
Pythonでカラーノイズ(ピンクノイズ、ホワイトノイズ)を生成する|サウンドデータ
Aru
Aru's テクログ(Aruaru0)

この記事では、Hugging FaceTransformerのBERTモデルを使用して、日本語テキストの回帰分析を実践する方法を解説します。BERTは高精度なテキスト分類を実現する自然言語処理モデルであり、Hugging Faceのライブラリを使うことで、BERTを簡単に導入できます。具体的なデータセットを用いた手順やコード例を交えながら、BERTを用いた回帰分析のやり方を解説します。
コードは、githubに置きましたのでそちらも参考にしてください。
github: Colab用のコードはこちら
BERTを用いたクラス分類については以下の記事を参考にしてください

クラス分類と回帰の違いはなんでしょうか。
簡単に言えば、データが属するクラスを予測する場合がクラス分類で、値を予測する場合は回帰となります。
具体例を挙げると、今回使う問題になりますが、Amazonの評価が⭐️幾つかを分類問題として解く場合はクラス分類、⭐️1〜5のどのあたりにか(たとえば⭐️3.4など)の値を予測する場合は回帰となります。
今回は、レビュー記事が⭐️幾つのものかという予測を、回帰問題として予測したいと思います。
前回も書いたように、BERTを利用する場合は、再学習ではなくてファインチューニングがメインとなります。というのも、BERTをゼロから学習させるのは大変で、それなりのGPUなどのリソースが必要となるため、個人レベルでやる場合はどうしてもファインチューニング程度しかできないというのがあります。
回帰問題に対してファインチューニングする場合も、処理の流ればクラス分類の場合と同じで以下になります。
今回も、Google Colabを利用して実装していますのでColabを利用して試すことができます(GPUを利用するようにしてください。利用しないと処理時間がとんでもなくかかります)
必要となるパッケージをインストールします。まずはHugging Face関連です。
!pip install transformers
!pip install datasets
!pip install evaluate
!pip install git+https://github.com/huggingface/accelerateパッケージのインストールでの注意点は、accelerateです。これを
!pip install accelerateとしてインストールするとColabではうまく動きません(ランタイムの再起動が必要になります)。普通に、ローカルの環境で動かす場合は、pip install accelerateでOKです。
次に、日本語関連のパッケージをインストールします。日本語のBERTを利用する場合には、日本語の形態素解析などのために、以下のパッケージのインストールが必要となります。
今回はモデルにcl-tohoku/bert-large-japaneseを使います。bert-bese-japaneseでは、unidic-liteは必要ありませんでした、largeでは必要となるのでインストールしておきます。
!pip install fugashi
!pip install ipadic
!pip install unidic-lite 
私の場合、必要パッケージの追加は、「エラーが出たら」都度追加しています。足りないパッケージは、エラーメッセージに書かれていることが多いです。
今回は、Hugging Faceで準備されているtyqiangz/multilingual-sentimentsというデータセットを利用します。
amazon_reviews_multiが公開停止になったので、データセットを別のものにして記事を更新しました。実行でききなかった方、申し訳ありませんでした。
これを利用するには、load_dataset関数を利用します。また、日本語のものだけ使うので、日本語だけを取り出すようにします。
from datasets import load_dataset
dataset = load_dataset("tyqiangz/multilingual-sentiments", "japanese")データセットは以下の構成になっています
DatasetDict({
train: Dataset({
features: ['text', 'source', 'label'],
num_rows: 120000
})
validation: Dataset({
