
PyMC(ベイズ統計モデリング)で回帰問題を解く|Python
Aru
Aru's テクログ(Aruaru0)

EasyOCRは、画像から文字列を抽出してテキストとして取り出すPython向けのライブラリです。ディープラーニング技術を使っているおかげか検出・認識制度もかなり良いです。また、なんといっても使い方が簡単な点がポイントが高いです。この記事では、EasyOCRの使い方について、サンプルコードを交えながら紹介したいと思います。
OCR(Optical Character Recognition、光学文字認識)は、印刷されたテキストや手書きの文字をデジタルデータに変換する技術のことです。
OCRを使えば、画像中の文字を読み取り、テキストとして保存することが可能です。
例えば、レシートをカメラやスキャナで取り込んで、そこから文字列を抽出してテキストデータにしたり、看板の文字を読み込んでテキスト化することができます。
テキスト化できれば、例えば、翻訳ソフトで翻訳したり、他の言語に変換したりすることもできます。また、レシートのデータを表計算ソフトに取り込んだりすることも可能です。
EasyOCRはgithubに公開されているPython向けのOCRライブラリで、80以上の言語に対応しています。もちろん日本語にも対応しているので、日本語をテキスト化することも可能です。
EasyOCRはディープラーニング技術を用いたライブラリで、精度が高いのも特徴の1つです。また、ライブラリの使い方も簡単なので、自分のプトグラムに簡単に使うことが可能です。

無料のOCRとしてはTesseractが有名ですが、こちらの方が少し精度が高い気がします(ベンチーマークをちゃんとしていないので気のせいかもしれませんが)。
とりあえず、Pythonのプログラムにちょっと組み込んで利用するのにとても便利なOCRライブラリです。
Github : https://github.com/JaidedAI/EasyOCR
インストールは簡単です。以下のコマンドを実行するだけです。
pip install easyocrimport easyocrReaderオブジェクトを生成します。Reader()の引数は文字認識する言語(複数の場合はリスト)とgpuを利用するかどうかです。GPUを利用するかどうかを指定する引数gpuは、TureまたはFalseを指定します。
GPUを使うとかなり高速になるので、GPUがある場合はgpu=Trueをお勧めします。なお、対応する言語のモデルがダウンロードされていない場合は、自動的にモデルをダウンロードが行われます(初回利用時はダウンロードが行われるかと思います)。
reader = easyocr.Reader(['jp', 'en'], gpu=True)指定できる言語は以下の通りです。この中から必要な言語を設定してください(英語と日本語のの場合は['en','jp']を指定)。
言語は必要なものだけを設定することをお勧めします。指定し過ぎると認識ミスが発生しやすくなると思われます(未確認ですが、原理的に)。
| Language | Code Name |
|---|---|
| Abaza | abq |
| Adyghe | ady |
| Afrikaans | af |
| Angika | ang |
| Arabic | ar |
| Assamese | as |
| Avar | ava |
| Azerbaijani | az |
| Belarusian | be |
| Bulgarian | bg |
| Bihari | bh |
| Bhojpuri | bho |
| Bengali | bn |
| Bosnian | bs |
| Simplified Chinese | ch_sim |
| Traditional Chinese | ch_tra |
| Chechen | che |
| Czech | cs |
| Welsh | cy |
| Danish | da |
| Dargwa | dar |
| German | de |
| English | en |
| Spanish | es |
| Estonian | et |
| Persian (Farsi) | fa |
| French | fr |
| Irish | ga |
| Goan Konkani | gom |
| Hindi | hi |
| Croatian | hr |
| Hungarian | hu |
| Indonesian | id |
| Ingush | inh |
| Icelandic | is |
| Italian | it |
| Japanese | ja |
| Kabardian | kbd |
| Kannada | kn |
| Korean | ko |
| Kurdish | ku |
| Latin | la |
| Lak | lbe |
| Lezghian | lez |
| Lithuanian | lt |
| Latvian | lv |
| Magahi | mah |
| Maithili | mai |
| Maori | mi |
| Mongolian | mn |
| Marathi | mr |
| Malay | ms |
| Maltese | mt |
| Nepali | ne |
| Newari | new |
| Dutch | nl |
| Norwegian | no |
| Occitan | oc |
| Pali | pi |
| Polish | pl |
| Portuguese | pt |
| Romanian | ro |
| Russian | ru |
| Serbian (cyrillic) | rs_cyrillic |
| Serbian (latin) | rs_latin |
| Nagpuri | sck |
| Slovak | sk |
| Slovenian | sl |
| Albanian | sq |
| Swedish | sv |
| Swahili | sw |
| Tamil | ta |
| Tabassaran | tab |
| Telugu | te |
| Thai | th |
| Tajik | tjk |
| Tagalog | tl |
| Turkish | tr |
| Uyghur | ug |
| Ukranian | uk |
| Urdu | ur |
| Uzbek | uz |
| Vietnamese | vi |
ファイル(xxx.jpg)を読み込んで処理する場合、以下のように記述します。
result = reader.readtext('xxx.jpg')OpenCVで読み込んだ画像データ(img)に対して処理することも可能です
img = cv2.imread('xxx.jpg')
result = reader.readtext(img)URLを指定して処理することも可能です
result = reader.readtext('https://xxxx/xxx.jpg')resultには、OCRの結果が戻ってきます。デフォルトの出力フォーマットは以下になります。
[
([[x0, y0],[x1, y1],[x2, y2],[x3, y3]], 文字列, 信頼度),
([[x0, y0],[x1, y1],[x2, y2],[x3, y3],], 文字列, 信頼度),
: 検出した個数
][[x0, y0],[x1, y1],[x2, y2],[x3, y3]]は文字列を検出した画像の4隅の座標です。
なお、detail=0を指定すると、出力は検出した文字列だけになります。
また、paragraph=Trueを設定すると、検出結果を段落に結合して出力します。
とりあえず、手元にあった説明書の1ページを読み取ってみました。
説明書の内容は以下になります。ファイル名はtest.pngです。

