

超高速なゼロショットセグメンテーションモデル「FastSAM」の使い方
Aru
Aru's テクログ(Aruaru0)

pandasを使ってデータを扱う際、CSV形式での読み書きが一般的ですが、データ量が増えると速度が大きく低下します。この記事では、CSV, Pickle, Parquetという3つの代表的な保存形式について、読み書きの速度とファイルサイズの違いをベンチマークし、それぞれの特徴を比較検証しました。
Pandasでデータを保存する場合、多くの方はcsv形式を利用していると思います。ただ、データサイズが大きくなると、csvファイルは読み書きの速度が遅くなったり、ファイルが巨大化したりと色々問題が発生します。
また、csvで保存すると、データの型情報などが失われてしまうという欠点もあります。
csv以外にもいくつかのフォーマットで保存するフォーマットがあります
CSV(Comma-Separated Values)は、データをカンマで区切ったテキストファイルです。シンプルで、人間が読みやすく、多くのプログラムやツールがサポートしています
Pickleは、Pythonのオブジェクトをバイナリ形式で保存するフォーマットです。PandasのDataFrameやPythonの他のデータ構造をそのまま保存・復元できるため、データ型や構造の情報を保持します
Parquet(Apache Parquet)は、大規模なデータファイルに使用されるフォーマットの一つで、効率的なデータの保存と検索のために設計された、オープンソースの列指向データファイル形式です
使い分けのイメージはcsvは比較的小さなデータセット、Pickleはローカルで一時的に保存する場合、parquetは大規模データセットの読み書きになります。
ここでは、pickleとparquetを紹介し、csvとの比較を行いたいと思います。
ファイル形式の変更は簡単です。以下のように変えるだけです。
保存の場合
# CSVで保存
df.to_csv(file_name, index=False)
# Pickleで保存
df.to_pickle(file_name)
# Parquetで保存
df.to_parquet(file_name, engine='pyarrow')読み込みの場合
# CSVを読み込み
df = pd.read_csv(file_name)
# Pickleを読み込み
df = pd.read_pickle(file_name)
# Parquetを読み込み
df = pd.read_parquet(file_name, engine='pyarrow')pandasでcsvで保存するメリットとデメリットは以下の通りです。
csvは扱いやすいので、普段使いには良いです。ただ、データセットのサイズが大きくなると、読み込みと保存の処理時間が気になってきます。また、ファイルサイズの大きさも気になります。
pandasでpickleで保存するメリットとデメリットは以下の通りです。
pandasでparquetで保存するメリットとデメリットは以下の通りです。
pickleと似ていますが、parquetは他の言語やツールで読み込めること、互換性の問題が少ないことなどが大きなメリットです。
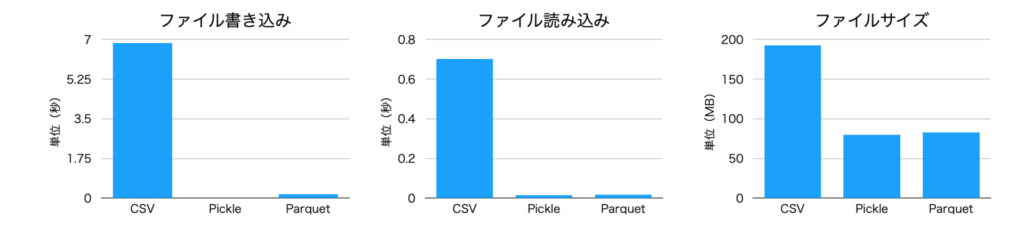
1つめは、ランダムに100万行のデータを生成し、これをそれぞれのフォーマットで保存する例です。実行は、Macbook Air(m2, 16BG)で行いました。
PARQUET - Write time: 0.1828 seconds, Read time: 0.0662 seconds
PKL - Write time: 0.0187 seconds, Read time: 0.0145 seconds
CSV - Write time: 6.8377 seconds, Read time: 0.7029 secondsそれぞれの、書き込み、読み込み速度とファイルサイズを比較したものです。ランダムデータの場合、pickleとparquetのファイルサイズはほぼ同じになりました。
また、あらかじめ予想していた通り、読み込み、書き込み、ファイルサイズの全てに関して、CSVがもっとも悪い結果となります。
| 書き込み速度(秒) | 読み込み速度(秒) | ファイルサイズ(byte) | |
| CSV | 6.8377 | 0.7029 | 192701708 |
| Pickle | 0.0187 | 0.0145 | 80000777 |
| Parquet | 0.1828 | 0.0662 | 82805172 |
import pandas as pd
import numpy as np
import time
# DataFrameを自動生成
def generate_large_dataframe(rows=1_000_000, cols=10):
"""ランダムデータを含むDataFrameを生成する"""
data = np.random.rand(rows, cols)
columns = [f'col_{i}' for i in range(cols)]
df = pd.DataFrame(data, columns=columns)
return df
# ベンチマーク関数
def benchmark(df, file_prefix='benchmark'):
formats = ['parquet', 'pkl', 'csv']
results = {}
# 各形式での書き出しと読み込みを計測
for fmt in formats:
file_name = f'{file_prefix}.{fmt}'
# 書き出し時間の計測
start_time = time.time()
if fmt == 'parquet':
df.to_parquet(file_name, engine='pyarrow')
elif fmt == 'pkl':
df.to_pickle(file_name)
elif fmt == 'csv':
df.to_csv(file_name, index=False)
write_time = time.time() - start_time
# 読み込み時間の計測
start_time = time.time()
if fmt == 'parquet':
df_loaded = pd.read_parquet(file_name, engine='pyarrow')
elif fmt == 'pkl':
df_loaded = pd.read_pickle(file_name)
elif fmt == 'csv':
df_loaded = pd.read_csv(file_name)
read_time = time.time() - start_time
