
Item2Vec: 商品レコメンドの実装(関連性の学習とお勧め商品予測)
Aru
Aru's テクログ(Aruaru0)

この記事では、LightGBMやXGBoostなどの機械学習アルゴリズムで効果的に活用できる前処理と特徴量エンジニアリングの基本手法を、Pythonのコード例を交えて詳しく解説します。データのスケール変換やセンタリングといった前処理から、新たな特徴量を生成するためのテクニックまでカバーした内容になっています。初心者から中級者まで、実践的な知識を得られる内容を心がけました。
データの前処理とは、機械学習アルゴリズム(例えばLightGBMなど)にデータを入力する前に、データを適切な形式に加工するプロセスです。この加工には、スケーリングやセンタリング、欠損値の処理などが含まれます。
特徴量エンジニアリングは、与えられたデータから新しい特徴量を作成するものです。これにより、モデルがより有益な情報を与えることができ、精度を向上させることができます。
前処理と特徴量エンジニアリングは、機械学習モデルの性能を向上させるために不可欠です。例えば、データのスケーリングや変換によって、モデルがデータのパターンをより効果的に学習できるようになります。
特徴量エンジニアリングでは、入力データから重要な情報を抽出し、新たな特徴量を生成することで、モデルの精度と汎化性能を高めることができます。特にKaggleなどの機械学習のコンペでは、特徴量エンジニアリングの良し悪しが結果を大きく左右することも多いです。
このように、データの前処理と特徴量エンジニアリングは、機械学習モデルの精度向上に欠かせない重要な手法です。

特徴量エンジニアリングは「データから新しい特徴量を作成する」ものなので、前処理とは異なるものと捉えることがありますが、ここでは、前処理と特徴量エンジニアリングを区別せずに説明します
入力されたデータの中心値と、幅を変換する処理です。代表的な手法として、正規化(Normalization)と、標準化(Standarization)があります
データを「最小値=0、最大値=1」の集合にまとめる操作です(別名Min-Max Scalingと呼ばれます)。
具体的には、以下のような計算式になります。
x_dash = (X - min(x))/(max(x) - min(x))以下は、-100~100の範囲のデータを0~1に正規化する例です。
x = np.random.randint(-100, 100, 1000)
x_dash = (x - np.min(x))/(np.max(x) - np.min(x))
fig = plt.figure()
ax1 = fig.add_subplot(1,2,1)
ax1.hist(x)
ax2 = fig.add_subplot(1,2,2)
ax2.hist(x_dash)
plt.show()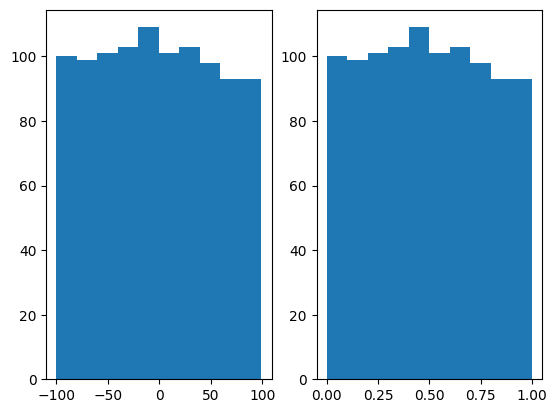
データを「平均値=0、標準偏差=1」の集合にまとめる操作です(標準偏差=1は分散=1と表現することもあります)。
具体的には、以下の計算式になります。
x_dash = (x - mean(x))/std(x)以下は、-100~100の範囲のデータを標準化する例です。
x = np.random.randint(-100, 100, 1000)
x_dash = (x - np.min(x))/(np.max(x) - np.min(x))
fig = plt.figure()
ax1 = fig.add_subplot(1,2,1)
ax1.hist(x)
ax2 = fig.add_subplot(1,2,2)
ax2.hist(x_dash)
plt.show()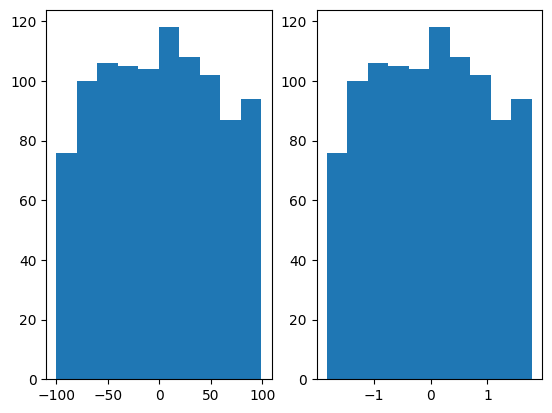
標準化の利点は、外れ値がある場合です。正規化では、極端に大きな値や小さな値がある場合、すごく狭い値の範囲にデータが集中してしまいます。