features: ['text', 'source', 'label'],
num_rows: 3000
})
test: Dataset({
features: ['text', 'source', 'label'],
num_rows: 3000
})
})データセットをPandasのデータフレームに変換する場合は以下のようにします。
dataset.set_format(type="pandas")
train_df = dataset["train"][:]
train_df.head(5)
データセットをトークン化するには、Tokenizerを利用します。まず、学習済みのトークナイザーを取得します。今回利用するモデルは、cl-tohoku/bert-base-japaneseという日本語向けのBERTのモデルです。
Tokenizerの動きに興味がある場合は以下の記事を参考にしてください

Hugging Faceでは、ここからモデルの検索ができるので使いたいモデルを探してください。cl-tohokuは、東北大学が作成したモデルになります。今回は、この中のベースモデルを利用しています。
from transformers import AutoTokenizer
model_ckpt = "cl-tohoku/bert-large-japanese"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)トークナイザーで変換するとテキストは以下のようになります。
元のテキスト: 「普段使いとバイクに乗るときのブーツ兼用として...」
トークン化したもの: 「2, 9406, 3276, 13, 10602, 7, 11838, 900, 5, ...」
トークンを文字に変換: 「'[CLS]', '普段', '使い', 'と', 'バイク', 'に', '乗る', ...」トークン化するとCLSとSEPという特殊なトークンが入ります。CLSは先頭に入るものでclassification embeddingと呼ばれています。
BERTのモデルでは、文字列は数値化されたトークンとして入力するわけです。
ところで、日本語用のトークナイザーを使わないと、日本語の分割はうまくいきません(形態素解析が必要なため)。multilingualという多国語対応のBERTもありますが日本語だけを対象とするなら、日本語モデルを利用した方が良い結果が得られると思います。
amazon_reviews_multiは大きくて、学習に時間がかかります。今回は、動作実験ということでデータを削減したサブセットで処理します。学習用データを2,000、検証用とテスト用データはそれぞれ1,000としました。なお、並び順が気になるので一応シャッフルして抽出しています。
bert-large-japaneseだと学習が重いので、クラス分類の時よりデータ数を減らしています。
SEED = 42
TRAIN_SIZE = 2000
TEST_SIZE = 1000
dataset["train"] = dataset["train"].shuffle(seed=SEED).select(range(TRAIN_SIZE))
dataset["validation"] = dataset["validation"].shuffle(seed=SEED).select(range(TEST_SIZE))
dataset["test"] = dataset["test"].shuffle(seed=SEED).select(range(TEST_SIZE))データセットをトークン化します。まず、トークン化するための関数を定義します。
tokenizerは、テキストを入力するとトークンを返します。引数のpaddingは、文字数が少ない場合にパディング処理を行うかどうかの指示、truncationは、最大長を超えた場合にカットするかどうかの指示です。
import torch
MAX = 512
def tokenize(batch):
enc = tokenizer(batch["text"], padding=True, truncation=True, max_length=MAX)
return encここの仕様は少し面倒なので、動作に関して追加情報を書いておきます。
padding, truncation, max_lengthの仕様が少し複雑です。
Tokenizerの挙動については以下にまとめていますのでそちらも参考にしてください
トークン化のための関数を定義したので、次にデータをトークン化します。今回読み込んだデータセットは、以下のやり方でトークン化する関数を呼び出します
