


物体検出用アノテーションツール「labelImg」の使い方(YOLO対応)
Aru
Aru's テクログ(Aruaru0)
YOLOv8では、物体の検出だけでなく物体追跡(Object Tracking)することも可能です。この記事では、物体検出と物体追跡の違いと、物体追跡の方法についてサンプルコードを提示しながら解説します。物体追跡タスクに興味がある方は是非読んでみてください。
YOLOv8は、Ultralytics社が開発した物体検出モデルです。物体検出以外にも色々なタスクに対応していて、セグメンテーション、姿勢推定なども可能になっています。

公式のGithubのリポジトリを見ていると、”Track“の文字があります。と言うことで、YOLOv8は物体追跡にも対応しています。

動画でオブジェクトを検出する場合、検出した物体の追跡は必須に近い機能です。YOLOでは、物体追跡についても対応しているため、動画での物体検出から追跡までを単体で行うことが可能です。今回は、物体追跡にフォーカスを当てて、動作手順を確認してみました。
物体検出(Detection)とは、画像内に存在する物体の位置や種類を特定するタスクです。一枚の静止画像に対して、「どの場所に何があるか」を識別します。たとえば、画像内に人が歩いている場合、「この場所に人がいる」と検出されます。
一方、物体追跡(Tracking)では、連続した画像(動画)内で、動く物体を追跡し、その動きや位置の変化を把握することができます。つまり、物体追跡は、動画内で特定の物体がどのように移動しているかを継続的に識別し、同じ物体がフレーム間でどの位置にいるかを把握することが可能です。
たとえば、物体検出だけでは人物が画像内の特定の位置にいることしか認識できませんが、物体追跡では、その人物がどの方向に移動したのかも追跡できます。これにより、右から左に移動する人と、左から右に移動する人を区別し、入退場者の数をカウントするアプリなどを作成することが可能です。
物体検出は瞬間、物体追跡は変化(移動)を追跡することが大きな違いです。
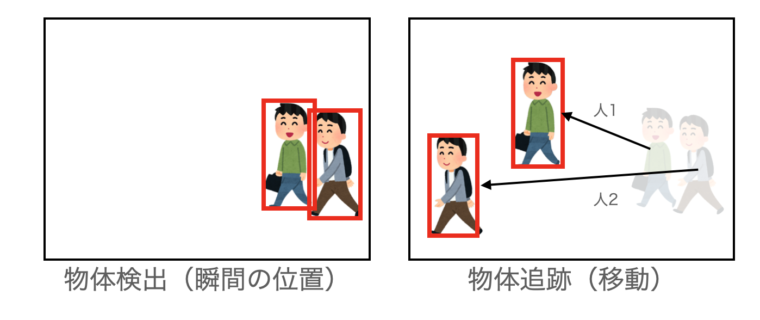

追跡を行うというこは、人1か人2かを判断する必要があり、検出よりも難しいタスクです
まずは、YOLOv8のインストールです。
Python(3.8以上)とPyTorch(1.8以上)がインストールされていれば、以下のコマンドでインストールされます。
pip install ultralytics追跡の前に、追跡するターゲットを学習させる必要があります。追跡するターゲットの学習は物体検出タスクなどで行う必要があります。学習手順については、ここでは解説しません。以下の記事を参考にしてください。

