

HuggingFace Transformerの精度向上テクニック | 出力のPooling手法
Aru
Aru's テクログ(Aruaru0)

この記事では、PyTorchとTIMMライブラリを使って、犬と猫の画像を分類するクラス分類タスクに挑戦します。TIMMは、豊富な事前学習済みモデルを提供し、初心者でも簡単にモデルを利用できます。具体的なコード例とともに、画像分類の手順を解説します。
PyTorchを使用してディープラーニングのモデルを作成・学習させる際、クラス分類タスクは比較的シンプルです。さらに、timm(PyTorch Image Models)ライブラリを活用することで、コードは簡単になります。このブログでは、犬と猫の画像データセットをダウンロードし、モデルの構築から学習までの手順を詳しく解説します。
コードはGoogle Colabotoryで実行できる形式としています。githubにコードを置いていますので、そちらも参考にしてください。
サンプルコードはGPU必須となっています。
Google Colabを使う場合は、ランタイム→ランタイムタイプの変更で、ハードウェアのアクセラレータにGPUを設定するのを忘れないように。GPUを利用しないとかなり実行時間がかかります。
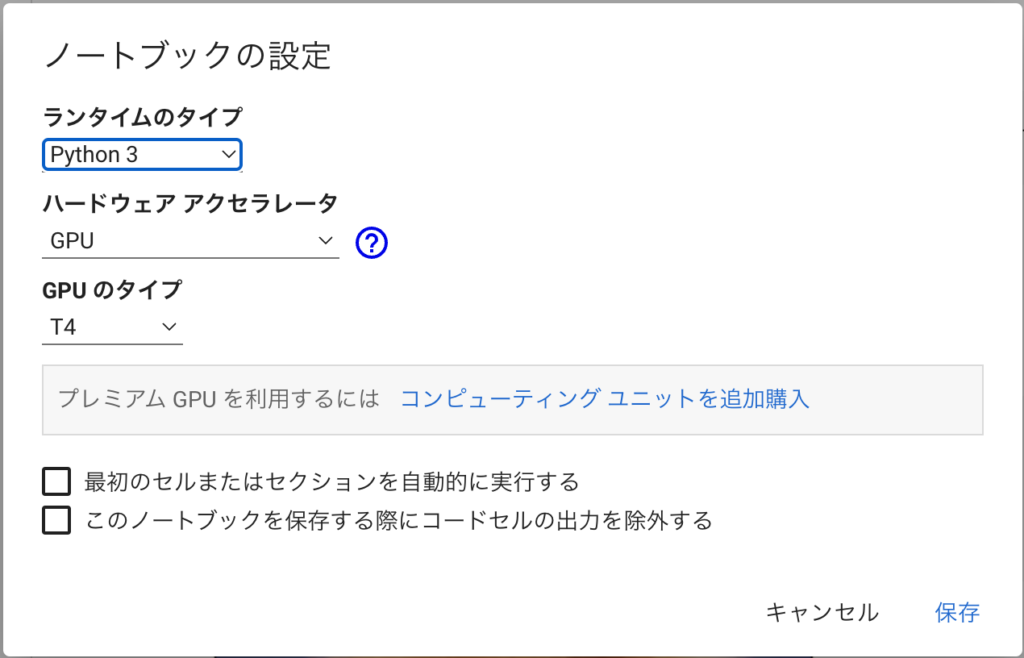
実装する分類タスクは「犬」と「猫」の2クラス分類です。
なお、ダウンロードする画像を変更することで、犬猫以外の2クラス分類も同じ要領で行うことができます。興味があったらトライしてみてください。
ここでは、処理の流れに従って説明して行きたいと思います。なお、実行環境はGoogle Colabotoryです。
timmとicrawlerはインストールされていないので、これをインストールします。Colabの場合は、以下のコードをコードに書きます(”!”がついている点に注意)
!pip install timm
!pip install icrawlerこれで、timmとicrawlerがインストールされます。
とりあえず、使いそうなライブラリをインポートしておきます。今回は、ここでインポートしていないライブラリで必要な都度インポートしてますが、最初にまとめてインポートすることをおすすめします。
import torch
import timm
import numpy as np
from icrawler.builtin import GoogleImageCrawlerまず、必要な画像データセットをダウンロードします。画像のダウンロードにはicrawlerを使います。詳しくは以下の記事を参照してください。

まず、犬の画像をGoogleから取得し、images/dogフォルダに格納します。100枚指定しますが、取得エラーなどで100枚より少なくなることがあるので注意してください。
google_crawler = GoogleImageCrawler(
storage={'root_dir': 'images/dog'})
google_crawler.crawl(keyword='dog', max_num=100)同様にして、猫の画像をimages/catフォルダに格納します。こちらも数が少ない可能性があります。
google_crawler = GoogleImageCrawler(
storage={'root_dir': 'images/cat'})
google_crawler.crawl(keyword='cat', max_num=100)
自分が実行した時は、犬が64枚、猫が63枚取得できました。
本来は、画像を確認しておかしなデータ(猫や犬ではない画像など)は削除した方が良いのですが、今回はテストということで、このまま進めます。
次に、取得した画像を訓練用(train)と、検証用(valid)に分割します。以下では、コマンドを実行して分割をしてます。以下のコードを実行すると、1〜9枚めの画像が検証用になり、それ以外が訓練用に割り振られます。
!mkdir images/train images/valid images/train/cat images/train/dog images/valid/cat images/valid/dog
!mv images/cat/00000?.jpg images/valid/cat
