
LLM(大規模言語モデル)の仕組みを分かりやすく解説|推論処理を理解しよう
Aru
Aru's テクログ(Aruaru0)

この記事では、CNNの畳み込み層のカーネルを可視化してみます。CNNのカーネルは画像処理で言えばエッジ抽出などのフィルタ処理などに相当する係数であると考えられます。ここでは、実際にカーネルを可視化して、どのようなフィルタが施されているのかをみてみます。
画像処理を行う深層学習(ディープラーニング)モデルでは、Convolutional Neural Networks(CNN)が広く利用されています。CNNの中核となるのが「畳み込み層」です。
畳み込み層は、文字通り「畳み込み」を行う層ですが、畳み込みは画像の特徴を抽出するための重要な役割を果たしています。例えば、畳み込み層は、エッジや模様、さらに高度な画像中の特徴量を抽出するのに役立ちます。
この記事では、CNNの畳み込み層の「カーネル」と呼ばれる係数について解説します。カーネルは画像処理でいうフィルタのような役割を担うもので、入力されたデータの狭い領域に対して特定の変換を行う係数が集まった行列です。
この記事では、カーネルがどのような係数になっているかを確認する方法について解説し、畳み込み層の動きを直感的に理解していきます。
畳み込み層は、入力データ(画像など)の局所的な特徴を捉えることを目的とした層です。畳み込み層では、カーネルと呼ばれる3×3や5×5といった小さなフィルタを入力データに適用し、畳み込み操作を行います。
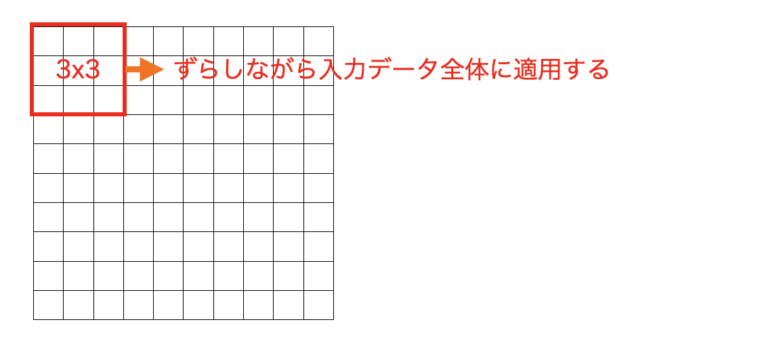
この結果、画像の重要なパターンや構造を捉えた特徴マップ(Feature Map)が生成されます。
上図のように、畳み込み層では、カーネルをスライドさせながら、画像の局所領域とカーネルの係数を掛け算して足し合わせる計算が行われます。これにより、エッジやコーナーなどの基本的な画像特徴量が抽出され、次の層で抽出した特徴量に対してさらに畳み込みを行うことにより、より広い範囲のより高度な特徴が計算されます。
実際には、畳み込み層ではカーネルの係数がのような特徴を取得するためのカーネルになるかは学習により決定します。
先ほどの図で示したように、カーネルは小さな行列で通常は3×3や5×5などの固定サイズです。jこれは、従来の画像処理ではフィルタ係数などと呼ばれたもに近いものです。
カーネルは、入力データに適用される際に、画像の一部に対して局所的な変換を行います。例えば、以下のような役割の係数が学習されることが知られています。
これらの役割は、カーネルに設定された係数の値によって決まります。
畳み込み層のカーネルを理解する上では、画像処理における典型的なフィルタについて知っていると役に立ちます。以下、典型的なフィルタについて少し解説します。
ラプラシアンフィルタは、画像の二次微分を計算することでエッジを強調するフィルタです。エッジだけでなく、画像中の急激な変化を検出するのに適しています。例えば、以下のような3×3カーネルが使われます:
$$
\begin{bmatrix} -1 & -1 & -1 \\ -1 & 8 & -1 \\ -1 & -1 & -1 \end{bmatrix}
$$
このカーネルを適用すると、エッジ部分が目立つ特徴マップが得られます。
ソーベルフィルタは、エッジの方向を検出するために使われます。例えば、水平エッジや垂直エッジを検出するカーネルとして以下のものが知られています:
$$
\begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix}
$$
$$\begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix}
$$
これらのカーネルを組み合わせることで、エッジの方向や強度を解析することができます。
CNNのカーネルは、これらのフィルタと似た動きを持ちますが、手動で設計する必要はありません。というのも、モデルが学習を通じて最適なカーネルを自動的に見つけ出すからです。
また、畳み込み層を多層で構成することで、入力に近い部分ではエッジなどの画像の基本パターンを、後の層では顔のパーツやオブジェクト全体の形状といった複雑な特徴を捉えるように学習することが知られています。
まとめると、畳み込み層のカーネルは、「画像の特定のパターンを捉えるための検出器」だと考えることができます。
例えば、最初の畳み込み層ではエッジや角といった低次元の特徴が抽出されることが多く、後の層ではそれらの組み合わせから顔や物体といった高次元の特徴を学習します。
このカーネルの「検出器」としての振る舞いを理解するために、実際に学習済みのカーネルを可視化すると良いです。以降では、PyTorchのモデルの畳み込み層のカーネルを可視化する方法にすいて解説します。
ここでは、PyTorchのモデルで畳み込み層のカーネルを確認する方法について解説します。ここではtimm(Pytorch Image Models)の学習済みのresnet18dを利用して可視化方法について解説します。
timmの学習済みモデル(resnet18d)を読み込みます。読み込むするコードは以下になります。
import timm
model = timm.create_model('resnet18d', pretrained=True)
print(model)上記のコードではprint(model)として、モデルの構造を表示しています。結果は以下のようになります。
ResNet(
(conv1): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
:
(略)
:これを見ると先頭にconv1という畳み込み層があることがわかります。このうち畳み込みを実際に行っているのはConv2dになります。
Conv2dを見ていきます。この部分は下記のようになっています。引数は、手前から入力チャネル、出力チャネル、カーネルサイズ・・・となります。
Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
ここでは、3チャンネルの画像(カラー画像はRGBの3チャネル)を受け取って32チャネルを出力します。また、カーネルサイズは3×3です。
32チャンネル出力するということから、3×3のカーネルを32個持つことがわかります(実際には入力が3チャネルなので、3チャネルx3x3のカーネルになります)。
カーネルは以下のコードでアクセスすることが可能です。
import timm
model = timm.create_model('resnet18d', pretrained=True)
model.eval()
conv1_weights = model.conv1[0].weight.data
print(conv1_weights.shape)
# torch.Size([32, 3, 3, 3])conv1_weightsがカーネルになります。
[32,3,3,3]は手前から出力チャネル、入力チャネル、カーネルサイズ(高さ・幅)になります。
以降では、このフィルタ係数を可視化してみます。
可視化コードは以下のようになります。処理としては、出力チャネル毎に3chx3x3のカーネルを取り出し、チャネルをまとめてmatplotlibで表示しています。