調べてみると、YOLOv8で物体追跡を行うのはかなり簡単です。
以下、サンプルです。
yolov8n.ptがなければ自動ダウンロードされるみたいなので、モデルのダウンロードも不要っぽいです。なお、独自に学習させたモデルを使う場合には、YOLO('yolov8n.pt')の部分に学習させたモデルへのパスを指定します。
PCにWebカメラなどのカメラを接続していて、OpenCVで使える状態であれば、カメラからキャプチャしながら追跡させることが可能です。コードは以下のようになります。
import cv2
from ultralytics import YOLO
# 学習済みのモデルをロード
model = YOLO('yolov8n.pt')
# 動画ファイル(or カメラ)を開く
cap = cv2.VideoCapture(0)
# キーが押されるまでループ
while cap.isOpened():
# 1フレーム読み込む
success, frame = cap.read()
if success:
# YOLOv8でトラッキング
results = model.track(frame, persist=True)
# 結果を画像に変換
annotated_frame = results[0].plot()
# OpenCVで表示&キー入力チェック
cv2.imshow("YOLOv8 Tracking", annotated_frame)
key = cv2.waitKey(1)
if key != -1 :
print("STOP PLAY")
breakファイルから動画ファイル(.mp4)を読み込んで追跡する場合は、VideoCaptureの引数をファイルパスに変更するだけです。コードは、キャプチャとほとんど同じになります。
import cv2
from ultralytics import YOLO
# 学習済みのモデルをロード
model = YOLO('yolov8n.pt')
# 動画ファイル(or カメラ)を開く
video_path = "動画ファイル.mp4"
cap = cv2.VideoCapture(video_path)
# キーが押されるまでループ
while cap.isOpened():
# 1フレーム読み込む
success, frame = cap.read()
if success:
# YOLOv8でトラッキング
results = model.track(frame, persist=True)
# 結果を画像に変換
annotated_frame = results[0].plot()
# OpenCVで表示&キー入力チェック
cv2.imshow("YOLOv8 Tracking", annotated_frame)
key = cv2.waitKey(1)
if key != -1 :
print("STOP PLAY")
breakワンポイント
model.trackのパラメータにverbose=Falseを追加すると、コンソールへのログの出力を止めることが可能です。
また、show=Trueパラメータを追加すると、cv2.imshow()で画像を表示しなくても画像を表示することが可能です。
URLを指定することで直接追跡を行うことも可能です。
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model.track(source="YouTubeの動画のURL", show=True)YOLOv8では、現在、追跡アルゴリズムとしてBoT-SORTとByteTrackをサポートしているようです。
それぞれについては、以下のURLを参考にしてください
BoT-SORT : https://github.com/NirAharon/BoT-SORT
ByteTrack : https://github.com/ifzhang/ByteTrack
一応調べた結果を別記事にしていますのでそちらも参考に

追跡方法を指定するには、track()呼び出し時にtracker=’xxx.yaml’と言う形でyamlファイルを指定します。
results = model.track(frame, tracker='xxx.yaml')xxx.yamlは、例えば以下のようになります。パラメータについては、それぞれのトラッカーのページを参照してください。トラッカーはいくつか触ったことがありますが、パラメータチューニングは結構面倒です。
BoT-SORTを利用する場合
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Default YOLO tracker settings for BoT-SORT tracker https://github.com/NirAharon/BoT-SORT
tracker_type: botsort # tracker type, ['botsort', 'bytetrack']
track_high_thresh: 0.5 # threshold for the first association
track_low_thresh: 0.1 # threshold for the second association
new_track_thresh: 0.6 # threshold for init new track if the detection does not match any tracks
track_buffer: 30 # buffer to calculate the time when to remove tracks
match_thresh: 0.8 # threshold for matching tracks
# min_box_area: 10 # threshold for min box areas(for tracker evaluation, not used for now)
# mot20: False # for tracker evaluation(not used for now)
# BoT-SORT settings
gmc_method: sparseOptFlow # method of global motion compensation
# ReID model related thresh (not supported yet)
proximity_thresh: 0.5
appearance_thresh: 0.25
with_reid: FalseByteTrackを利用する場合
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Default YOLO tracker settings for ByteTrack tracker https://github.com/ifzhang/ByteTrack
tracker_type: bytetrack # tracker type, ['botsort', 'bytetrack']
track_high_thresh: 0.5 # threshold for the first association
track_low_thresh: 0.1 # threshold for the second association
new_track_thresh: 0.6 # threshold for init new track if the detection does not match any tracks
track_buffer: 30 # buffer to calculate the time when to remove tracks
match_thresh: 0.8 # threshold for matching tracks
# min_box_area: 10 # threshold for min box areas(for tracker evaluation, not used for now)
# mot20: False # for tracker evaluation(not used for now)
トラッカーの調整には、それぞれの追跡アルゴリズムの理解が必要なるかと思います。これらについては、また別の記事にしたいと思います。
動画(.mp4)ファイルに対して追跡を行っている場合について、トラッカーの出力についても調べてみました。具体的には、以下のコードのresultsです。
results = model.track(frame, persist=True)resultsはリストです。画像を1枚づつ渡しているので、resultsは長さ1のリストとなります。なので、results[0]だけアクセスできます。
results[0]は、ultralytics.engine.results型のオブジェクトです。物体検出モデルを使った場合、物体追跡の結果は、results[0].boxesに格納されています。
以下の画像の場合、results[0].boxesは次のようになります。