!mv images/dog/00000?.jpg images/valid/dog
!mv images/cat images/train
!mv images/dog images/train上記のコードを実行後、imageフォルダの内容は以下のようになります。
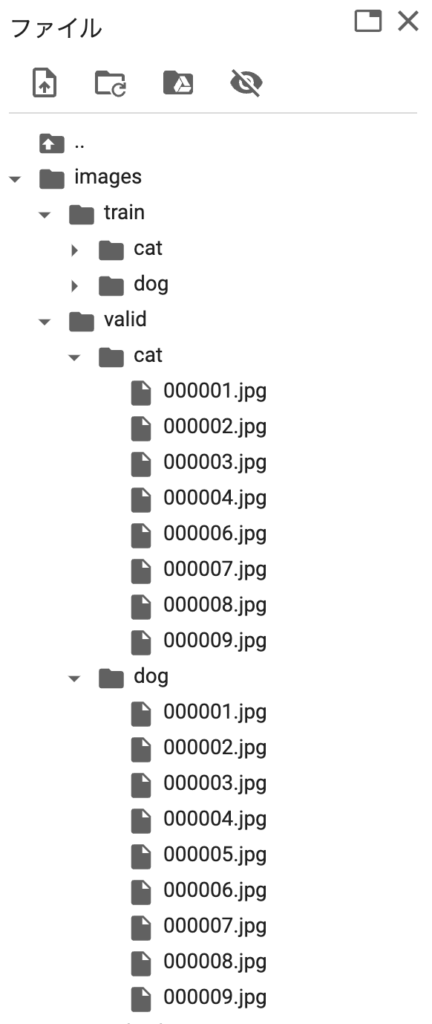
個人的には画像の準備が一番面倒
画像を準備してしまえば、あとは定形処理です。まずデータセットを作成します。次にデータローダーを作成します。クラス分離の場合は、上記のようなフォルダ構成にしておけば、timmを使って簡単に記述することができます。
まず、必要なライブラリをインポートします。下記では、create_transformもインポートしていますが、今回は使いません。興味があったら、調べてみてください(参考リンク)。
本来はデータ拡張(変形・色調変更、ランダムな切り出しなど)も行うのですが、今回は省略します。これらを行う場合であっても、timmではcreate_transformを使って簡単に実装できます。
from timm.data import create_dataset, create_loader
from timm.data.transforms_factory import create_transformまず、データセットを作成します。引数は、データセットの名前、rootは画像のルートフォルダ、class_mapはクラス名→番号への変換辞書です。今回は、訓練用データを./images/trainに、評価用データを./images/validに格納しているので、rootにはそれを指定します。また、class_mapにはdog=0, cat=1への変換を指定します。class_mapを指定することで、それぞれのフォルダにクラス番号が割り振られます。
dataset_train = create_dataset('train', root="./images/train", class_map={'dog':0, 'cat':1})
dataset_valid = create_dataset('valid', root="./images/valid", class_map={'dog':0, 'cat':1})以下は、データセットの画像の確認コードサンプルです。このようにして、画像表示とラベル確認ができます。
import matplotlib.pyplot as plt
img, label = dataset_train[0]
plt.imshow(img)
label次にデータローダの定義です。こちらもcreate_loaderを使って簡単に実装できます。input_sizeには、入力データのサイズを設定します(画像データが設定値と異なる場合は、自動で調整が行われます)。batch_sizeは、一度に読み出すサイズ(バッチサイズ)を指定します。is_trainingは、訓練用データかどうかを示すフラグでTrueにすると訓練用データになり、画像の順番のシャッフルなどが行われます。
dataloader_train = create_loader(dataset_train, input_size=(3,224,224), batch_size=16, is_training=True)
dataloader_valid = create_loader(dataset_valid, input_size=(3,224,224), batch_size=8, is_training=False)以下はデータローダの動作確認コードです、画像(バッチサイズ枚)がXに、ラベルがyに入力されます。ここでは、画像を表示すると大変なので、ラベルyのみ表示しています。
# 確認
for X, y in dataloader_valid:
print(y)以上でデータセットの準備は完了です。
次に、pytorchとtimmを使ってモデルを作成します。モデルの作成ではResNetやEfficientNetなどのアーキテクチャを選択し、最終層の出力次元をターゲットに合わせて設定します。また、pretrained=Trueにすると、学習済モデルが存在する場合はパラメータがダウンロードされ設定されます。特に、Falseにする必要がないのであれば、pretrained=Trueを設定しておくのが良いかと思います。
