
YOLOv5を使った独自データの学習と推論|ultralytics YOLOリポジトリ
Aru
Aru's テクログ(Aruaru0)
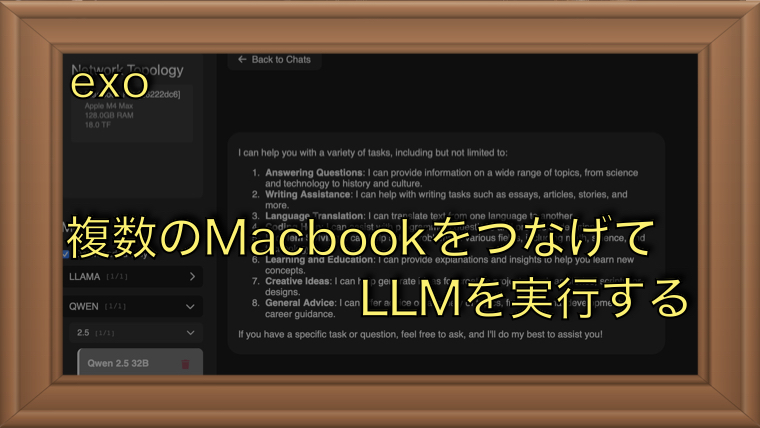
この記事では、複数台のPCを連携させて大規模なLLM(大規模言語モデル)を動作させるためのツール「exo」を試してみました。exoは、同一ネットワークに接続されたPCをAIクラスタとして活用し、分散処理によってLLMを実行できるツールです。単体のPCではGPUメモリ不足で動作できなかった大規模モデルも、複数のPCを組み合わせることで実行可能になります。今回は、3台のMacBookを使用して「exo」をセットアップし、LLMを動作させるまでの手順とその結果を詳しく紹介します。
exoは、複数のPCを連携させてAIクラスタを構築し、大規模なモデルを実行できる環境を提供するツールです。このツールは、同じLANに接続された複数のPCを自動的に検出・接続し、クラスタを形成します。その上でローカルLLM(大規模言語モデル)を分散処理することが可能です。
この仕組みにより、単体のマシンではメモリや計算能力が不足して動作しないような大規模モデルでも、複数のPCに負荷を分散させながら実行できます。
github: https://github.com/exo-explore/exo
今回は、Apple Silicon搭載のMacを3台使用してクラスタを構成し、モデルの動作を検証しました。ツール自体はNVIDIAのGPUを搭載したマシンとのクラスタ構築や、異なるアーキテクチャを組み合わせたハイブリッドクラスタの構成も可能なようですが今回は試していません。

今回、実験を行った環境です
exoのインストールは、公式のREADMEに記載されている手順に従って実行しました。
私の環境では、M4 Max搭載のMacでは uv を使用して環境を構築し、残りの2台のMacでは miniforge を利用しました。それぞれのマシンで仮想環境を作成した後、exoをインストールしています。手順は以下の通りです。
git clone https://github.com/exo-explore/exo.git
cd exo
pip install -e .もし、uvやcondaを使っていないのであれば、pip install -e .は以下に置き換えることでvenvを使った仮想環境が構築されます。
source install.sh
注意するのは、Pythonのバージョンです。ドキュメントには3.12.0以降のPythonバージョンを使うことが推奨されています。