まず、easyocrをインポートして、readerオブジェクトを生成し、reader.readtext()で文字認識を実行します。
import easyocr
image_path = "test.png"
reader = easyocr.Reader(['ja','en'],gpu = True)
result = reader.readtext(image_path)上記の結果、resultにOCRの結果が格納されます。
以下のプログラムは、これを表示するものです。
print("==========検出結果===========")
for e in result:
print(e)実行結果は以下になります。以下のように、文字列のある枠座標と、文字列の内容、信頼度が格納されていることがわかります。認識された文字列を見ると、結構良い精度でテキストに変換されていることがわかります。

次に、文字列と信頼度を抜き出し、それぞれに番号を割り当ててみます。また、それぞれの番号がどの位置なのかを、画像上に枠と番号で表示してみました。
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread(image_path)
for i, (pos, txt, prob) in enumerate(result) :
print(i,":", txt, "prob = ", prob)
img = cv2.polylines(img, [np.array(pos, np.int32)], True, (0, 255, 0), 2)
img = cv2.putText(img, str(i), (int(pos[0][0]), int(pos[0][1])), cv2.FONT_HERSHEY_SIMPLEX, 2, (255, 0, 0), 2)
cv2.imwrite("result.png", img)
plt.imshow(img)
plt.show()番号:文字列:信頼度は以下になります。

それぞれの文字列が検出された位置です。赤文字が番号です。
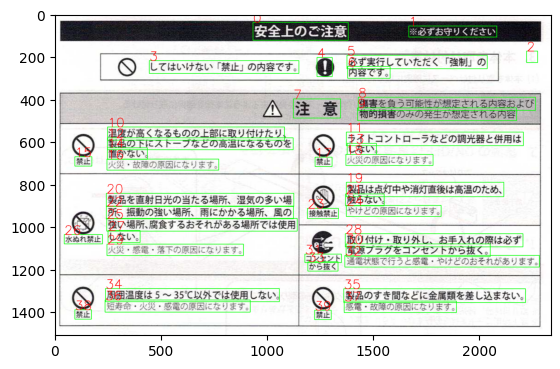
結果を見た感じ、かなり良い精度で文字認識ができているように見えます。
最後に、paragraph=Trueにして、文章にまとめてみます。
result = reader.readtext(image_path, detail = 0, paragraph = True)
print(result)結果は以下になります。'...'の部分が1つの文章です。
例えば、「‘注 意 傷害を負う可能性が想定される内容および 物的損害のみの発生が想定される内容 温度が高くなるものの上部に取り付けたり一 製品の下にストーブなどの高温になるものを ライトコントローラなどの調光器と供用は 置かない しない 火災 ・故墓の原因になります。 禁止 火災の原因になります。‘」が1文としてまとめられています。ちょっと微妙かもしれませんが、それなりにキチンと接続されている感じです。
['安全上のご注意', '※必ずお守りください', '~', 'してはいけない 「禁止」 の内容です', '』 必ず実行していただく 「強制」 の 内容です。', '注 意 傷害を負う可能性が想定される内容および 物的損害のみの発生が想定される内容 温度が高くなるものの上部に取り付けたり一 製品の下にストーブなどの高温になるものを ライトコントローラなどの調光器と供用は 置かない しない 火災 ・故墓の原因になります。 禁止 火災の原因になります。', '禁止', '製品は点灯中や消灯直後は高温のため 製品を直射日光の当たる場所 湿気の多い場 触らない 所 振動の強い場所 雨にかかる場所 風の 接舘禁止 やけどの原因になります。 強い場所 腐食するおそれがある場所では使用 水ぬれ禁止 しない_ 取り付け ・ 取り外し お手入れの際は必ず 火災・惑電・落下の原因になります。 電源プラグをコンセントから抜く。 コンセント 遥電状態て行うと感電・やけどのおそれがあります。 から抜く', "周囲温度は5 ~ 35以外では使用しない。 短寿命'火災 ・ 感電の原因になります。", '製品のすき間などに金属類を差し込まない。 感電・故障の原因になります』 禁止', '禁止']画像中の文字を認識するEasyOCRについて解説しました。GPUを使うと結構高速に動作します。また、精度もそれなりだと思います。
例えば、株の配当通知から社名と金額を抜き出すアプリとかは簡単につくれそうな気がします。いろいろな場面で使える気がします。
ちなみに、kaggleで、画像から文字を抽出し、特徴量の1つとして使ったことがあります。結構高速で、絵柄の文字も検出・認識してくれるので重宝しました。




