
XORで学ぶ多層ニューラルネットワークの学習と推論【初級 深層学習講座】
Aru
Aru's テクログ(Aruaru0)

Audiomentationsは、音声やオーディオデータ向けの強力なデータ拡張(data augmentation)ライブラリです。このライブラリって音声データのデータオーグメンテーションを行うことで、モデルのパフォーマンス(精度やロバスト性)を向上させることができます。この記事では、Audiomentationsの使い方と、いくつかの機能について詳しく解説します。
Audiomentationsは、オーディオデータ向けのデータ拡張ライブラリです。公式の解説に「画像向けデータ拡張ライブラリ”Albumentations”に影響を受けて開発した」と書かれていますが、名前も使い方もAlbumentationsによく似ています。
この記事では、Audiomentationsの使い方と機能について解説します。オーディオ・音声データに対するデータ拡張を考えている方は参考にしてください。
Github: https://github.com/iver56/audiomentations
document: https://iver56.github.io/audiomentations/

データ拡張(Data Augmentation)は、訓練データセット内のサンプル数を増やすために、元のデータを変換・変更する手法です。
データ拡張の主要な目的は、モデルの汎化能力を向上させ、過学習を防ぎ、新しいデータに対する性能を向上させることです。これにより、訓練データが限られている場合でも、より強力なモデルを構築できます。
Autimentationsのインストールは簡単です。
コマンドラインでpipコマンドを実行するだけでインストールできます。
pip install audiomentationsなお、Google Colabではセルに以下のコードを書いて実行します(notebookの場合は頭に!をつけてコマンドを実行します)
!pip install audiomentations以下は、基本的な使い方です。
まず、ライブラリをインポートします。
音声データの読み込みにlibrosaを利用したいと思いますので、librosaも一緒にインポートしておきます。

今回は、結果をグラフにして確認しますので、matplotlibとnumpyもインポートしています。
import matplotlib.pyplot as plt
import numpy as np
import audiomentations as A
