
大規模言語モデル(LLM)パラメータ「temperature, top_k, top_p」について【初級 深層学習講座】
データ拡張(data augmentation)手法のmixupを解説|Pytorchでの実装方法【初級 深層学習講座】

Aru
この記事では、データ拡張(データオーグメンテーション)の1つであるmixupについて解説します。mixupは、訓練データをブレンドすることでデータの多様性を高める手法で、モデルの汎化性能を向上させるのに有効な技術です。「mixupってどう実装すればよいの?」という方も多いと思います。PyTorchを例に実装方法も紹介していますので参考にしてください。
Mixupとは
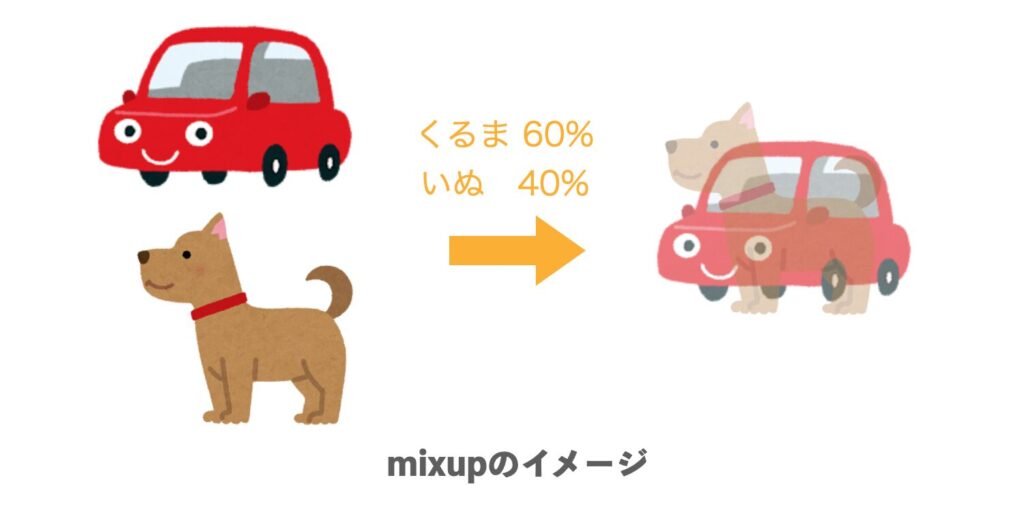
Mixupは、ディープラーニングのデータ拡張(Data Augmentation)手法の1つです。
この手法では、異なる入力データのペアをブレンディングすることでトレーニングデータを生成します。
具体的には、Mixupでは2つの入力データを合成し、それに対応するラベルに関しても一定比率でブレンドします。
データ拡張としてMixupを利用することで、モデルが汎化された特徴を学習することができ、精度向上や汎化性能アップが期待できます。
まとめると、mixupの手順は以下のようになります。
Mixupの実行手順
- ランダムに2つのデータを選択
- 選択したデータを一定比率でブレンド
- ブレンドした比率に合わせて、正解ラベルもブレンド
なお、Mixupを行う場合は、正解ラベルもブレンドします。これを実現するために、正解ラベルは数値ではなく、one-hotエンコーディングを使う必要があります。なお、PyTorchの損失関数はone-hotエンコーディングもOKなものが多いので、one-hotエンコーディングにしなければならない点はあまり問題になりません。
Mixupの実装方法
以下、mixupの実装を具体的に行っていきます。ポイントは、「ブレンドする画像をどのように選択するか」になります。
実装方針
今回は、訓練(train)ループ内にmixupの処理を実装することを考えます。
一般的に、訓練では、いくつかの訓練画像を1バッチとして束ねて入力します。
1つのバッチ処理に含まれる画像間でブレンディングを行えば、mixupは比較的簡単に実装することが可能です。
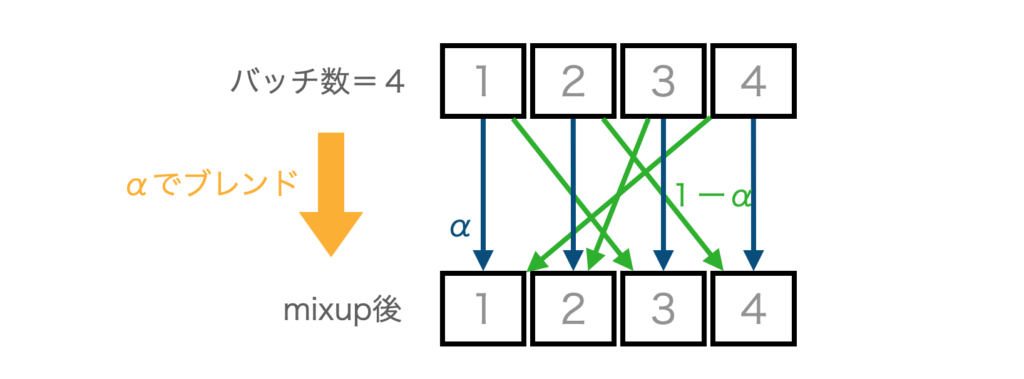
下図は、バッチ数=4の場合のイメージ図です。図のようにデータローダーで取り出したバッチ内で2つを選んでブレンドします。
このようにすることで、データセット等には特に手を加えることなく、訓練のループだけで、ブレンドを完結させることが可能になります。