ultralytics.engine.results.Boxes object with attributes:
boxes: tensor([[2.8825e+02, 1.3936e-01, 4.7949e+02, 2.2639e+02, 1.0000e+00, 3.6112e-01, 1.6000e+01]])
cls: tensor([16.])
conf: tensor([0.3611])
data: tensor([[2.8825e+02, 1.3936e-01, 4.7949e+02, 2.2639e+02, 1.0000e+00, 3.6112e-01, 1.6000e+01]])
id: tensor([1.])
is_track: True
orig_shape: (640, 480)
shape: torch.Size([1, 7])
xywh: tensor([[383.8676, 113.2671, 191.2385, 226.2555]])
xywhn: tensor([[0.7997, 0.1770, 0.3984, 0.3535]])
xyxy: tensor([[2.8825e+02, 1.3936e-01, 4.7949e+02, 2.2639e+02]])
xyxyn: tensor([[6.0052e-01, 2.1775e-04, 9.9893e-01, 3.5374e-01]])この中の、'id‘が追跡している物体のIDになります。idが同じ場合は、同じ物体として追跡していることになります。
また、物体の位置はxywh, xywhn, xyxy, xyxynに格納されています。位置の見方は、x,yが座標、w,hが幅と高さ、nが正規化されているかどうかを示しています。例えば、xywhnの場合は、x座標、y座標、幅、高さを正規化(画像の幅と高さを1.0とした値)した値であることを表しています。
なお、boxesの各要素にアクセスしたい場合は、results[0].boxes.idなどと指定します。
複数個のオブジェクトが画像内にある場合の出力は以下のようになります。オブジェクト数だけ、クラス、ID、座標などの情報が増える感じです(ちなみに、id:5は猫ですが検出結果が間違ってます😅)。
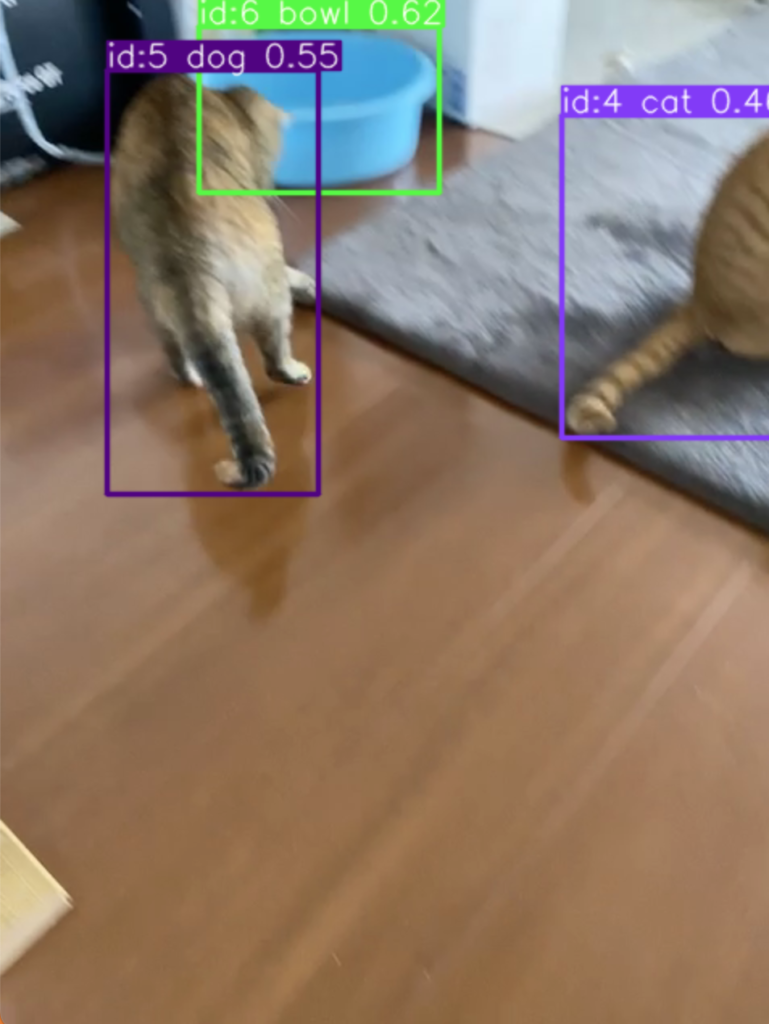
ultralytics.engine.results.Boxes object with attributes:
boxes: tensor([[3.4826e+02, 7.3290e+01, 4.8000e+02, 2.7381e+02, 4.0000e+00, 4.6047e-01, 1.5000e+01],
[6.6458e+01, 4.5299e+01, 1.9723e+02, 3.0847e+02, 5.0000e+00, 5.4958e-01, 1.6000e+01],
[1.2354e+02, 1.8989e+01, 2.7287e+02, 1.2105e+02, 6.0000e+00, 6.1618e-01, 4.5000e+01]])
cls: tensor([15., 16., 45.])
conf: tensor([0.4605, 0.5496, 0.6162])
data: tensor([[3.4826e+02, 7.3290e+01, 4.8000e+02, 2.7381e+02, 4.0000e+00, 4.6047e-01, 1.5000e+01],
[6.6458e+01, 4.5299e+01, 1.9723e+02, 3.0847e+02, 5.0000e+00, 5.4958e-01, 1.6000e+01],
[1.2354e+02, 1.8989e+01, 2.7287e+02, 1.2105e+02, 6.0000e+00, 6.1618e-01, 4.5000e+01]])
id: tensor([4., 5., 6.])
is_track: True
orig_shape: (640, 480)
shape: torch.Size([3, 7])
xywh: tensor([[414.1283, 173.5520, 131.7433, 200.5232],
[131.8447, 176.8860, 130.7730, 263.1747],
[198.2036, 70.0170, 149.3353, 102.0569]])
xywhn: tensor([[0.8628, 0.2712, 0.2745, 0.3133],
[0.2747, 0.2764, 0.2724, 0.4112],
[0.4129, 0.1094, 0.3111, 0.1595]])
xyxy: tensor([[348.2567, 73.2904, 480.0000, 273.8136],
[ 66.4582, 45.2986, 197.2312, 308.4734],
[123.5360, 18.9886, 272.8713, 121.0455]])
xyxyn: tensor([[0.7255, 0.1145, 1.0000, 0.4278],
[0.1385, 0.0708, 0.4109, 0.4820],
[0.2574, 0.0297, 0.5685, 0.1891]])追跡する動画(gifアニメーションに変換)