dataset_encoded = dataset.map(tokenize)最後に、train, valid, testの3つのデータセットを変数に代入しておきます。
small_train_dataset = dataset_encoded['train']
small_valid_dataset = dataset_encoded['validation']
small_test_dataset = dataset_encoded['test']また、回帰を行うのでlabelを浮動小数点型に変換しておきます。
from datasets import Value
new_features = small_train_dataset.features.copy()
new_features['label'] = Value("float64")
small_train_dataset = small_train_dataset.cast(new_features)
small_valid_dataset = small_valid_dataset.cast(new_features)
small_test_dataset = small_test_dataset.cast(new_features)floatに変換するのはポイントです。これをしないと学習時にエラーになります。
データの準備ができたので、次は学習です。
まず、モデルを取得します。基本、モデルはトークナイザーと同じものを利用します。
AutoModelForSequenceClassificationを使ってモデルを取得しています。
実は、回帰問題もクラス分類用のモデルで行うことができます。回帰の場合は、num_labelsを1に設定して出力は1つにします。
import torch
from transformers import AutoModelForSequenceClassification
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_labels = 1
model = (AutoModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))次に、評価関数を定義します。今回は、他の方のコードを参考に、accuracy とf1スコアを評価関数としています。evaluateを使っても良いですが、ここでは、使い慣れたsklearnを用いています。
from sklearn.metrics import accuracy_score, f1_score
import evaluate
import numpy as np
metric = evaluate.load("mse")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
return metric.compute(predictions=predictions, references=labels)トレーニング用のパラメータを設定します。ファインチューニングなので、それほどepoch数を増やさなくて良いと思います(過学習を防止する意味もあります)。
largeモデルの場合は、GPUメモリが16GBだとあまりバッチサイズを大きくできません。ここではバッチサイズは4に設定しています。ここは、メモリ不足のエラーが出たら減らす感じで調整してください。
from transformers import TrainingArguments
batch_size = 4
logging_steps = len(small_train_dataset) // batch_size
model_name = "multilingual-sentiments-regression-bert"
training_args = TrainingArguments(
output_dir=model_name,
num_train_epochs=3,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
evaluation_strategy="epoch",
disable_tqdm=False,
logging_steps=logging_steps,
push_to_hub=False,
log_level="error"
)次に、トレーニングです。ここも、関数が用意されているので簡単です。