私の環境では、1台が128GB、残り2台が16GBのメモリ構成になっています。単体のマシンでは動作が難しく、かつ、複数台を組み合わせることで動かせるようになるモデルがなかったため、まずは、動作確認の目的で Qwen 2.5 32B を実行してみました。
exoの実行は非常にシンプルで、各PCで以下のコマンドを実行するだけです。
exoこのコマンドを実行すると、以下のような画面が表示され、3台のPCが正しく接続されていることが確認できます。
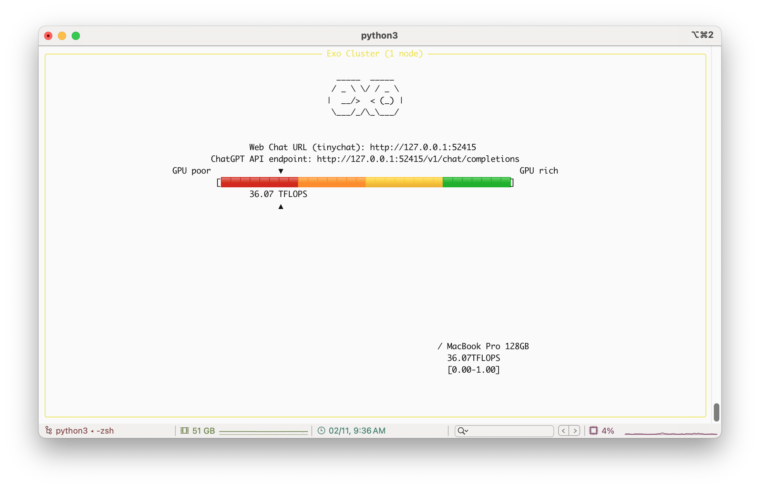
M4Max一台だけで実行した時の画面が以下になります。
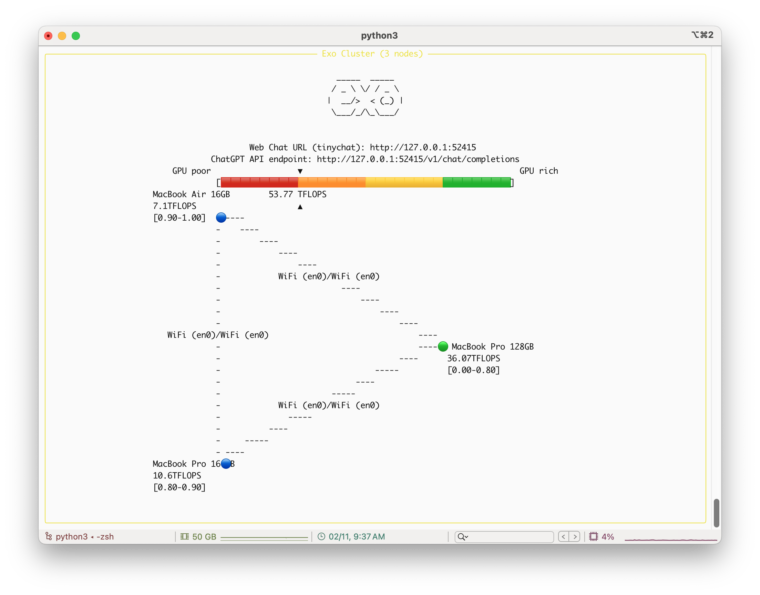
ここから、他の2台で起動した後の画面がこちらです。下のキャプチャ画面のように3つのPCが接続されてクラスタを構成していることがわかります。なお、単体のFLOPSが36.07TFLOPSだったのに対し、3台の合計は53.77TFLOPSになっていることもわかります。
モデルのダウンロード中や、実行中のサスペンドを防ぐために、以下のコマンドを別のターミナルで実行しておくことをお勧めします。
このコマンドを実行している間は、PCが自動でスリープ状態になるのを防ぐことができます。サスペンドさせたい場合は、このコマンドを Ctrl + C で中断する必要がある点に注意してください。
caffeinate -iどちらかのPCでhttp://127.0.0.1:52415にアクセスし、tinychatを動かします。左から利用したいモデルを選びますが今回は、Qwen 2.5 32Bというモデルを選択しました。
モデルを初回使う場合、モデルのダウンロードが始まります。大きなモデルの場合は時間がかかるのでかなり待つ必要がある点に注意してください。
2回目以降はダウンロードはありませんが、初回実行時はモデルのロードに少し時間がかかります。
私の環境では、MacBook Airで実行した際に、最初の “Checking Download status…” の表示で止まってしまい、うまく動作しませんでした。
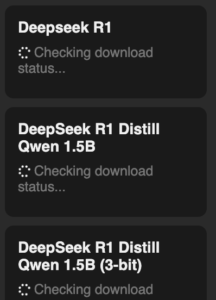
この問題は、以下のコマンドを実行し、Hugging Faceのアクセストークンを使ってログインすることで解決しました。ログインには、huggingface-cli loginとコマンドを入力してアクセストークンを登録します。