import librosa波形や結果を表示するための関数群も用意しておきます。plot_wavesは波形を表示する関数、plot_spectrumは周波数スペクトルを表示する関数になります。
def plot_waves(org, argumented):
# orgとargumentedの波形を表示する
range = np.max([np.max(np.abs(org)), np.max(np.abs(argumented))])
ave = np.mean(np.concatenate([org, argumented]))
up, dn = ave + range, ave - range
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(org)
plt.ylim(dn, up)
plt.title('Original Waveform')
plt.subplot(1, 2, 2)
plt.plot(argumented)
plt.ylim(dn, up)
plt.title('Augmented Waveform')
plt.show()
def plot_spectrum(s):
f = np.fft.rfftfreq(len(s))
plt.loglog(f, np.abs(np.fft.rfft(s)))[0]
plt.show()Compose:複数のデータ拡張を順番に呼び出すAudiomentationsでは、「データ拡張Aの次にデータ拡張Bを実行する」といったように、複数のデータ拡張を組みあせて使うことが多いです。
複数のデータ拡張を順番に実行する場合は、以下のようにComposeを利用します。
以下の例では、AddGaussianNoise、TimeStretch、PitchShiftを連続で呼び出しています。また、p=0.5にしていますので、それぞれの処理が行われる確率は1/2になります。
transform = A.Compose([
A.AddGaussianNoise(min_amplitude=0.001, max_amplitude=0.015, p=0.5),
A.TimeStretch(min_rate=0.8, max_rate=1.25, p=0.5),
A.PitchShift(min_semitones=-4, max_semitones=4, p=0.5),
])
wave, sr = librosa.load('test.wav')
augmented_wave = transform(wave, sample_rate=sr)