YOLOv8-worldモデルを使うと、学習なしで物体検出・追跡が可能になります。YOLOv8-worldについては以下の記事を参考にしてください。

Macbook Air M2のCPUで実行して48-50ms/frameでした。このスペックのCPUだと、秒20枚程度は処理できるようです。
0: 640x480 1 cat, 48.1ms
Speed: 0.8ms preprocess, 48.1ms inference, 0.4ms postprocess per image at shape (1, 3, 640, 480)また、M2のGPUを使うと10ms/frame前後になりました。YOLOv8ではMacのGPUの恩恵が結構あるようです。10msだと100fpsとなり動画の再生(デコード)が追いつかない感じでした。
0: 640x480 1 cat, 1 bowl, 1 tv, 10.5ms
Speed: 0.9ms preprocess, 10.5ms inference, 4.3ms postprocess per image at shape (1, 3, 640, 480)GPUを使う場合は、model = YOLO('yolov8n.pt').to("mps")とtoをつけるだけです。
YOLOv8で物体追跡ができることに気づいて、使い方をまとめてみました。かなり使いやすいと思います。これまでは、物体検出モデルと物体検出を組み合わせる必要がありましたが、これが統合されたと言うのは驚きです。
実は、YOLOv8と物体追跡を組み合わせてコードを書こうとしていて気づきました。ドキュメントはちゃんと読むべきですね。
ところで、動作させていて気づいたのですが、物体のクラスが変化してもIDは同じ、つまり追跡は続けているようです。このあたりの動作も調べると面白そうです。