3台で実行した場合の速度は 約4.5 token/sec でした。Wi-Fiの通信速度によってパフォーマンスに差が出る可能性があります。私の環境では Wi-Fi 5 を使用しているため、通信速度がやや遅めなのかもしれません。
とはいえ、3台のPCが連携してモデルを実行できることを確認できました。
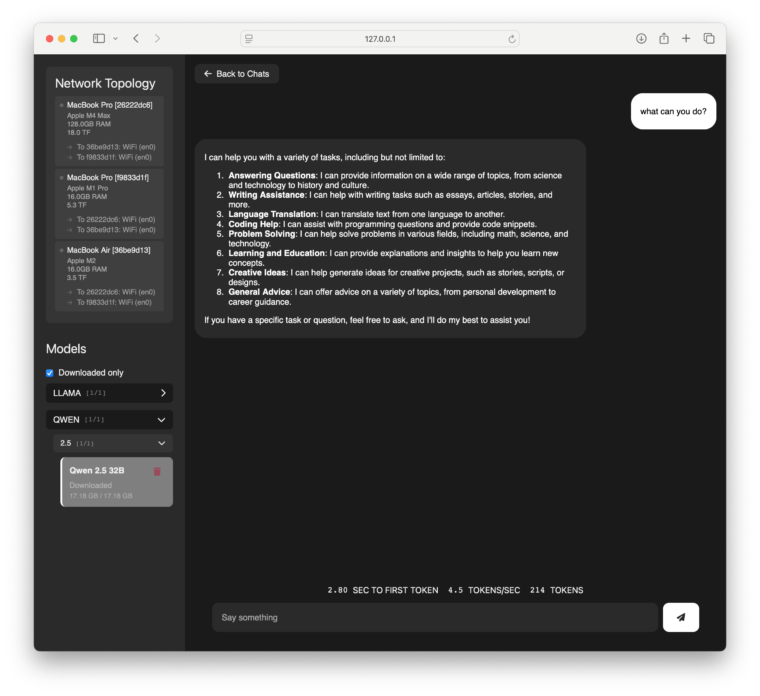
ちなみに、MacBook Pro (M4 Max) 単体では 10.1 token/sec の速度でしたが、3台で実行すると速度が低下し、約 4.5 token/sec になりました。これは、複数のPC間で通信を行っていることがボトルネックになっているためです。
速度に関しては、より高速なネットワーク環境を整えれば、改善が期待できるかもしれません。
とはいえ、1台ではメモリ不足で動かせないような大きなモデルでも、複数のPCを使うことで動作可能になる点は非常に有用です。
とりあえず、exo は非常に面白いツールだと感じました。インストールも実行も簡単で、インターフェースも直感的です。とりあえず、メモリが足りなくても複数のPCを活用することで大きなモデルを動かすことができるという可能性を実感できました。
例えばMacStudio(192GB)を3台用意すればDeepSeek-R1を動かすこともできるかもしれません。夢が膨らみます。
ここでは、メモリ16GBのMacBook 2台を使用して、Qwen 2.5 32B を動かしてみます。このモデルは 17.18GB のメモリを必要とするため、1台だけでは動かすことができません。しかし、2台を使えば、十分なメモリを確保できるため、動作させることが可能なはずです。
2台でクラスタを作成し、Qwen 2.5 32B を実行してみました。結果として、2台構成でモデルをロードし、実行することができました。実行速度は約 3.1 token/sec でした。
exo を使用することで、1台では実行できなかったサイズのモデルを、複数台で実行できることを確認できました。
今回は、複数台のPCをローカルLANで接続し、AIクラスタを構成するためのツール exo を実際に使用した結果を記事にしてみました。このツールのインストールと実行が非常に簡単でした。おそらく、それほどトラブルなく使うことができると思います。
また、OpenAIのChatGPT互換のAPI を利用できるため、さまざまなツールから呼び出して使うことも可能です。
個人的には、このツールは非常に面白く個人でローカルLLMを立ち上げたい・試してみたい人にはかなり有用と感じました。