plot_waves(wave, augmented_wave)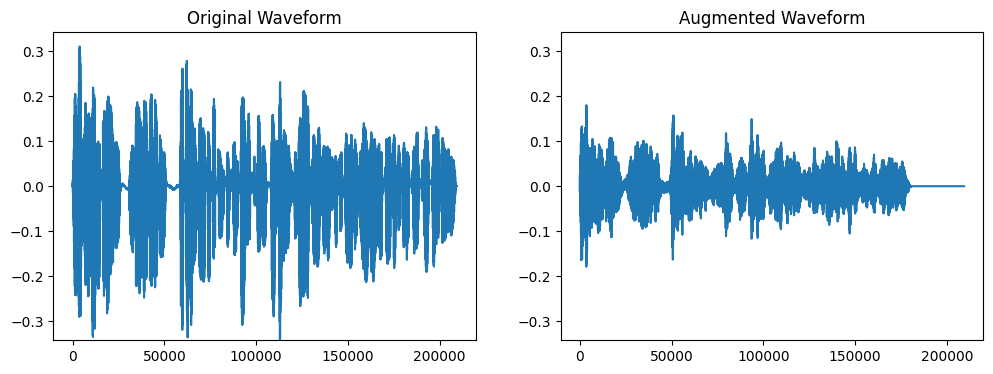
OneOf:リストに列挙された1つを処理するリストに列挙された処理の1つを選択して処理します。複数の処理のうち、1つを選んで処理したい場合に利用します。
Compose, OneOfは、Albumentationsと使い方はほぼ同じです。
ここでは、Audiomentationsが用意している変換のうち、よく利用する機能について紹介します。ここで紹介した以外にも、audiomentationsではたくさんの変換が用意されています。たのデータ拡張について知りたい場合はドキュメントをチェックしてください。
音声処理をある程度知らないと、データ拡張が何を行うかわかりにくいものもあります。音声の処理についてある程度理解しておく必要があります。
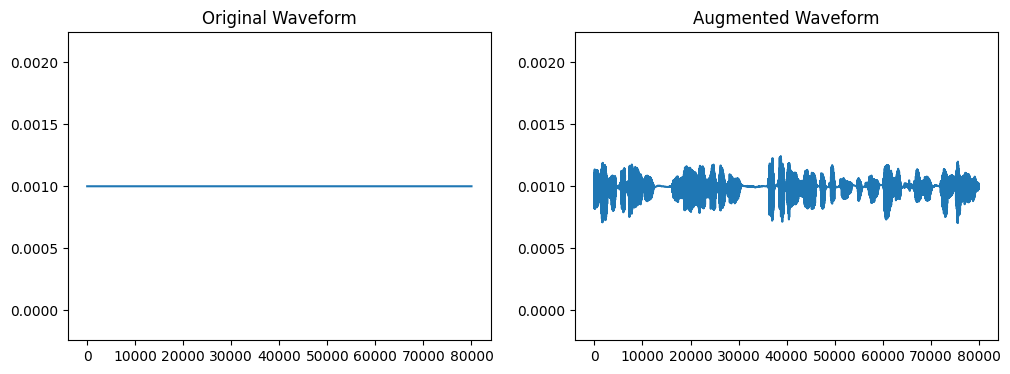
背景ノイズを追加します。この機能では、あらかじめ背景ノイズの音源を用意しておく必要があります。
transform = A.AddBackgroundNoise(sounds_path='sounds', p=1.0)
sr = 16000
wave = np.zeros(sr*5) + 0.001
augmented_wave = transform(wave, sample_rate=sr)
plot_waves(wave, augmented_wave)無音データに、背景音を加えた例です。
sound_path | 背景の音源データへのパス、または、ファイルリスト |
min_snr_db | 最小のsignal to noise ratioをdBで設定 |
max_snr_db | 最大のsignal to noise ratioをdBで設定 |
色ノイズを加えます。
min_f_decay | オクターブあたりの最小ノイズ減衰 (dB) |
max_f_decay | オクターブあたりの最大ノイズ減衰 (dB) |
min_snr_db | 最小のsignal to noise ratioをdBで設定 |
| 最大のsignal to noise ratioをdBで設定 |
色ノイズの場合、min_f_decay, max_f_decayに以下の値をあ設定します。
| Colour | f_decay (dB/octave) |
|---|---|
| pink | -3.01 |
| brown/brownian | -6.02 |
| red | -6.02 |
