

グラフの単純な閉路(サイクル)の距離を列挙する|Python
Aru
Aru's テクログ(Aruaru0)

SMOTE(Synthetic Minority Over-sampling Technique)は、不均衡データの少数派サンプルを合成して増やすためのオーバーサンプリング手法です。不均衡(アンバランス)なデータセットでは、モデルの予測精度が低下することが多いため、この手法が有効です。この記事では、Pythonを使ったSMOTEの実装方法について解説します。
データがクラスによって不均衡な場合には、オーバーサンプリングやダウンサンプリングなどの対策が考えられますが、ここではオーバーサンプリングの手法であるSMOTE(Synthetic Minority Over-sampling Technique)を紹介します。
例えば、yesが10%、noが90%の割合のデータセットで予測モデルを作成した場合、全てを「no」と予測すれば90%の正解率が得られるため、このようなモデルが有効になってしまう可能性があります。この極端なケースでなくても、少数派クラスに対する予測が不利になることは避けられません。これにより、モデルが実際のデータでは精度がでないと行ったことが発生します。
このような状況に対処するために、LightGBMなどのモデルではクラスの重みを設定してフィッティングすることが可能ですが、前処理の段階でデータ数を均等にする方法もあります。SMOTEは、後者の方法においてデータ数を均等にするための強力な手法です。この記事では、SMOTEの基本的な概念やPythonによる実装について解説します。

データが不均等というのは結構あります。こういう時に使う手法の1つとして覚えているおくと良いかも。
SMOTE(Synthetic Minority Over-sampling Technique)は、不均衡データセットのクラス間のサンプル数の差を解消するための一般的なオーバーサンプリング手法です。
不均衡なデータセットとは、あるクラスのサンプル数が他のクラスに比べて著しく少ないデータセットのことを指します。このような不均衡は、機械学習モデルの性能に悪影響を及ぼす可能性があります。SMOTEは、この問題に対処するために利用される手法です。
簡単に言えば、データの水増し手法になります
SMOTEでは、少ない方のサンプルに対して合成したサンプルを作成することで、各クラスのデータ数のバランスを調整します。具体的には、少数派のサンプルとその近傍のサンプルを組み合わせて新しいサンプルを作成します。これにより、少数派サンプルのデータが増加し、データセットのクラスバランスが改善されます。
以下、SMOTEの処理の流れの概要です。
SMOTEを利用する利点をまとめると以下になります
ただ、SMOTEがすべての場合に有効なわけではないことに注意が必要です。
データセットの特性や問題の性質に応じて、他のオーバーサンプリング技術やアンダーサンプリング技術の組み合わせを検討することも重要です。ここは、トライ&エラーによる試行錯誤が必要な部分です。
SMOTEは、imbalanced-learnというライブラリに組み込まれているのでこれを利用します。インストールされていない場合は、以下の手順でインストールできます。
pip install -U imbalanced-learn
実際に不均等なデータを作成して、使い方と動作の確認を行います。
今回作成するデータセットは、クラス0が100個、クラス1が1000個のデータです。
X1 = np.random.normal(1,1,200).reshape(100, 2)
X2 = np.random.normal(-1,1,2000).reshape(1000, 2)
y1 = [0 for _ in range(100)]
y2 = [1 for _ in range(1000)]
X = np.concatenate([X1, X2])
y = np.concatenate([y1, y2])
print(f"counts : class0 = {sum(y == 0)}, class1 = {sum(y == 1)}")クラス0のデータは(1,1)を中心とした標準偏差1の分布、クラス1は(-1,-1)を中心とした標準偏差1の分布で生成しています。生成した数を見ると、以下のように100:1000になっていることがわかります。
counts : class0 = 100, class1 = 1000グラフにすると、以下のようになります。
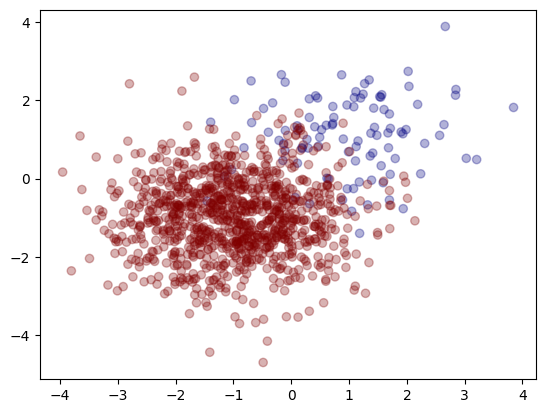
グラフを見てわかるように、圧倒的に赤点が多いです。このデータに対して、SMOTEでデータ数を増やしてみます。
コードは以下のようになります。
sm = SMOTETomek(random_state=42)
X = X.reshape(1100,2)
X_res, y_res = sm.fit_resample(X, y)
print(f"resample result : class0 = {sum(y_res == 0)}, class1 = {sum(y_res == 1)}")ライブラリの使い方は非常に簡単で、まず、SMOTETomek()でオブジェクトを作ります。次に、fit_resample()を実行するとオーバサンプリングされたデータが返されます。
なお、入力のXは説明変数、yはクラス分類になります。
今回の例では、説明変数が2つあるデータですが、説明変数がもっと多くても問題ありません(例ではグラフで視覚的に見やすくするために説明変数を2個にしました)。
処理すると、各クラスのサイズは以下のようになり、バランスが調整されたことがわかります。
resample result : class0 = 965, class1 = 965これをグラフにすると青点が増えていることがわかります。
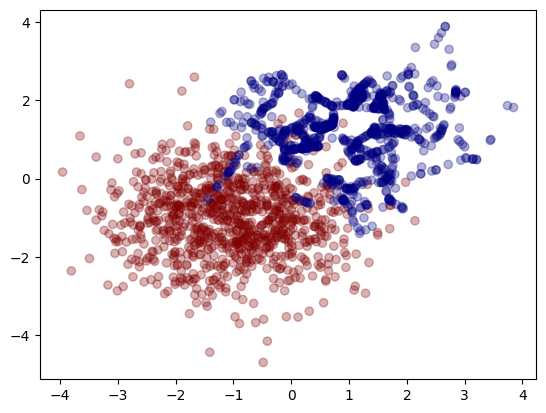
「少数派のサンプルとその近傍のサンプルを組み合わせて新しいサンプルを作成」するため、青い分布が気になるかもしれません(直線で繋がれているように見えるかもしれませんが)。とはいえ、オーバーサンプリングが実施されました。
一応、青の分布を調べてみると
XX = X_res[y_res == 0]
XX.mean(axis=0), XX.std(axis=0)(array([0.95607874, 1.19124738]), array([0.93733671, 0.88194509]))
となって、中心が(1,1)・標準偏差1の分布から少しずれている感じです(もちろん、元の分布を維持するような変換ではないので、これも仕方のないことですが)。
一方、赤は、
(array([-1.0443179, -1.025522 ]), array([1.01322938, 0.978189 ]))なので、こちらは中心(-1,-1)・標準偏差1に近い分布なっています。
ところで、PyCaretというライブラリでは、前処理でSMOTEを利用することができます。興味がある方は、以下の記事も参考にしてください。
データが不均衡であるという状況はよくあります。特に異常検知などでは、異常として分類されるデータが不足することが多いです。このような場合、SMOTEを用いたオーバーサンプリングが有効な手法となるかもしれません。ただし、SMOTEは万能な手法ではないため、精度が向上するかどうかはデータの特性による部分もあります。



