
MacBook M4Max LLMベンチマーク結果を公開
Aru
Aru's テクログ(Aruaru0)

Category Encodersは、カテゴリ変数を数値や他の形式に変換するための高機能なツールです。カテゴリ変数は、通常はOne-hotエンコーディングやOrdinalエンコードを行いますが、これを簡単に行うツールがCategory Encodersです。この記事では、Pandasデータフレームのカテゴリ変数列をcategory_encodersを使って変換する方法を解説します。
カテゴリ変数を数値等のデータに変換する処理コードは、テンプレート的なコードですが、毎回記述するのは面倒です。これを簡単にするのがcategory_encodersです。この記事では、カテゴリ変数の変換を効率よく行えるcategory_encodersについて紹介します。
カテゴリ変数とは、年齢(男・女)や、国名(日本、米国)などのようにカテゴリを表現する変数です。カテゴリ変数は、文字や数字で表現されることが多いです。文字の場合、機械学習や深層学習で扱うためには数値にエンコードする必要があります。また、例えば血液型の場合A型を0、B型を1、O型を2, AB型を3と数値で表現したとします。この場合、0→1→2→3の並びは意味を持たないラベルであり、例えば0.5といった数値は意味を持ちません。このようなデータは数値をして扱うのは不適切です。
このように、カテゴリ変数は「意味合いを加味した変換」を行う必要があります。

lightGBMやCatboostは、カテゴリ変数の変換を自動でやってくれるので気にしていない人も多いと思います

私は、モデルのチューニングを行う際に、一部を明示的に数値表現に変換することが多いです
scikit-learnにもプリプロセスとしてカテゴリ変数の変換機能があるので、「別のライブラリをわざわざ使う必要があるの?」と疑問に思う方も多いと思います。
以下, scikit-learnを使って、カテゴリ変数をOne-hotエンコードする例です。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoder.fit(df[["category"]])
encoded_category = encoder.transform(df[["category"]])
print(encoded_category)
# [[0. 0. 0. 0. 0. 1. 0. 0.]
# [0. 1. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 1. 0. 0.]
# [0. 0. 0. 0. 0. 1. 0. 0.]
# [1. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 1. 0. 0. 0. 0. 0.]
# [1. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 1. 0.]
# [0. 0. 1. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 1. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 1.]
# :
# :上記の例のように、変換した結果はnumpyの配列として出力されます。これを、pandasのデータフレームに追加する場合は、以下のようなコードになります。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoder.fit(df[["category"]])
encoded_category = encoder.transform(df[["category"]])
df_tmp = pd.DataFrame(encoded_category, columns=encoder.categories_)
df_merge = pd.concat([df, df_tmp], axis=1)df_mergeに以下のようにエンコードした結果を追加できますが少し面倒です。
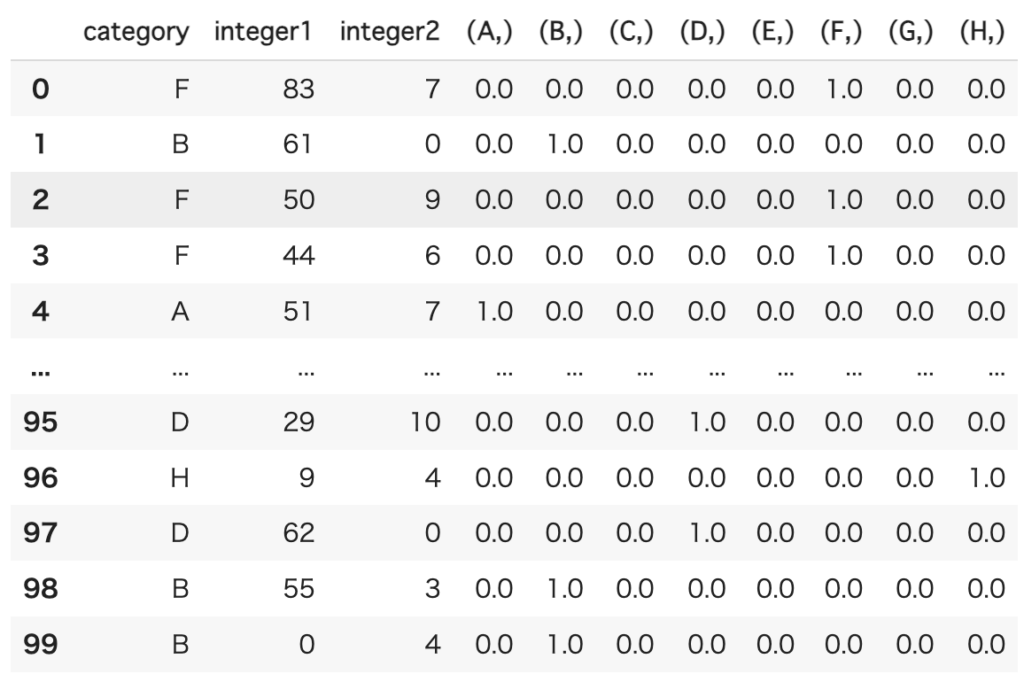
category_encodersを使えば、以下のように記述すれば変換後のデータフレームを出力してくれます。Pandasのデータフレームに処理を行う場合は、こちらの方がはるかに簡単です。
encoder = ce.OneHotEncoder(['category'])
df_onehot = encoder.fit_transform(df)また、エンコード方法も色々用意されています。
とりあえず、簡単に書きたいという場合におすすめです!