| blue | 3.01 |
| azure | 3.01 |
| violet | 6.02 |
| white | 0.0 |
このうち、よく使うカラーノイズはホワイトノイズとピンクノイズあたりだと思います。ここでは、この2つについてコード例を示しておきます。
ピンクノイズ・ホワイトノイズだけを使いたい場合は、こちらも参考になります

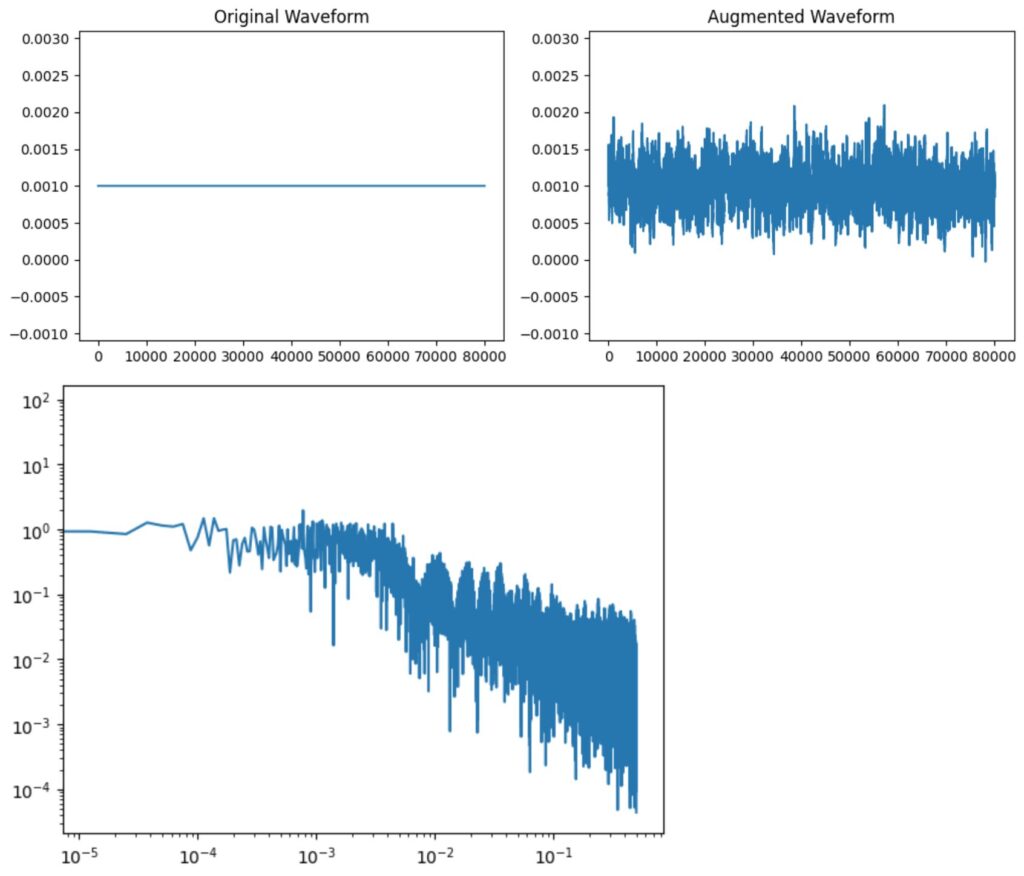
f_decayに-3.01を設定してピンクノイズを加えてみます。
transform = A.AddColorNoise(p=1.0, min_snr_db=10, max_snr_db=40,
min_f_decay=-3.01, max_f_decay=-3.01)
sr = 16000
wave = np.zeros(sr*5) + 0.001
augmented_wave = transform(wave, sample_rate=sr)
plot_waves(wave, augmented_wave)
plot_spectrum(augmented_wave)スペクトルをみると、ピンクノイズになってそうです。
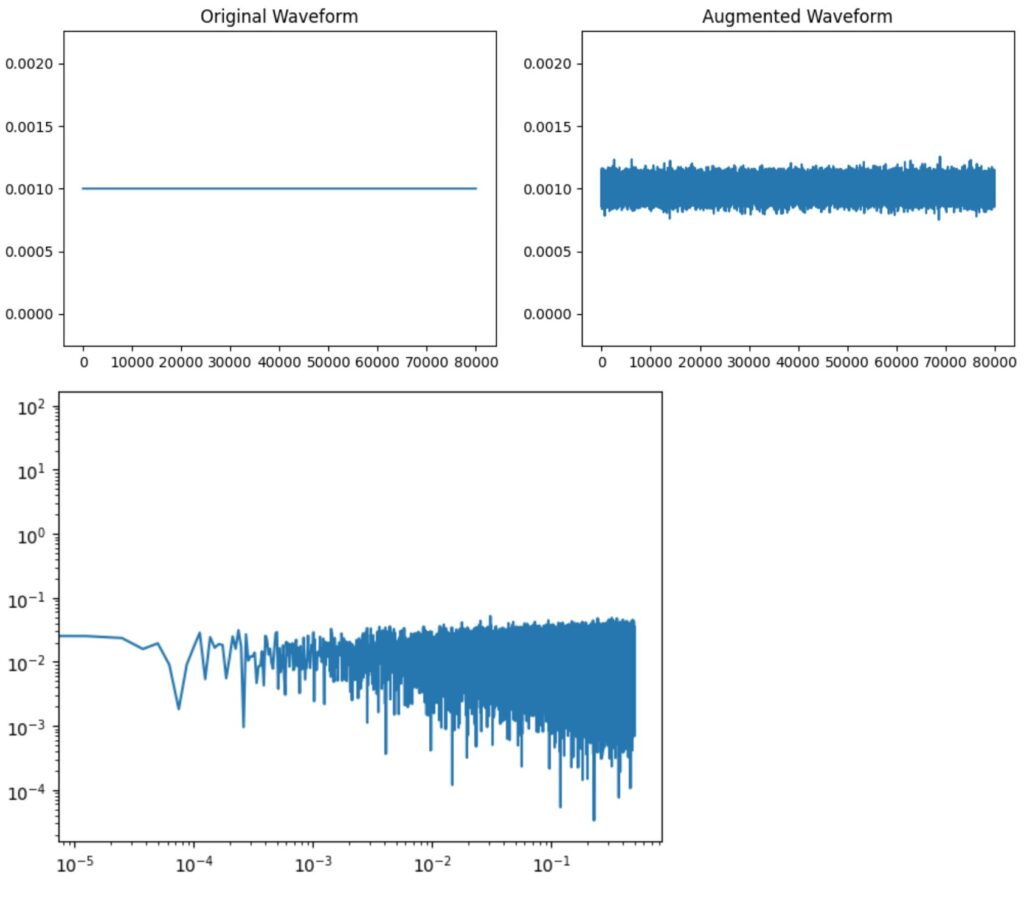
ホワイトノイズを加えています。
transform = A.AddColorNoise(p=1.0, min_snr_db=10, max_snr_db=40,
min_f_decay=0, max_f_decay=0)
sr = 16000
wave = np.zeros(sr*5) + 0.001
augmented_wave = transform(wave, sample_rate=sr)
plot_waves(wave, augmented_wave)
plot_spectrum(augmented_wave)減衰率が一定で、正しくホワイトノイズが加えられています。
ガウスノイズを加えます。
transform = A.AddGaussianNoise(min_amplitude=0.001, max_amplitude=0.015, p=1.0)
sr = 16000
wave = np.zeros(sr*5) + 0.001
augmented_wave = transform(wave, sample_rate=sr)
plot_waves(wave, augmented_wave)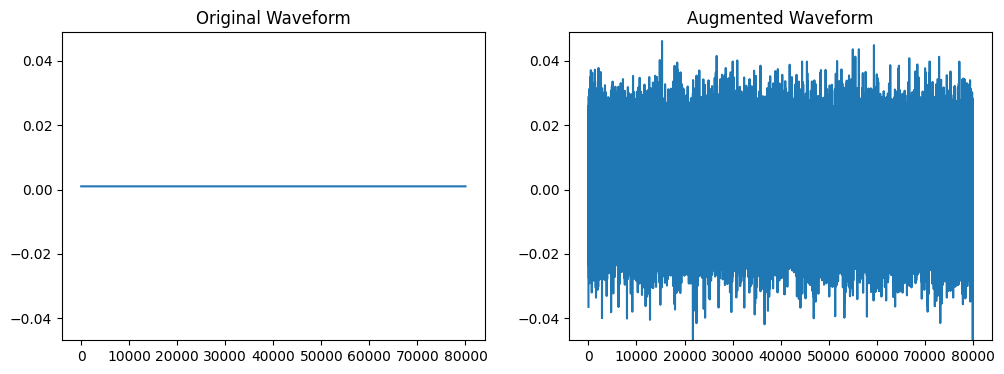
min_amplitude | 最小ノイズ増幅率 |