今回は、比較的規模の小さいresnet18を選択しました。また、2クラス分類なのでnum_classes=2を設定しています。timmでは、num_classesを設定すると最終層の出力を自動で調整してくれるので便利です。他にも入力チャネル数を変更したり(例えば、グレースケールにしたり)、特徴量抽出の部分だけ取り出したり、色々設定することができます。
model = timm.create_model('resnet18', pretrained=True, num_classes=2)ベースモデルを変更するには、'resnet18'の部分を変更します。例えば、'resnet50'にするとモデルがresnet50になります。たったこれだけです。

利用できるモデルを知りたい場合は、timm.list_models()を実行すると一覧を取得できます。
timm.create_model()で作成したモデルに自作のネットワークを繋げて、独自のモデルを定義することが可能です。timmを使うとバックボーンを色々試すのに便利なのです。create_model()については、こちらの記事を参考にしてください

パラメータ設定をしておきます。今回のコードでは、epoch数と、deviceだけです。deviceは、create_loaderがGPUが存在する前提となっているので、”cuda“に固定しています。
epoch数はとりあえず、10に設定しました。
num_epochs = 10
device = "cuda"GPUかCPUかを判定して切り替えを行う場合は、以下のコードを使います。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")その場合は、create_loaderを使わずに、torchのDataLoaderを使います(引数などが異なります)。
最初に、最適化アルゴリズム(optimizer)と、損失関数(loss_fn)を設定します。一般的な損失関数としては、クロスエントロピーが使われます。最適化アルゴリズムとしては、Adamなどが一般的です。
modelをデバイスにロードしたあと、epoch数分以下を繰り返します。
訓練では、各エポックごとに、データローダーからデータを取得し、順伝播と逆伝播(loss.backword())を行い、損失を計算します(loss_fn())。オプティマイザを使用してパラメータを更新(optimizer.step())し、全体の損失を計算します。
なお、train_loss、eval_lossは、ループ回数で割った方が良いのでしょうか、指標として表示しているだけなのでとりあえず、加算しただけで表示しています。
本来は、validのlossが最も小さくなったepochの結果を保存して利用したりしますが、今回はepoch数繰り返した結果を使います。そういう意味では、評価は学習ループでやらなくても良かったりします。
from tqdm import tqdm
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
loss_fn = torch.nn.CrossEntropyLoss()
model.to(device)
for epoch in range(num_epochs):
print("EPOCH", epoch)
model.train()
train_loss = 0
for batch in tqdm(dataloader_train):
inputs, targets = batch
outputs = model(inputs.to(device))
loss = loss_fn(outputs, targets)
train_loss += float(loss.detach().cpu())
loss.backward()
optimizer.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
for batch in tqdm(dataloader_valid):
inputs, targets = batch
with torch.no_grad() :
outputs = model(inputs.to(device))
