
textstat文章の読みやすさを数値化し、機械学習の特徴量として活用する方法
Aru
Aru's テクログ(Aruaru0)

1次元の音声データも、スペクトログラムに変換することで2次元の画像データとして扱うことができます。この記事では、音声データをメルスペクトログラム(Mel Spectrogram)に変換し、2次元データとして取り扱う方法について、PyTorchのDatasetクラスの実装を例に解説します。音声信号の可視化や、画像処理技術を用いた音声データのディープニューラルネットワーク(DNN)での学習に興味がある方は参考にしてください。
音声データをディープラーニングで扱う場合、1次元のデータをそのまま扱う方法と、スペクトログラムに変換して扱う方法の2種類があります。
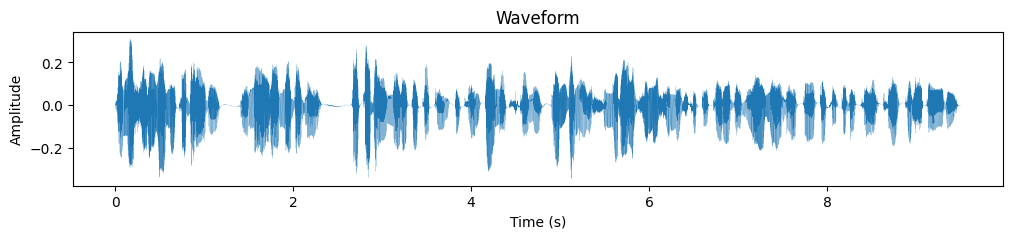
スペクトログラムに変換した場合、データは2次元のデータとなるので「画像として」扱うことが可能になります。
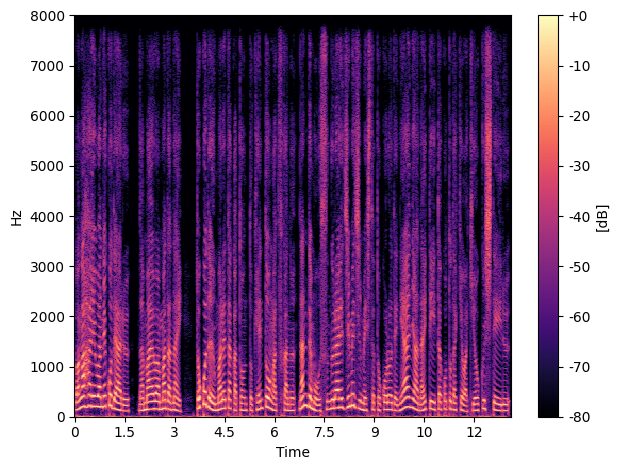
画像データとして扱えれば、画像用に用意されている多数の深層学習のモデルで取り扱うことが可能になります。例えば、画像向けのefficientnetなどで、音声データの分類・識別を行うことができます。
このように、スペクトログラムは画像データとして扱うことができるため、畳み込みニューラルネットワーク (CNN) などの画像処理に適したモデルを直接適用することができます。これにより、音声データの処理において画像向けに用意された様々なアーキテクチャを利用することができるよになります。
ここでは、音声データをメルスペクトログラムに変換するための手順について解説します。
librosaは音声解析および音楽情報処理のためのライブラリです。まずは、こちらのライブラリを使った方法を解説します。
音声データはloadで読み込むことができます。データ列yとサンプリングレートsrが戻り値になります。
import librosa
y, sr = librosa.load('test.wav')
print(f"Sampling rate = {sr/1000} khz, {len(y)/sr : .3f} sec.")
# Sampling rate = 22.05 khz, 9.497 sec.
メルスペクトログラムへの変換は、librosa.feature.melspectrogram関数を呼び出すだけでokです。メルスペクトログラムを作る場合には、いくつかのオプションを指定する必要があります。ここでは、hop_length=512, fmax=sr/2と指定しています。
D = librosa.feature.melspectrogram(y=y, sr=sr, hop_length=512, fmax=sr/2)
# 振幅をデシベルに変換(基準値は「振幅の最大値」)
amp_db = librosa.amplitude_to_db(D, ref=np.max)
# plot
librosa.display.specshow(amp_db,
sr=sr,
hop_length=512,
y_axis='mel',
x_axis='time')
plt.colorbar(format='%+2.0f').set_label('[dB]')
plt.tight_layout()
plt.show()
作成されたグラフは以下のようになります。横軸が時間、縦軸が周波数です。音声データなので、発話していない時間は黒くなっていることがわかります。
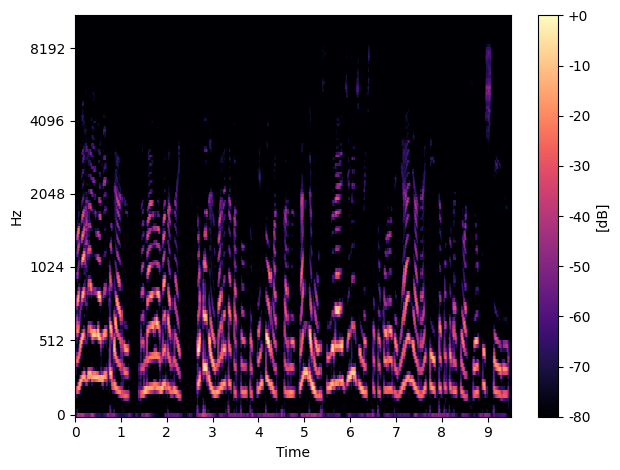
先ほどは9秒のデータ全体をメルスペクトログラムに変換しましたが、DNNに入力する場合は、一定秒数の区間に分割して入力します。ここでは、2秒(sr*2)で区切ってメルスペクトログラムを作成しています。
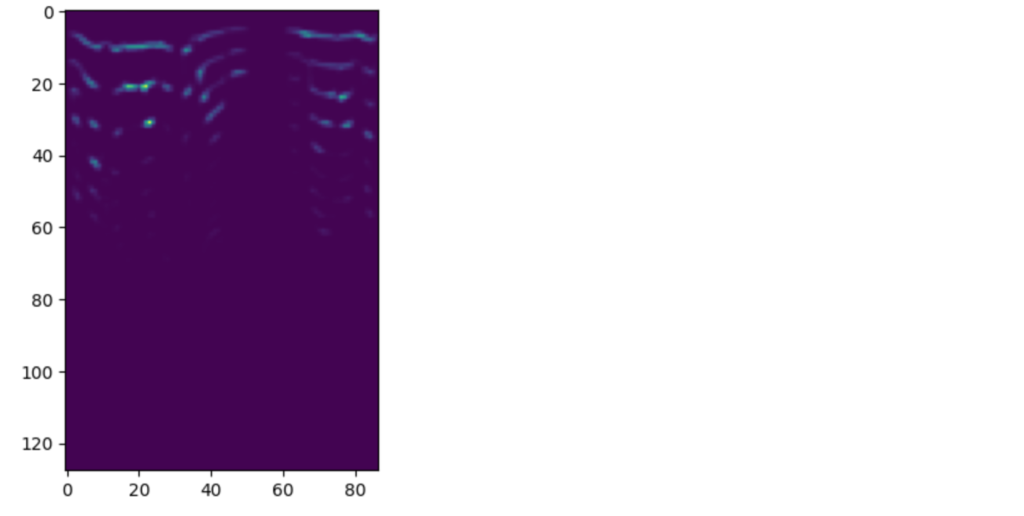
作成したメルスペクトログラムはmel_specに格納されています。
サイズは127×87です。87は、2秒間のデータ(22,050hz × 2秒 ÷ 512(hop_length)≒87)の長さです。縦はフィルタバンクの数でパラメータにより指定することも可能です。
y2sec = y[:sr*2]
mel_spec = librosa.feature.melspectrogram(y=y2sec, sr=sr, hop_length=512, fmax=sr/2)
plt.imshow(mel_spec)
mel_spec.max(), mel_spec.min(), mel_spec.shape
# (129.00424, 1.4995278e-09, (128, 87))上記の変換で以下のような2次元データを得ることができます。
librosaではなく、torchaudioを使ってメルスペクトログラムに変換することも可能です。
torhaudio.loadを使って音声データを読み込むことも可能ですが、ここでは、librosa.loadを使って読み込みを行なっています。
torchaudioの場合は、torchaudio.transforms.MelSpectrogramで変換のためのオブジェクトを作成し、それを使って変換をするというステップになります。
import torchaudio
import librosa
y, sr = librosa.load('test.wav')
print(f"Sampling rate = {sr/1000} khz, {len(y)/sr : .3f} sec.")
y2sec = y[:sr*2]
transform = torchaudio.transforms.MelSpectrogram(sample_rate=sr, hop_length=512, f_max=sr/2)
mel_spec = transform(torch.tensor(y2sec))
mel_spec.max(), mel_spec.min(). mel_spec.shape
# (tensor(112.4667), tensor(0.), torch.Size([128, 87]))作成したメルスペクトログラムです。librosaと若干異なりますが、デフォルトパラメータの差などが大きいと思います。サイズは128×87です。