max_amplitude | 最大ノイズ増幅率 |
ガウスノイズを加える関数ですが、こちらは、SNRでパラメータを設定します。
SNRなので数値が大きいほどノイズが少ない(音質が良い)点に注意します。
transform = A.AddGaussianSNR(p = 1.0, min_snr_db=5, max_snr_db=40)
wave, sr = librosa.load('test.wav')
augmented_wave = transform(wave, sample_rate=sr)
plot_waves(wave, augmented_wave)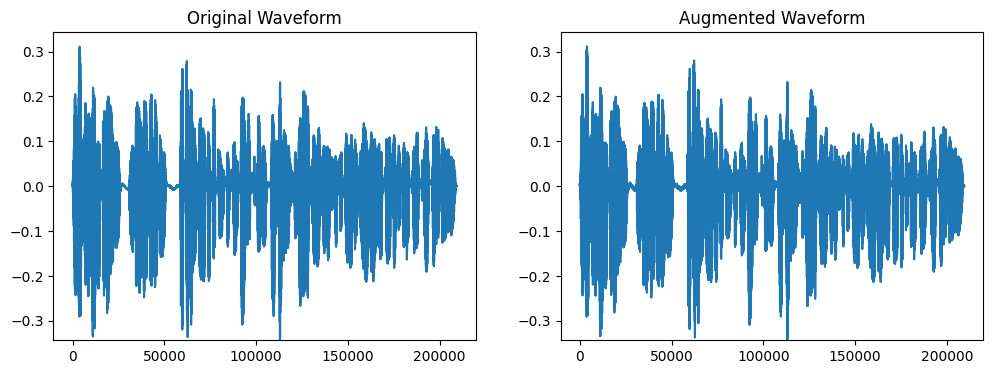
min_snr_db | 最小信号対雑音比 (dB)。数値が小さいほどノイズが多くなります |
max_snr_db | 最大信号対雑音比 (dB)。数値が小さいほどノイズが多くなります |
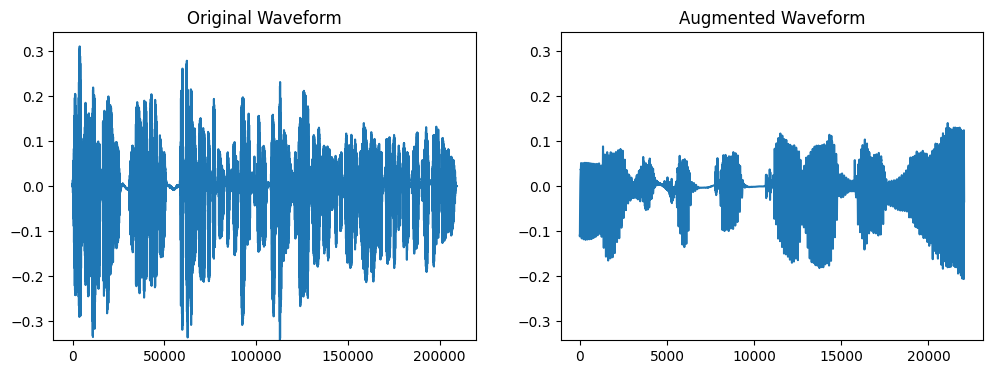
秒数を調整します。音声データが長すぎる・短すぎる場合に、一定の秒数にしたい場合に利用します。
wave, sr = librosa.load('test.wav')
transform = A.AdjustDuration(duration_samples=sr, p=1.0)
augmented_wave = transform(wave, sample_rate=sr)
plot_waves(wave, augmented_wave)duration_samplesに合わせて、長さが調整されます。長い場合はランダムな位置をクロップし、短い場合はパディングが行われます。
音量を調整します。
transform = A.Gain(p = 1.0, min_gain_db=-12, max_gain_db=12)
wave, sr = librosa.load('test.wav')
augmented_wave = transform(wave, sample_rate=sr)
plot_waves(wave, augmented_wave)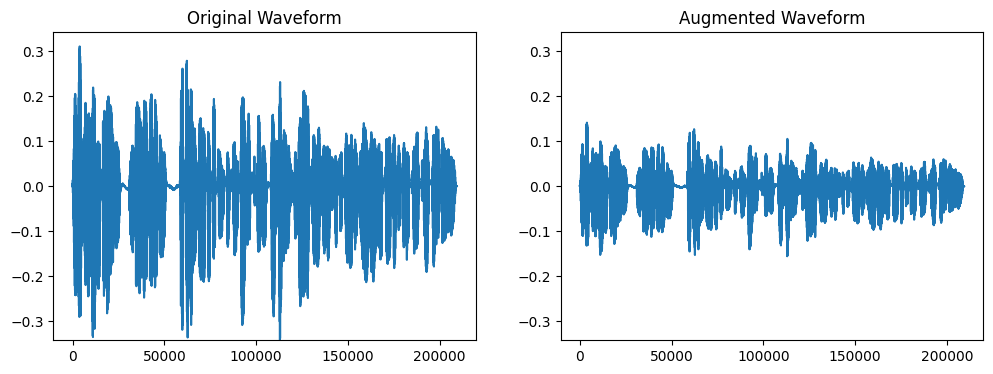
min_gain_db | 最小ゲイン (dB) |
max_gain_db | 最大ゲイン (dB) |
以上、オーディオデータ用のデータ拡張ライブラリ”Audiomentations”について紹介しました。音声データに対するディープラーニングもたまに行うので、データ拡張ライブラリには重宝しています。