インストールは、pipで行うことが可能です。
pip install category_encodersこの記事で必要なライブラリのインポートは以下の通りです。
import sklearn.datasets as datasets
import pandas as pd
import random
import category_encoders as ceこの記事では、以下の方法でデータセットを作成しています。
dfがデータセットで、yが正解ラベル(0,1,2)の3種になります。
yはターゲットエンコーダーの説明で利用します。
n = 100
category = [['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'][random.randint(0,7)] for _ in range(n)]
integer1 = [random.randint(0,100) for _ in range(n)]
integer2 = [random.randint(0,10) for _ in range(n)]
y = [random.randint(0,2) for _ in range(n)]
data = {
'category': category,
'integer1': integer1,
'integer2': integer2
}
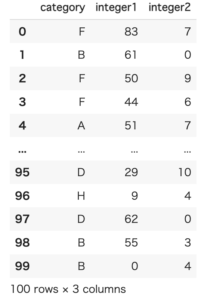
df = pd.DataFrame(data)実行すると、以下のような100行のデータを作ります。
お馴染みの変換です。カテゴリの数だけ列を作り、該当する列を1に、それ以外を0にする変換です。[‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’]の8つのcategoryがcategory_1~8に変換されます。
encoder = ce.OneHotEncoder(['category'])
df_onehot = encoder.fit_transform(df)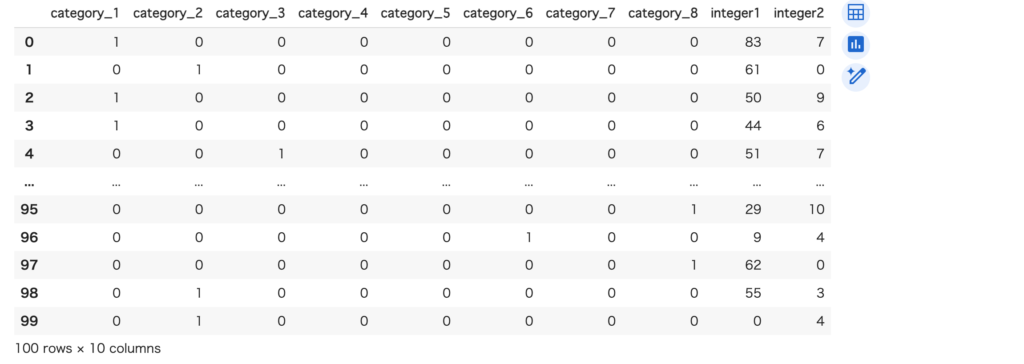
なお、他のデータに同じ変換を行いたい場合には、encoder.transorm(df)を実行します。
カテゴリを2進数に変換します。[‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’]の8つのcategoryは、4ビットで表現できるので4つの列に変換されます。
encoder = ce.BinaryEncoder(['category'])
new_df = encoder.fit_transform(df)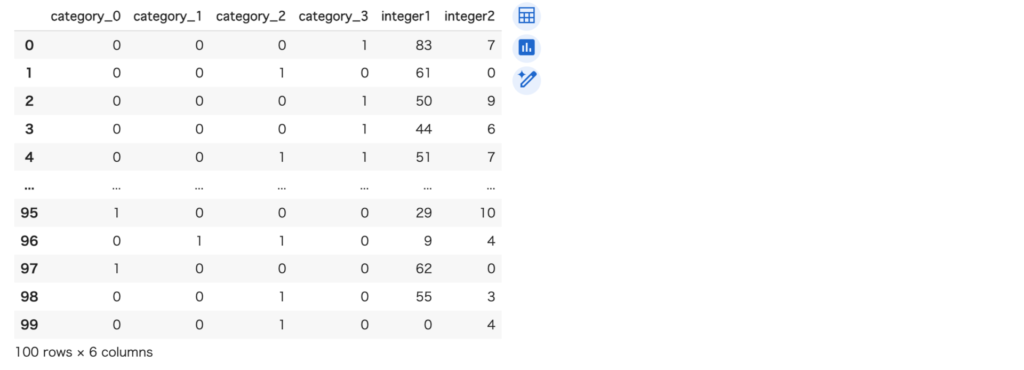
カテゴリをnビットで表現します。base=3の場合は、3進数になります。8つのカテゴリは、2桁の3進数で表現できるので、2列で表現されます。
encoder = ce.BaseNEncoder(['category'], base=3)
new_df = encoder.fit_transform(df)
カテゴリを数値に直すものです。A~Hまでのアルファベットにそれぞれ数値が割り当てられます。注意点は、出現順に割り当てられることです。最初の行のカテゴリ変数の値がFなので、Fに1が割り当てられています。
encoder = ce.OrdinalEncoder(['category'])
new_df = encoder.fit_transform(df)
各カテゴリに割り当てる値を指定する場合は、以下のようにします。
