it/s 11.8s
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 5/5 1.2s/it 6.1s
all 71 100 0.989 0.97 0.994 0.676
10 epochs completed in 0.041 hours.
Optimizer stripped from
(略)
Ultralytics 8.4.24 🚀 Python-3.14.3 torch-2.10.0 MPS (Apple M5)
Model summary (fused): 73 layers, 3,005,843 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100% ━━━━━━━━━━━━ 5/5 1.2s/it 6.0s
all 71 100 0.989 0.97 0.994 0.676
Speed: 0.1ms preprocess, 13.6ms inference, 0.0ms loss, 43.3ms
165.20838022232056sec.CPUでの学習はM1, M2と比較してかなり向上しています。これは、UltralyticsのYOLOv8のライブラリの向上も貢献していそうです。
| 学習処理の時間 | |
| MacBook Air(M5) | 323.41秒 |
| MacBook Pro(M4Max) | 269.27秒 |
| MacBook Air(M2) | 630.54秒 |
| MacBook Pro(M1Pro) | 582.68秒 |
KaggleのGPU(P100)と比較すると、まだ速度的に遅いですが十分な速度で実行できています。特に、M1, M2からのステップアップがすごいです。
| 学習処理の時間 | |
| MacBook Air(M5) | 165.21秒 |
| MacBook Pro(M4Max) | 135.65秒 |
| MacBook Air(M2) | 334.40秒 |
| MacBook Pro(M1Pro) | 372.99秒 |
| 参考:GPU=P100(kaggle notebook) | 119秒 |
注意:手元にあるMacBook M4はYOLOv8をアップデートして測定しなおしましたが、M2とM1Proは手放したので以前の計測結果です。
LM Studioでのベンチマークの詳細は以下の記事を参考にしてください。

M2と比較して格段に速度が向上しました。特にgpt-oss-20bで40トークン/秒前後の速度です。個人的には20トークン/秒を超えると我慢できるレベルですが、40を超えると結構快適です。
以下の動画はgpt-oss-20bをMacBook Air(M5)で動かした時のものです。速度感がわかるかと思います。
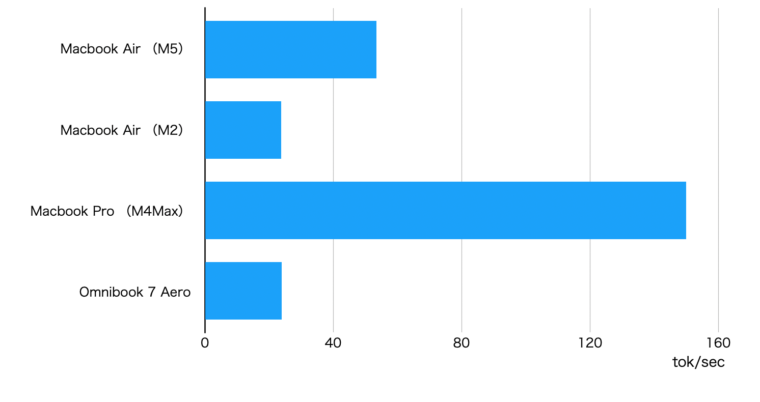
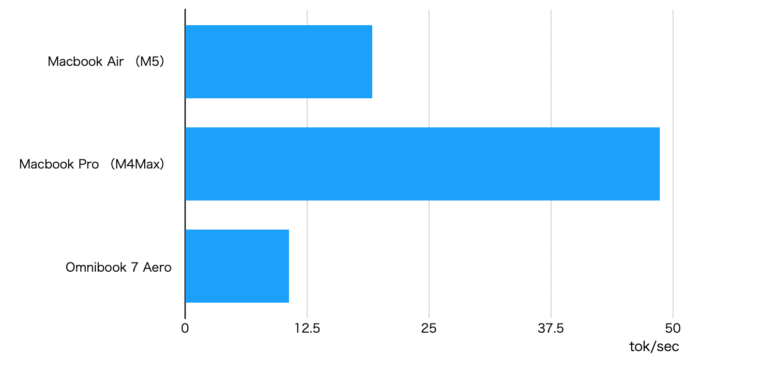
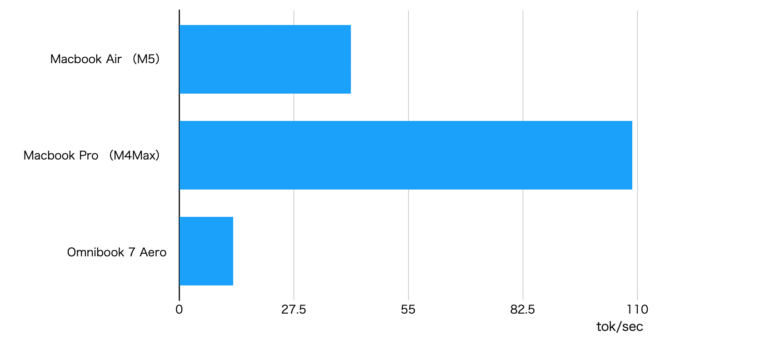

M5搭載のMacBook Airのディープラーニング性能を評価してみました。今回感じたのは「これくらいの性能があればちょっと学習させる」程度であれば十分使えそうということです。
ガッツリ学習させる場合は、Google Colabなどで、A100などを使った方がよいとは思いますが、ちょっとした物体認識、物体検出程度であれば十分な速度で学習できると思います。
また、ローカルLLMについては、持ち運びできるノートパソコンで普通に動かせる時代になったなーと感じています。特にgpt-oss-20bやQwen3.5-9Bはローカルといってもそこそこ賢く実用上問題ないレベルです。