わたしの場合は、データにもよりますが、どちらかというと標準化を使うことが多いです。
正規化、標準化とは別に、正則化という言葉も聞いたことがあるかと思います。
正規化と標準化はデータのスケール変換の手法のことで、正則化はモデルの複雑さを制御し、過学習を防ぐ手法のことです(ラッソとかリッジ回帰などが有名)
ごっちゃにならない様に注意しましょう。
データの分布を正規分布に近づける技法もあります。これについては、以下の記事を参考にしてください。

主成分分析(PCA, principal component analysis)は、次元を数を削減する次元圧縮処理として良く利用されますが、データの前処理でも利用することができます。
データの前処理で利用する目的は、「説明変数同士を無相関にする」ことです。
PCAは、scikit-learnに組み込まれているので、それを利用して簡単に利用することができます。
以下は、PCAの呼び出しの例です。
from sklearn.decomposition import PCA
from sklearn import datasets
import pandas as pd
import seaborn as sns
wine = datasets.load_wine()
df = pd.DataFrame(wine.data)
pca = PCA(n_components=len(df.columns))
x_dash = pca.fit_transform(df)
print(pca.explained_variance_ratio_)pca.explained_variance_ratio_に寄与率が戻ってくるので、これを見ながら何次元までを特徴量として加えるかを調整します。
データセットに男、女などのカテゴリ変数がある場合はone-hot-encodingを行います。
LightGBMなどでは、カテゴリ変数は指定することで自動的に処理してくれますので、最近は自身でやることは少ないかもしれません
one-hot-encodingとは、例えば以下のようなデータに対して性別の列を、男・女の列に分けて0,1で表現する方法です。
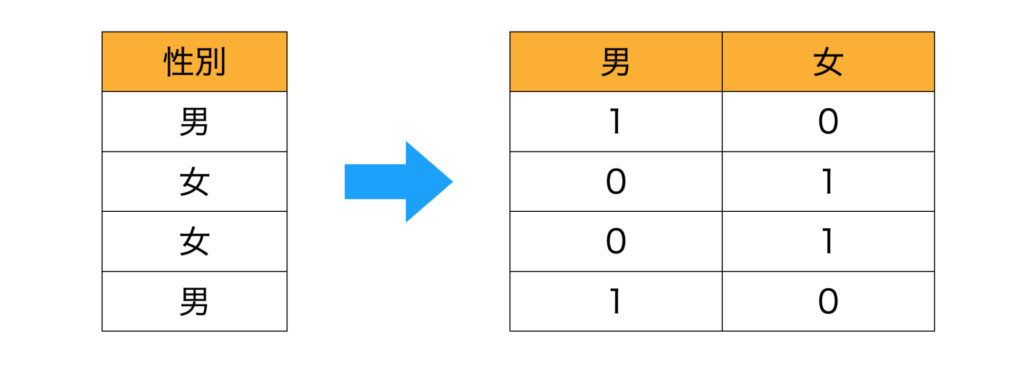
one-hot-encodingを行うと、列がカテゴリ種の数だけ増加します。
from sklearn import preprocessing
import numpy as np
import pandas as pd
df = pd.DataFrame( ['男','女','女','男'] )
enc = preprocessing.OneHotEncoder(sparse=False)
print( enc.fit_transform( df ) )[[0. 1.]
[1. 0.]
[1. 0.]
[0. 1.]]何時何分などのデータの場合、周期性を考慮したいことがあります。そのまま0時0分〜23時59分という形で扱うと、23:59と0:0の間が不連続になってしまいます。
これを防ぐために、時間データを極座標に変換して利用することがあります。
これにより、24時間の周期性を明示的に捉えやすくなります。
この変換は、例えば以下の様な関数で実現できます。
import math
def time_to_polar_coordinates(h, m):
# 時間を角度に変換
angle = ((h % 24) + m / 60) * 360 / 24
# ラジアンに変換
angle_rad = math.radians(angle)
# 極座標(x, y)に変換
x = math.cos(angle_rad)
y = math.sin(angle_rad)
return x, y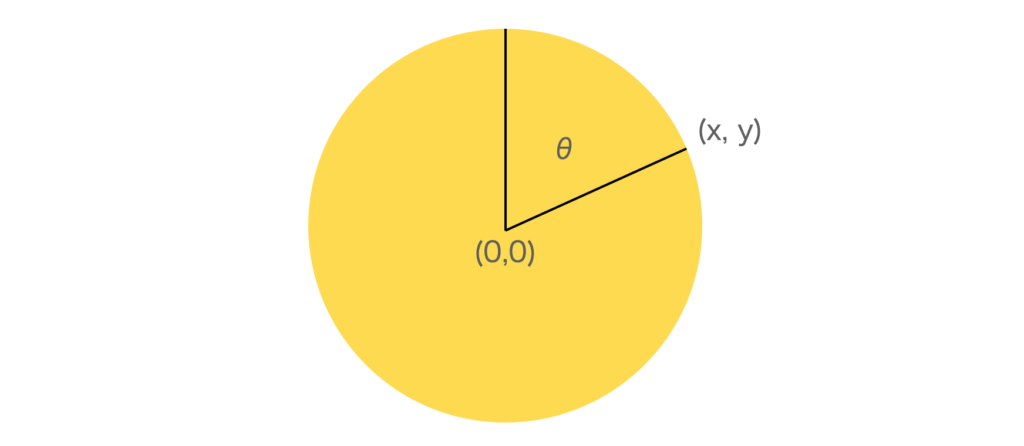
ここでは、kaggleなどで利用されている、少し高度な特徴量エンジニアリングについて説明します。
欠損値の処理については、他の記事に詳しくまとめましたのでそちらを参照してください。欠損値をどう扱うかも性能に影響しますので、いろいろな手法を試してみることをお勧めします。

