
大規模言語モデル(LLM)パラメータ「temperature, top_k, top_p」について【初級 深層学習講座】
Dropoutの仕組みと学習・推論時の動作の違いを理解する【初級 深層学習講座】

Aru
ドロップアウト(Dropout)は、ニューラルネットワークにおいて過学習を防ぐための代表的な手法です。本記事では、Dropoutの仕組みと、学習時・推論時の動作の切り替えについて、PyTorchを使って実際に動かしながら確認します。特に、推論時の動作が気になっていた方には読んでみてください。
Contents
ドロップアウト(Dropout)とは
ドロップアウト(Dropout)は、ニューラルネットワークにおける正則化手法の一つで、主に過学習を防ぐために使用されます。
ドロップアウトは、全結合層(fully connected layers, FC)や畳み込み層(convolutional layers, CNN)などのネットワーク層の接続間に挿入されることが一般的です
具体的には、ドロップアウトは入力データの一部をランダムに選んでゼロにし、その要素を無視する形で学習を進めます。これにより、入力の一部が毎回異なる場所でマスクされ、隠された状態で学習が行われることになります。
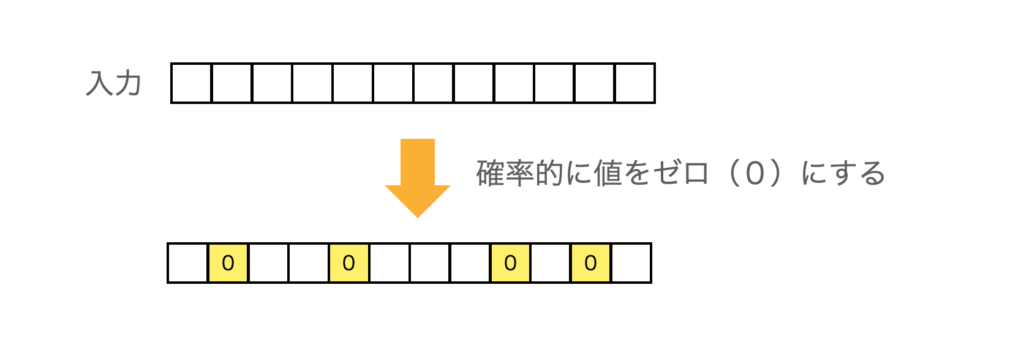
この方法によって、全てのデータを使って解くよりも難易度が高い問題設定となり、ネットワークはより汎化されたパターンを学習することが必要となります。
結果として、特定の入力データに依存度を減らした、より汎用的な特徴を捉えた学習が行われることになります。
簡単に言えば、ドロップアウトは、ネットワークが特定のパターン(入力データ)に特化した学習をしないようにするための工夫といえます。
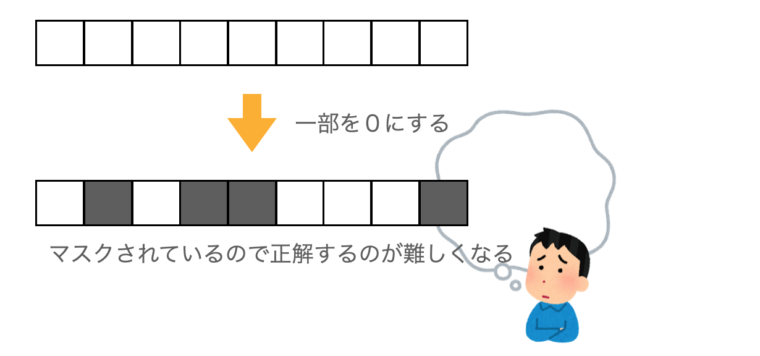