たった、3エポック、データ数も減らしたのに13分ほどかかりました。フルのデータで処理する場合は、数時間を覚悟する必要があるかと思います。
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=small_train_dataset,
eval_dataset=small_valid_dataset,
tokenizer=tokenizer
)
trainer.train()実行結果はこんな感じになると思います。

学習結果を確認するために、クラス分類ではないので混同行列で評価することは難しいです。ということで、各正解値に対する予測値の平均の偏差と、各正解値に対する値のばらつきをグラフ化して評価したいと思います。
ここで利用するのはテストデータです。テストデータは、学習ループで使っていないデータなので、モデルとしては初めて入力されるデータとなります。
テストデータに対する推論の実行は以下になります。
preds_output = trainer.predict(small_test_dataset)まず、平均と偏差です。
x = [[] for _ in range(5)]
cnt = 0
for p, l in zip(preds_output.predictions, preds_output.label_ids) :
x[int(l)].append(p[0]+1)
if cnt == 100 : break
cnt += 1
for i in range(5):
v = np.array(x[i])
print(f"{i+1}: mean={v.mean()}, std = {v.std()}")正解1に対して、予測値の平均は1.25,偏差は0.40なので、1.25±0.4くらいの値に68%の予測結果があることがわかります。1〜3に関して眺めると、それなりに回帰がうまくいっているように見えます。
1: mean=1.2513489521566954, std = 0.40052614396856157
2: mean=1.960308731082947, std = 0.39427579577548655
3: mean=2.77929927110672, std = 0.34950135155470685次にグラフ化です
import matplotlib.pyplot as plt
plt.scatter(preds_output.predictions+1, preds_output.label_ids+1, alpha=0.05)縦軸が正解値、横軸が推論値になります。正解値が1〜3と変化するのに対して中心も1〜3の方にずれていることがわかります。
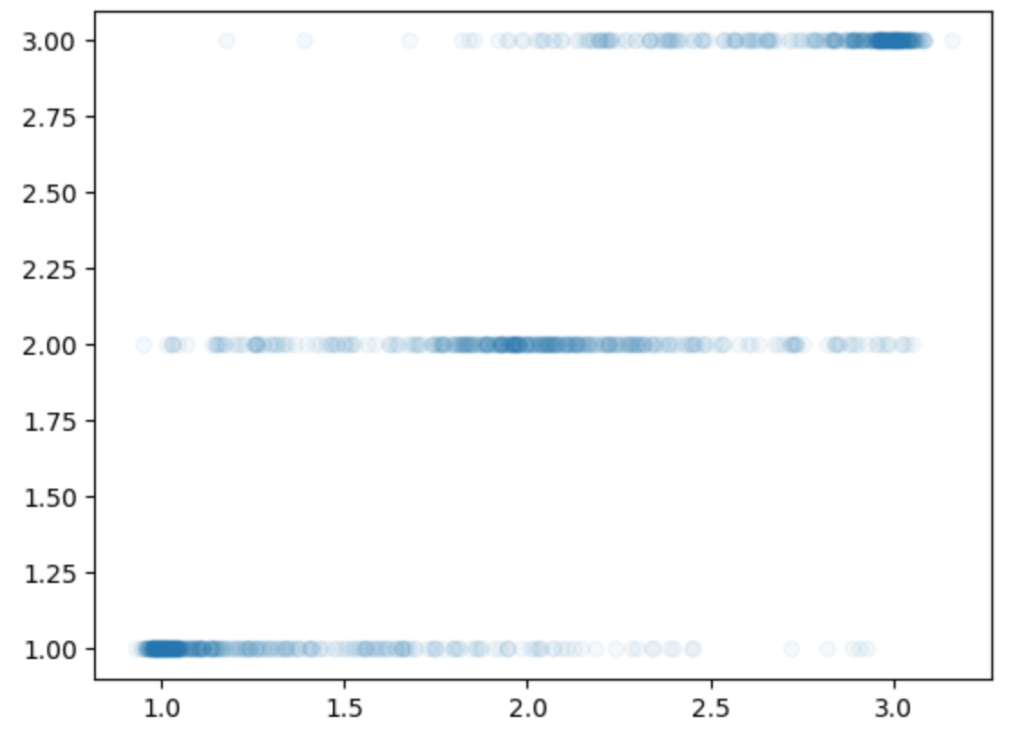
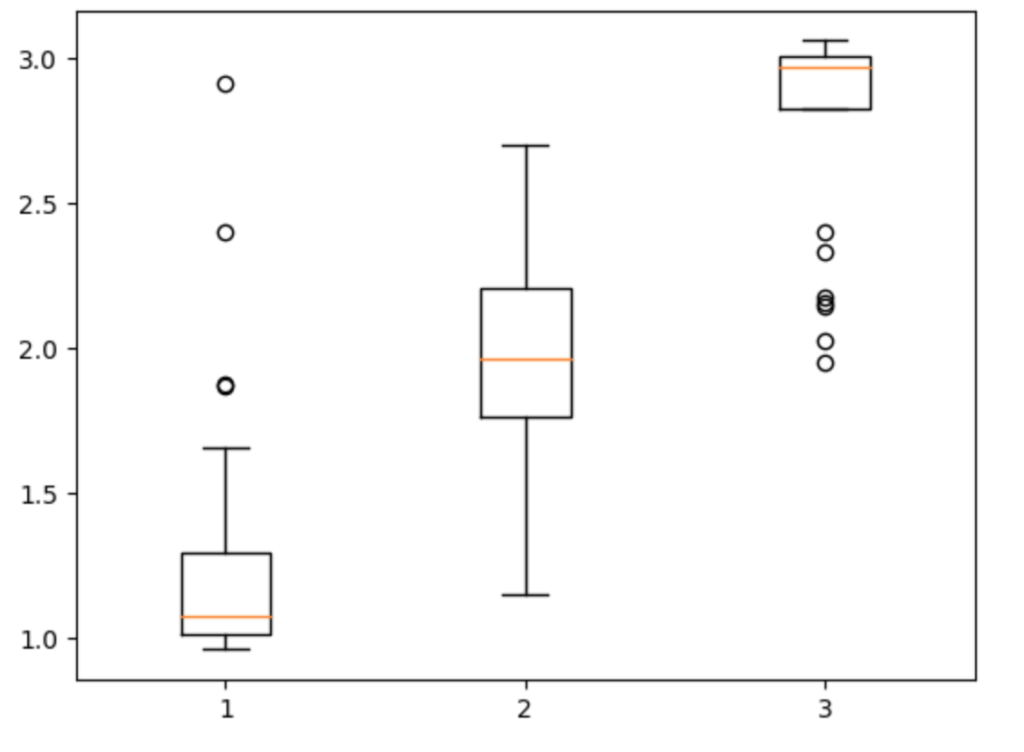
もう少しわかりやすくするために箱ひげ図にしてみます。
plt.boxplot(x)横軸が正解値、縦軸が予測値(先ほどと逆なので注意してください)です。箱ひげ図をみると、正解1〜5に対して結構うまく予測ができていることがわかります。ただ、星4と5の評価は文章からは微妙にわからないといのかも?とか色々想像できます。
最後にモデルの保存と読み込みです。保存は以下のようにします。
trainer.save_model(f"./{model_name}-test")読み込みは、以下のようにトークナイザーとモデルを別々に行います。
tokenizer = AutoTokenizer\
.from_pretrained(f"./{model_name}-test")
model = (AutoModelForSequenceClassification
.from_pretrained(f"./{model_name}-test")
.to(device))読み込みすれば、tokenizerとmodelを普通に使うことができます。
出力の部分を自作して精度向上するテクニックについては以下の記事を参考にしてください(こちらの記事は少し上級者向けです)

Hugging Faceの登場からだいぶ経ちますが、このサイトのおかけでtransformerがとても簡単に使えるようになりました。
今回は、いろいろなWeb記事を参考にしつつ、データセットを変更、モデルを変更してトライしました。色々変更しつつ自分で書いてみることで、細かな動きについても理解することができたと感じています。
ぜひ、モデルやデータセットを変えて実験してみてください。色々知見が広がるかと思います。