バッチ内の画像をシャッフルし、バッチ内のブレンド率を同じにすることで、mixupの実装はかなり楽になります。「なんだか実装が難しそう」と思った方もいるかもしれませんが、このような実装の制限をかけることで手軽に実装可能です。
mixupを行う関数
以下がmixupの関数の基本形になります。ほとんどの場合、このままで利用することが可能です。
なお、入力は(バッチ数、入力データ)、ラベル(targets)は、(バッチ数、ラベル)となっている前提になります。
入力はtorchのテンソルで、出力もテンソルです。
以下のプログラムをコピペして使えます
import torch
import numpy as np
def mixup(data, targets, alpha):
idx = torch.randperm(data.size(0))
data2 = data[idx]
targets2 = targets[idx]
a = torch.FloatTensor([np.random.beta(alpha, alpha)])
data = data * a + data2 * (1 - a)
targets = targets * a + targets2 * (1 - a)
return data, targets
以下、処理について簡単に説明します。
torch.randperm
randperm(n)とすると、0からn-1までの順列が作成され、ランダムに並び替えたものを返します。たとえば、randperm(4)とすると、[0,1,2,3]をランダムに並べ替えた[1,0,2,3]や[3,1,0,2]などを生成できます。これを、mixupするデータのラベルとして利用します(図の緑の線)。
data2 = data[idx], targets2 = targets[idx]data2 = data[idx]
idx順に並べ替えたデータとラベルを作成します。
ブレンド率を計算
a = torch.FloatTensor([np.random.beta(alpha, alpha)])で、ブレンド率を計算します。
データとラベルをブレンド
あとは、aで2つのデータとラベルをブレンドします。
以上で、mixupしたデータが生成できます。
ライブラリを使ってmixupをする方法はこちら

timmを使ってMixup/CutMixを手軽に実装する方法
クラス分類での利用例
クラス分類でmixupを行う例です。クラス分類の場合、正解ラベルは番号で渡すことが多いですが、mixupを行う場合はone-hotエンコーディングする必要があります。
以下、クラス分類でmixupを行う場合の変更手順を解説します。
One-hotエンコーディングについては以下の記事を参考にしてください。