ここでは、音声データ(波形データ)を読み込んで、2次元データを返すPyTorchのデータセットを実装してみます。
なお、このプログラムでは、データがdata/ラベル名/xxx.wavという形で格納されているとします。
この場合、音声データを読み込んでメルスペクトログラムに変換して出力するデータセットの定義の例は以下のようになります。
import glob
import torch, torchvision
import librosa
import random
class AudioDataset(torch.utils.data.Dataset) :
def __init__(self, path, mode, sr=16000, hop_length=512, sec=2) :
self.files = glob.glob(os.path.join(path,"*/*"))
self.mel = torchaudio.transforms.MelSpectrogram(sample_rate=sr, hop_length=512, f_max=sr/2)
self.sr = sr
self.hop_lenght = hop_length
self.sec = sec
# データ拡張用の変換列などを定義しておく
if mode == "train" :
self.mode = 1
else:
self.mode = 0
def __len__(self) :
return len(self.files)
def __getitem__(self, idx) :
filename = self.files[idx]
y, sr = librosa.load(filename, sr=self.sr)
if self.mode == 1 :
start = random.randint(0, len(y)-self.sr*self.sec)
else: start = 0
y_sel = y[start:start+self.sr*self.sec]
label = None
if self.mode == 1 :
# ここで、ノイズ付加などのデータ拡張を行う
label = filename.split("/")[-2]
mel_spec = transform(torch.tensor(y_sel))
return mel_spec, labelこのコードでは、wavファイルを読み込んでsecで指定された秒数を切り出してメルスペクトログラムへ変換しています。切り出す位置は、訓練の場合はランダムに決めています。
このようなコードが音声データ向けのデータセットの基本構造になるかと思います。
音声データをメルスペクトログラムに変換する処理は、意外と処理時間が必要です。学習時に変換を行うと処理時間がかかるので、先に画像データに変換するアプローチを取ることもあります。どちらが良いかは、状況によります。


データが指定された秒数に足りない場合のエラーチェックを行っていませんので、必要があればエラーチェックが必要です。
音声データを2次元データに変換すれば、画像用のDNNを用いて学習することが可能になります。深層学習(ディープラーニング)では音声をスペクトログラムに変換して処理するというのは一般的ですので、音声データをメルスペクトログラムに変換する手順を理解していると役に立ちます。