loss = loss_fn(outputs, targets)
eval_loss += float(loss.detach().cpu())
print("train_loss = ", train_loss, "eval_loss = ", eval_loss)
訓練の時はmodel.train()を、評価の時はmodel.eval()をすることを忘れないようにします。あと、with torch.no_grad()はやっておいた方が良いです。
学習が終わった後、評価データを使用してモデルの評価結果を出力します。outputsは1枚の画像に対して2つの値(犬と猫のスコア)が入っているため、argmax()関数を使って犬と猫のスコアがより大きい方のインデックスを選択し、それをy_predとして格納します。これと真値(y_gt)を比較することで評価、正解率などを算出することができます。
model.eval()
y_pred = []
y_gt = []
for batch in tqdm(dataloader_valid):
inputs, targets = batch
with torch.no_grad() :
outputs = model(inputs.to(device))
y_gt += targets.tolist()
y_pred += outputs.argmax(axis=1).tolist()
ダウンロードされた画像によって結果が異なります。実際に、何度か実行してみましたが、ダウンロードされた画像が変化すると結果も変化しました。
y_pred、y_gtを使って、評価指標を計算してみます。これには、scikit-learnを利用します。まず、評価関数(confusion_matrix, accuracy_score, recall_score, precision_score, f1_score)をインポートします。
from sklearn.metrics import confusion_matrix, accuracy_score, recall_score, precision_score, f1_scoreあとは、それぞれの関数を呼び出すだけで指標の計算を行うことができます。
confusion_matrix(y_gt, y_pred)acc, recall, prec, fs = accuracy_score(y_gt, y_pred), recall_score(y_gt, y_pred), precision_score(y_gt, y_pred), f1_score(y_gt, y_pred)
print(f"acc={acc}, recall={recall}, precition = {prec}, f-score={fs}")それぞれの指標に関しては、以下などが参考になります。
間違った画像は以下のコードで確認できます。
for idx, (x, y) in enumerate(zip(y_pred, y_gt)):
if x != y :
img, label = dataset_valid[idx]
plt.imshow(img.transpose(1,2,0))
plt.show()少ないエポック数でも予想以上に学習が進んでいると感じるかもしれません。これは、pretrained=Trueで事前学習済みモデルを読み込んでいるからです。事前学習モデルは犬と猫の分類を事前に学習しているため、ここでの学習は微調整(特に、ラベルを0と1に変更する部分)が主な作業となっている可能性が大きいです。
取得した画像を見ると全て、実写でした。試しに、いらすとやの猫の絵を入力すると“cat”として認識してくれました。絵でもある程度は対応できる学習ができているようです。
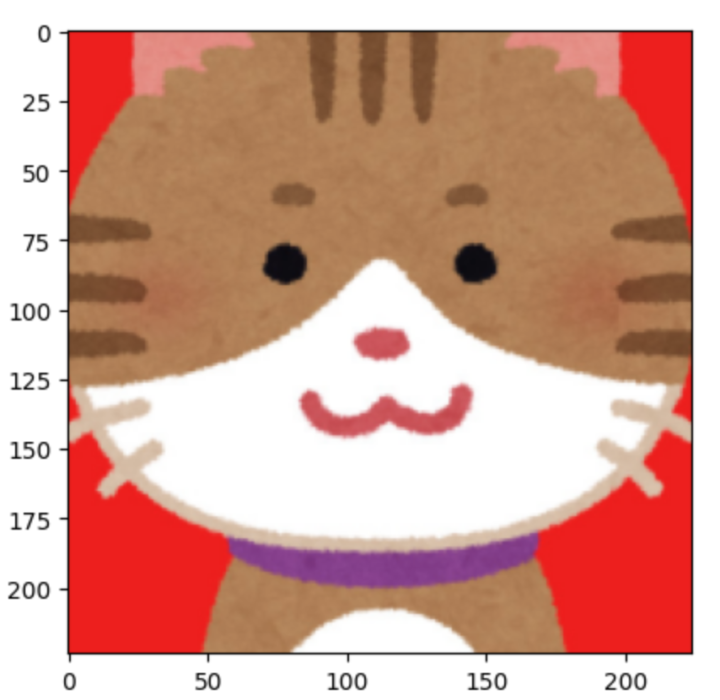
このように、pytorchとtimmを組み合わせて使用することで、簡単にディープラーニングモデルの作成と学習が行えます。今はライブラリも環境も整っていてディープラーニングもそこまで難しくありません。とりあえず、やってみるということでできますのでチャレンジしてみてください。
今回、記事のためにコードを書いてましたが、ライブラリが充実してきて本当に手軽になりました。
今回の全コードはここにあります(Google Colabotoryのノートです)。