# 結果を保存
results[fmt] = {'write_time': write_time, 'read_time': read_time}
return results
# 大きなDataFrameを生成
df = generate_large_dataframe()
# ベンチマークの実行
results = benchmark(df)
# 結果の表示
for fmt, times in results.items():
print(f"{fmt.upper()} - Write time: {times['write_time']:.4f} seconds, Read time: {times['read_time']:.4f} seconds")
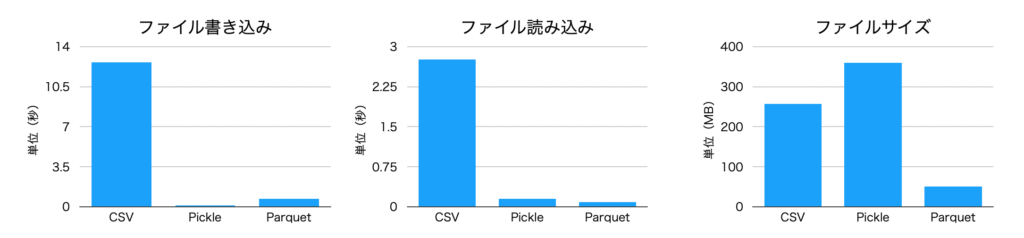
もう1つは、公開データを使ったサンプルです。ここでは、yellow_tripdata_2022-01というデータを利用しました。実在するデータなので、より実情に近い結果になるかと思います。
ちなみに、今回利用したデータは2463931 rows x 19 columnsという約240万行のデータになります。
Benchmark Results:
CSV - Write Time: 12.6214 seconds, Read Time: 2.7638 seconds
PARQUET - Write Time: 0.7002 seconds, Read Time: 0.0858 seconds
PKL - Write Time: 0.1175 seconds, Read Time: 0.1504 seconds書き込み速度、読み込み速度の傾向は同じですが、こちらの場合はファイルサイズはpickleが最も悪い結果になりました。これは、データに色々な型が含まれているためだと思われます。
大規模データセットに向いていると言われているparquetについては、ファイルサイズも読み出し・書き込み速度も良好です。
しかしならが、CSVの書き込み12秒というのはかなり遅く感じます。大規模なデータセットではCSVは避けた方が良さそうです。
| 書き込み速度(秒) | 読み込み速度(秒) | ファイルサイズ(byte) | |
| CSV | 12.6214 | 2.7638 | 257614015 |
| Pickle | 0.1175 | 0.1504 | 359669629 |
| Parquet | 0.7002 | 0.0858 | 50812828 |
import pandas as pd
import time
import requests
from pathlib import Path
# データのダウンロード
def download_data(url, file_name):
response = requests.get(url)
with open(file_name, 'wb') as f:
f.write(response.content)
# ベンチマーク関数
def benchmark(file_format, df, file_name):
# 書き出し
start_time = time.time()
if file_format == 'csv':
df.to_csv(file_name, index=False)
elif file_format == 'parquet':
df.to_parquet(file_name, index=False)
elif file_format == 'pkl':
df.to_pickle(file_name)
write_time = time.time() - start_time
# 読み込み
start_time = time.time()
if file_format == 'csv':
df_read = pd.read_csv(file_name)
elif file_format == 'parquet':
df_read = pd.read_parquet(file_name)
elif file_format == 'pkl':
df_read = pd.read_pickle(file_name)
read_time = time.time() - start_time
return write_time, read_time
# データの準備
def load_data(file_name):
return pd.read_parquet(file_name, engine='pyarrow')
# ダウンロードURLとファイル名の設定
data_url = 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet'
csv_file_name = 'yellow_tripdata_2022.parquet'
# データのダウンロード
print("Downloading data...")
download_data(data_url, csv_file_name)
# データフレームの読み込み
df = load_data(csv_file_name)
# ベンチマーク実行
file_names = {
'csv': 'nyc_taxi_data.csv',
'parquet': 'nyc_taxi_data.parquet',
'pkl': 'nyc_taxi_data.pkl'
}
results = {}
for file_format in file_names:
print(f"Testing {file_format} format...")
write_time, read_time = benchmark(file_format, df, file_names[file_format])
results[file_format] = {'write_time': write_time, 'read_time': read_time}
# 結果の表示
print("\nBenchmark Results:")
for file_format, times in results.items():
print(f"{file_format.upper()} - Write Time: {times['write_time']:.4f} seconds, Read Time: {times['read_time']:.4f} seconds")
csvはテキストファイルで保存されるので、ポータビリティが高く、またexcelなどのツールでデータが確認しやすくて良いのですが、大規模データでは、読み込み・書き込み速度が遅くなってしまいます。また、保存ファイルのサイズが大きくなるのも気になります。
pandasを使っていて、ファイルのアクセスが遅いと感じる場合は、データをparquetに変換して保存しておくと良いかもしれません。