列が多い場合や、複数のデータがある場合は、欠損値を予測する予測器を別途作り、欠損値を埋めるという方法も考えられます。特に大量の欠損値データが利用できる場合には効果があるかもしれません。
テーブル内で、カテゴリ変数が同じもの同士で統計量をとることで、新しい特徴量を作る手法。統計量としては、mean, min, max, stdなどが考えられる。
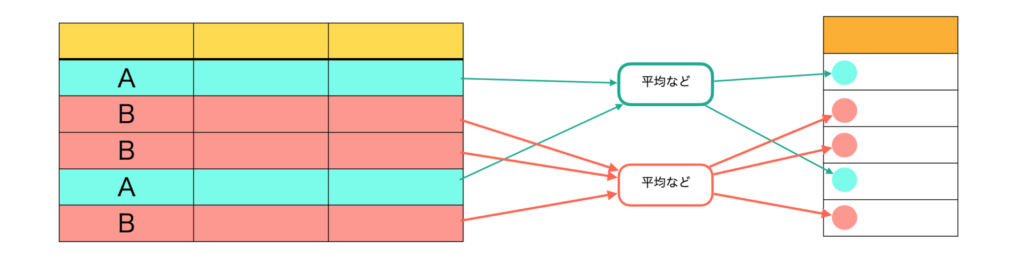
タイムスタンプなどがあるデータの場合は、一定の時間範囲で統計量を計算するという方法も考えられます
複数テーブルをまとめる場合にも、統計量を使った集約を行うことができます。
例えば、片方のテーブルにはID1つにつき1行が割り当てられていて、もう1つのテーブルにはID1つにつき複数行が割り当てられている場合、複数行の方をIDごとに統計量を計算し、1行1IDのテーブルに追加していきます。
具体例としては、1つが顧客の性別・年齢などのテーブルで、もう1つのデータが顧客の購入商品、単価などのテーブルであれば、(顧客ID、性別、年齢、平均購入単価、購入単価の最大、購入単価の最小、購入単価の分散)という列を持つテーブルを作成します。
イメージとしては、片方のテーブルが顧客のデータベース、もう1つが商品の売上データ(商品ごとにだれが購入したかのデータ)などが考えられます。
勾配ブースティングを使う手法(lightGBM, XGBoost, CatBoostなど)では、差(引き算)や比(割り算)を直接表現することができません。
このため、四則演算を行なった結果を特徴量に加えることで精度向上できることがあります。
例えば、身長と体重の比率などを新たな特徴量とすることも考えられます。
また、集約した特徴量との差、例えば平均身長からの差などを新たな特徴量とすることも考えられます。
四則演算を行なった結果の解釈性も重要だと思います
例えば、身長と体重の比などは、太り具合と解釈できそうです
他の予測器で予測した結果を特徴量に追加するなども考えられます。
例えばMLPやディープラーニング等を用いて予測した結果を勾配ブースティングの特徴量として入力するなども考えられます。
画像データがある場合は、CNNを使って画像特徴量を抽出し、縮退して列に追加するという方法も考えらます。
画像や音声などのデータは、深層学習モデルを使って特徴量に変換すればlightGBMなどの列として入力することができます(実際やってみると、効果があったり、なかったりで悩ましいですが)。
私自身、kaggleの参加で特徴量エンジニアリングの手法と重要性について学びました。
前処理・特徴量エンジニアリングの学習には、kaggleに勝つデータ分析技術について書かれた、以下の書籍がおすすめです。
機械学習の前処理・特徴量エンジニアリングの手法を解説しました。
特徴量エンジニアリングは性能改善にかなり重要な部分です。
今後も、気づいたものがあればここに追加していきます。
kaggleコンペに出るたびに、取り組みや上位の解法から気づきがあります。汎用的に使えそうなものがあればここにメモ代わりに追加していく予定です。