ある特定の入力要素が強く結果に依存している場合、ドロップアウトがなければそこだけみて推論するようになるかもしれません。

ドロップアウトで、そこが隠されれば他の要素を使って推論しようと試むでしょう
つまり、入力のいろいろな特徴を使って推論しようとする(=汎化しようとする)はずです。
PytorchのDropoutの動作
Dropoutの基本的な仕組みについて簡単に説明しましたが、理解できたでしょうか?
ここからは、実際にPyTorchを使用してDropoutの動作を確認していきます。
Pytorchのインポート
まず、Pytorchをインポートします。
import torch
from torch import nnDropoutのオブジェクトを生成する
次に、Dropoutを利用するために、ドロップアウトのオブジェクトを生成します。PyTorchでは、ドロップアウトはtorch.nn.Dropoutとして準備されています。
d = nn.Dropout(p = 0.5)引数pは、ゼロにする確率です。0.5を指定すると、各要素は1/2の確率でゼロになります。
では、実際の動きを見ていきます。
Dropoutの動きを確認
1.0を100個並べたデータを用意して、実際にドロップアウトの出力を確認してみます。
p = 0.4
d = nn.Dropout(p = p)
x = torch.tensor([1.0]*10)
print(x)
y = d(x)
print(y)出力
tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
tensor([1.6667, 0.0000, 0.0000, 0.0000, 1.6667, 1.6667, 0.0000, 1.6667, 1.6667, 0.0000])
結果を見ると、いくつかの値が0.0000になっているのが確認できます。
ただ、1も1.6667になっています。これはどういうことでしょうか。
Pytorchのマニュアルを見ると、出力は$\frac{1}{1-p}$でスケーリングされるということです。
$\frac{1}{1-0.4} \sim 1.6667$なので、1.0がこれでスケーリングされて$1.0 \times 1.6667 = 1.6667$と変化したためです。
この操作を行うことで、入力の総和がドロップアウト前後で変化することを防ぎます。
数学的には、期待値を変化させないようにするという説明になりますが、ドロップアウト前と後で総和を一致させるためと考えてOKです
スケーリングされることは知らない人も多そうですね
確率で指定した数になっているか確認してみる
引数pで指定した確率と、実際にゼロに変化した個数を見てみます。
以下のコードは、1.0が100個の入力データに対して、p=0.5としてドロップアウトを繰り返して、何個がゼロになったかを確認するものです。
for _ in range(10) :
p = 0.5
d = nn.Dropout(p = p)
x = torch.tensor([1.0]*100)
y = d(x)
print(sum(y==0))
出力
tensor(48)
tensor(50)
tensor(46)
tensor(51)
tensor(57)
tensor(50)
tensor(53)
tensor(37)
tensor(51)
tensor(41)結果を見ると、必ず50個が変化しているのではなく、結構ばらつきがあることがわかります。
確率0.5でランダムにゼロにしているので、ばらつきによってゼロが多かったり、少なかったりするためです。
具体的には、ベルヌーイ分布からのサンプルに従って要素の確率をゼロにします
訓練時と推論時の動き
「訓練(トレーニング時)はいいけど、推論時はドロップアウトはどういう動作をするの?」と考える方も多いと思います。
ドロップアウトは学習時の手法なので、訓練時(トレーニング時)だけ動作し、推論時はOFFになるはずです。
実際に動作を確認してみます。
p = 0.5
d = nn.Dropout(p = p)
x = torch.tensor([1.0]*10)
# 訓練モード
d.train()
y = d(x)
print(y)
# 推論モード
d.eval()
y = d(x)
print(y)出力
tensor([0., 0., 2., 2., 0., 2., 2., 0., 0., 0.])
tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])訓練モードと推論モードは、.train()と.eval()を呼び出すことで切り替えができます。
結果を見ると、推論モードではドロップアウトが行われていないことが確認できます。
これを見ると、ドロップアウト層が存在するモデルを訓練モードで実行すると精度が落ちそうです。
推論で使うときは、eval()を忘れないよう
BatchNormalizationも同じように訓練と推論で動きが違うので注意です

Batch Normalizationの仕組みと学習・推論時の動作の違いを理解する 【初級 深層学習講座】
ドロップアウトさせる確率pはどれくらいに設定するのがよいか?
モデルによって異なりますが、一般的には0.2〜0.5の範囲を設定することが多いようです
あくまで一般的な指針なので、最適というわけではありません。
まずは、この範囲の値を試してみれば良いと思います。
実際には、試行錯誤が必要です。実際に学習を行う場合は、いくつかの値を試してみましょう。
まとめ
以上、Pytorchのドロップアウトの動きについて説明しました。
ドロップアウトとバッチ正規化はディープラーニングの分野の重要な発明と言われています。この2つにより、訓練の安定性・性能が向上しました。
今回は、この1つのドロップアウトについて説明しましたが、興味がある方はバッチ正規化の記事も読んでみてください。



ディープラーニングに関する記事一覧はこちら

ディープラーニング関連の記事一覧
ABOUT ME

専門分野は並列処理・画像処理・機械学習・ディープラーニング。プログラミング言語はC, C++, Go, Pythonを中心として色々利用。現在は、Kaggle, 競プロなどをしながら悠々自適に活動中