3x3x3のフィルタを足し込んで3×3にして考えた方が良いか悩みましたが、とりあえず3ch(RGB)をまとめた形で可視化しました。
import timm
import matplotlib.pyplot as plt
# モデルの読み込み
model = timm.create_model('resnet18d', pretrained=True)
model.eval()
# 最初の畳み込み層のフィルタ
conv1_weights = model.conv1[0].weight.data
print(conv1_weights.shape) # (出力チャンネル数, 入力チャンネル数, フィルタ高さ, フィルタ幅)
num_filters = conv1_weights.shape[0]
fig, axes = plt.subplots(1, num_filters, figsize=(20, 6))
for i in range(num_filters) :
filter_img = conv1_weights[i].cpu().numpy().sum(axis=0)
axes[i].imshow(filter_img)
axes[i].axis('off')
plt.show()結果としては、以下のように32個のカーネルが可視化されます。

このうち特徴的なものとしては以下のものなどがあります。

このカーネルの形は、ラプラシアンフィルタによく似ています。次のような形は、直線の端点を捉えるカーネルなのかも知れません。
人間の設計したフィルタと異なるのは、「学習した結果」としてフィルタ係数が決まることです。人が設計した場合は、欲しい特徴がありそれを取得するフィルタを考えますが、畳み込み層では問題を解くのに適したフィルタを学習によって獲得します。
以上のようなコードで、カーネルを可視化できます。
import timm
import matplotlib.pyplot as plt
model = timm.create_model('resnet18d', pretrained=True)
model.eval()
conv1_weights = model.conv1[0].weight.data
print(conv1_weights.shape) # (出力チャンネル数, 入力チャンネル数, フィルタ高さ, フィルタ幅)
num_filters = conv1_weights.shape[0] # 表示するフィルタ数
fig, axes = plt.subplots(3, num_filters, figsize=(20, 6))
for ch in range(3) :
for i in range(num_filters):
filter_img = conv1_weights[i][ch].cpu().numpy()
print(i, filter_img)
axes[ch][i].imshow(filter_img)#, cmap='gray')
axes[ch][i].axis('off')
plt.show()
畳み込み層のカーネルを可視化する方法について解説しました。上記のように簡単に可視化することができるので試してみることでより理解が深まるかと思います。
なお、画像を入力した場合の中間層の結果(特量量)を取り出す方法については、以下の記事が参考になるかと思います。




