1対Nの高速な顔認証をFaceNetとFaissを使って実装する方法|PyTorch
Aru
Aru's テクログ(Aruaru0)

この記事では、「ディープラーニングにはハイメモリがおすすめ」というテーマで、Google Colab Proを最大限に活用する方法を解説します。ハイメモリを使用することで、モデルの学習時間を短縮し、コンピューティングユニットを節約することが可能です。Google Colab Proを有効活用したい方に役立つ、実践的な情報です。
Google Colab Pro, Colab Pro+を契約すると、ランタイムを選択することができるようになります。この記事では、実際にディープラーニングに活用する場合のランタイムの選択について説明します
有料契約すると、24時間までノートブックを実行できるようになりますし、切断されにくくなります。また、Colab Pro+ではバックグランド処理をサポートしているので、ノートブックを閉じても実行を続けてくれます。
私の場合、kaggleのコンペで活用していますが、ハイメモリのランタイムがかなり有効なことに気づきました。この記事では、ハイメモリがなぜ有効なのかについて、実験結果を交えて解説します。
処理の完了と同時に切断したい場合は、こちらの記事を参考にしてください

解約時に余った期間やコンピューティングユニットがどうなるかはこちら

Colab Pro、またはColab Pro+を契約すると、ランタイム環境を選択することができるようになります。
ランタイム環境とは、クラウド上でアプリケーションやサービスが実行されるための環境のことです。Colabでは、CPUランタイム、GPUランタイム、TPUランタイムといった構成の異なるランタイムが提供されています。
具体的には、Colab Pro(Colab Pro+)では、以下のようなランタイムを選択することができます。
以下の表は、ランタイムのメモリ・ディスク・CPU数です。

実際に実行して割り当てを確認した結果ですが、公式にスペックを言っているわけではないので、変更される可能性はあります(記事は2023年10月の情報です)
| 標準(GPUなし) | ハイメモリ(GPUなし) | 標準(T4) | ハイメモリ(T4) | |
| 1時間あたりのコンピューティングユニット数 | 0.08 | 0.12 | 1.96 | 2.05 |
| メモリ | 12.7GB | 51.0GB | 12.7GB | 51.0GB |
| ディスク | 225.8GB | 225.8GB | 166.8GB | 116.8GB |
| CPU数 | 2 | 8 | 2 | 8 |
| GPU | – | – | TeslaT4(15GB) | TeslaT4(15GB) |
| 標準(TPU) | ハイメモリ(TPU) | 標準(V100) | ハイメモリ4(V100) | A100 | |
| 1時間あたりのコンピューティングユニット数 | 1.96 | 2.05 | 5.36 | 5.45 | 13.08 |
| メモリ | 12.7GB | 32.5GB | 12.7GB | 51.0GB | 83.5GB |
| ディスク | 225.8GB | 225.8GB | 166.8GB | 116.8GB | 166.8GB |
| CPU数 | 2 | 40 | 2 | 8 | 12 |
| GPU | TPU | TPU | V100(16GB) | V100(16GB) | A100(40GB) |
Pro, Pro+を契約すると、それぞれ100, 500コンピューティングユニットが割り当てられます。おおよそ、1コンピューティングユニット=10円だと考えれば良いです。
ランタイム環境は、ハイスペックなものを選べば選ぶほど1時間あたりのコンピューティングユニットの消費が大きくなります。現状最もGPUの性能が高いA100の場合、1時間で130円くらいのコストがかかります。
ディープラーニングで学習を行う場合、数時間かかることは普通なのでA100を使うとあっという間に割り当てがなくなってしまいます。
とはいっても、生成AIのようにGPUメモリが必要なモデルの学習はA100を使わざるおえないこともありますが(A100はVRAMが40GB)。
とはいえ、普段使う場合は、GPUはT4になるのではないかと思います。
ハイメモリはメモリの割り当てが多いランタイムですが、調べてみるとCPU数も増えていることがわかりました。また、GPUではなくTPUのランタイムでは、CPU数が40と突出して多いこともわかりました。
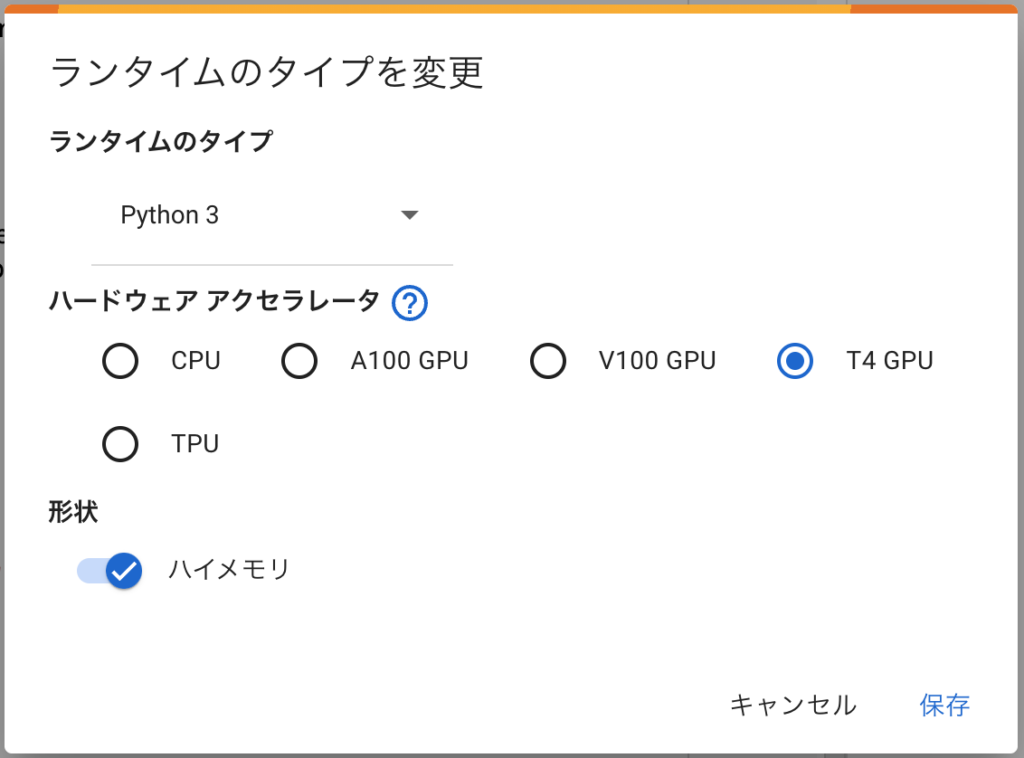
ちなみに、ランタイムの変更は、Colabの「ランタイム」メニューから「ランタイムのタイプを変更」を選択して表示される下記のメニューから行います。
ここから本題です。
結論から言えば、「メモリが必要なくてもランタイムはハイメモリがおすすめ」と言うことです。
理由は、CPU数の増加です。
たとえば、T4のランタイムではCPU数が2から8にアップします。
ディープラーニングはGPUを使うのでCPUはそれほど関係ないだろうと思われる方もいるかもしれませんが、それは間違いです。
たとえば、Pytorchのデータローダー(DataLoader)では、CPU処理の並列化に対応しています(num_workersで設定)。データローダーを並列化すると、データを読み込んで加工する処理が並列化され高速化します。
この差がどれくらいあるかをYOLOv8の学習で比較してみました。
実際に、標準(T4)と、ハイメモリ(T4)を比較して学習を行わせてみました。学習は以前紹介した記事のもので、これをColab上で実行した形になります。