map = {e:i for i, e in enumerate(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'])}
encoder = ce.OrdinalEncoder(['category'],mapping=[{'col':'category', 'mapping': map}])
new_df = encoder.fit_transform(df)mappingの書き方は少し面倒ですが、指定するcolとマッピング方法mappingの辞書(複数可)をリストとして渡します。
ターゲットエンコーディングは、目的変数を使ってカテゴリ変数を変換する手法です。
目的変数を使うため、リークが発生する可能性があります。使う場合は注意が必要です。
リークとは、目的変数の情報が「漏れる」ことです。エンコードに目的変数を利用しているので、目的変数の情報が説明変数側にリークする可能性があるわけです。
encoder = ce.TargetEncoder(['category'])
y = [random.randint(0,2) for _ in range(n)]
new_df = encoder.fit_transform(df, y)
目的変数を利用するエンコーダーで変換した場合、transformメソッドを呼び出す場合には、目的変数を設定する必要はありません。
new_df = encoder.transform(df)推論したいデータは、目的変数(結果)はわかっていないので、fitで計算した値を使うことになります。
TargetEncoderと似ていますが、自身の目的変数の値を含めないようにする変換です。
encoder = ce.LeaveOneOutEncoder(['category'])
new_df = encoder.fit_transform(df, y)
以下のように、fit後にtransformすると結果が変化することに注意が必要です(TargetEncodeと挙動が近くなります)
encoder = ce.LeaveOneOutEncoder(['category'])
encoder.fit(df, y)
new_df = encoder.transform(df)
new_df
使ったことはない変換ですが気になるものをピックアップしました。あまり詳しくないので紹介だけになります。
CatBoostの内部の変換に似た変換を行うものです。
encoder = ce.CatBoostEncoder(['category'])
new_df = encoder.fit_transform(df, y)
new_df
James Stein推定量を使うもの?
encoder = ce.JamesSteinEncoder(['category'])
new_df = encoder.fit_transform(df, y)
new_df
mの値で調整することが可能です。ドキュメントには、ターゲットエンコーダーをシンプルにしたものとという記載があります。
This is a simplified version of target encoder, which goes under names like m-probability estimate or additive smoothing with known incidence rates.
encoder = ce.MEstimateEncoder(['category'])
new_df = encoder.fit_transform(df, y)
new_df
category_encodersは、他にもいくつか変換が用意されています。といっても、One-hot, Binary, Ordinal, Targetエンコーダーあたりを一番使う気がします。