Category Encodersでカテゴリ変数を簡単に数値化する方法【pandas】
mixup導入前
mixup導入前は、入力x、モデルの出力y、正解ラベルgtを以下のフォーマットで受け取るとします(正解のクラス数は5とします)。
x(バッチ数、10)y(バッチ数、5)gtバッチ数分の正解のラベル
この場合、lossの計算は以下のようになります。
loss = torch.nn.CrossEntropyLoss()
num_batch = 5
num_classes = 5
x = torch.rand(num_batch, 10)
y = model(x)
gt = torch.tensor([0,1,2,3,4])
l = loss(y, gt)
print(x)
print(y)
print(gt)
print("loss = ", l)y=model(x)の部分は、ディープラーニングの任意のモデルです。xを入力して推論結果yを出力します。gtは正解データで、正解ラベルがバッチ数分格納されています(例では0,1,2,3,4)。
最後にlossを計算して出力しています。
tensor([[0.9094, 0.9565, 0.8029, 0.9986, 0.9947, 0.9011, 0.3962, 0.2622, 0.7984,
0.2864],
[0.7416, 0.3871, 0.7212, 0.8269, 0.5768, 0.8919, 0.5982, 0.4196, 0.0349,
0.3380],
[0.0159, 0.6655, 0.8890, 0.1865, 0.4994, 0.9143, 0.4286, 0.3189, 0.8076,
0.9982],
[0.1300, 0.7990, 0.2484, 0.3138, 0.6322, 0.3448, 0.4460, 0.5028, 0.4649,
0.0831],
[0.5195, 0.2599, 0.7780, 0.2039, 0.9724, 0.2166, 0.1073, 0.1946, 0.2299,
0.6623]])
tensor([[5.1615e-01, 3.5663e-01, 4.2628e-01, 8.7537e-01, 5.0648e-01],
[4.1570e-01, 4.4334e-01, 9.6814e-01, 2.5269e-01, 7.3517e-02],
[2.5309e-01, 8.6457e-01, 2.3073e-01, 7.4296e-01, 6.0217e-01],
[8.1471e-01, 2.3754e-01, 9.9684e-01, 7.9082e-01, 7.0216e-01],
[1.1082e-01, 3.4148e-04, 3.2727e-01, 4.3144e-01, 7.7219e-01]])
tensor([0, 1, 2, 3, 4])
loss = tensor(1.6002)one-hotに変更
上記のプログラムのgtをone-hotエンコーディングに書き換えます。
CrossEntropyLossは、2つ目の引数(正解ラベル)をone-hotエンコーディングしていても入力することが可能です。
下記のプログラムを動作させると推論結果yと、one-hotエンコーディングされた正解ラベルgt2を用いてloss計算が行われます。
loss = torch.nn.CrossEntropyLoss()
num_batch = 5
num_classes = 5
x = torch.rand(num_batch, 10)
y = model(x)
gt = torch.tensor([0,1,2,3,4])
gt2 = torch.nn.functional.one_hot(gt).to(torch.float)
l = loss(y, gt2)
mixupを追加
one-hotエンコーディングされた正解ラベル(gt2)と、入力データ(x)が準備できたので、mixup関数を呼び出すことができます。mixupの出力は、合成したデータ(xd)と正解ラベル(gtd)です。
loss = torch.nn.CrossEntropyLoss()
num_batch = 5
num_classes = 5
x = torch.rand(num_batch, 10)
gt = torch.tensor([0,1,2,3,4])
gt2 = torch.nn.functional.one_hot(gt, num_classes).to(torch.float)
xd, gtd = mixup(x, gt2, 0.5)
y = model(x)
l = loss(y, gtd)mixupを訓練ループに組み込む手順をまとめると、以下になります。
trainループにmixupを追加する方法
- ラベルをone-hotエンコーディングする
mixupを呼び出して、合成したデータとラベルを生成- モデルに入力
- 損失を計算(loss計算)
上記のようにloss関数はそのまま使うことが可能です。
まとめ
データ拡張の一種のmixupについてPytorchのコードを交えながら解説しました。実装自身簡単で、精度向上も期待できます。



ディープラーニングに関する記事一覧はこちら

ディープラーニング関連の記事一覧
ABOUT ME

専門分野は並列処理・画像処理・機械学習・ディープラーニング。プログラミング言語はC, C++, Go, Pythonを中心として色々利用。現在は、Kaggle, 競プロなどをしながら悠々自適に活動中