以下が実行時間です。
| 標準(T4) | 14min 41s |
| ハイメモリ(T4) | 6min 42s |
ハイメモリの方は半分の時間で終わっていることがわかると思います(ハイメモリが約2倍高速)。
1時間あたりのコンピューティングユニットが、それぞれ1.96と2.05とハイメモリの方が高いですが実行時間が2倍以上短くなっているので、結果としてハイメモリの方が費用がかかっていません。
| 標準(T4) | ハイメモリ(T4) | 差分 | |
| 1時間あたりのコンピューティングユニット | 1.96 | 2.05 | +0.09(約4.5%高い) |
| 実行時間 | 14min 41s | 6min 42s | -7min59s(約2.19倍) |
| 実行にかかった費用(コンピューティングユニット) | 0.48 | 0.23 | -0.25(約50%ダウン) |
実際の計測結果はこちら
標準 CPU times: user 7min 14s, sys: 31.2 s, total: 7min 45s Wall time: 14min 41s
ハイメモリ CPU times: user 6min 10s, sys: 31.4 s, total: 6min 42sYOLOv8だけにハイメモリの効果があるわけではありません。
実は、ハイメモリの方がコスパが良いことに気づいたのは、BERTの学習を行なっていた時です。
「CPU数が多いから、もしかしてハイメモリの方が速い?」と思って試しにランタイムを変更して実行してみると、12時間以上かかっていた学習が8時間ほどに短縮されました。YOLOv8ほどではないですが、時間は短くなっているし、必要とするコンピューティングユニットも減りました。
BERTのコードもデータロード中の前処理が少しあったのですが、データの前処理などがある場合は、CPU数の増加による恩恵を得られやすいのかもしれません。
表形式のデータを機械学習する場合などは、CPU数が多いと高速に処理できることがあるのでTPUのランタイムのCPU数が40と言うのは意外と活用できるかもしれません。ただ、価格差を考えると普通のハイメモリ(0.12)の方が良いかもしれません。
ディープラーニングを行う場合は、CPUの数も速度に影響があったりします。ハイメモリと標準の価格差がわずかなので、ハイメモリを選択すると「時間も短くなって、コストも抑えられる」といいことづくめです。
Colab Proでディープラーニングを行なっている人は、ハイメモリを活用してはいかがでしょうか。



