
PyTorchでモデルの演算量を確認する方法|PyTorch TIPS
Aru
Aru's テクログ(Aruaru0)

データ分析の前処理では、列に散らばったデータを行にまとめることがあります。例えば、「行方向に曜日別に並んだデータを、7日単位でまとめて1週間単位の行にしたい」といった場合や、「特定の列の要素単位で、行を集約したい」場合があります。本記事では、Pandasのshiftとgroupbyを活用して、列にまたがるデータを効率よく行に変換する方法を解説します。
データ分析では、テーブルデータをの行に並んだデータを1行にまとめたい場合があります。例えば、「1週間単位で統計情報を集計し、これを基に将来の動向を予測したい」場合などは、複数行を集計して1列にまとめる処理が必要になります。
この記事では、Pandasでテーブルデータを効率よく変形する手法について解説します。Pandasでは、groupbyやshiftを活用することで、特定の基準でデータをグループ分けしたり、データを列に変換することが可能です。

機械学習の特徴量エンジニアリングなどでよく使います。
私も頻繁に使うのでメモがわりに記事にしました。
行方向に時系列に並んだデータを、一定の個数ずつまとめて1つの行に集約する例です。
以下の図(下の左図)のような、時系列データxがあるとします。このデータでは、行が時間に相当し、xが各時間の値となります。
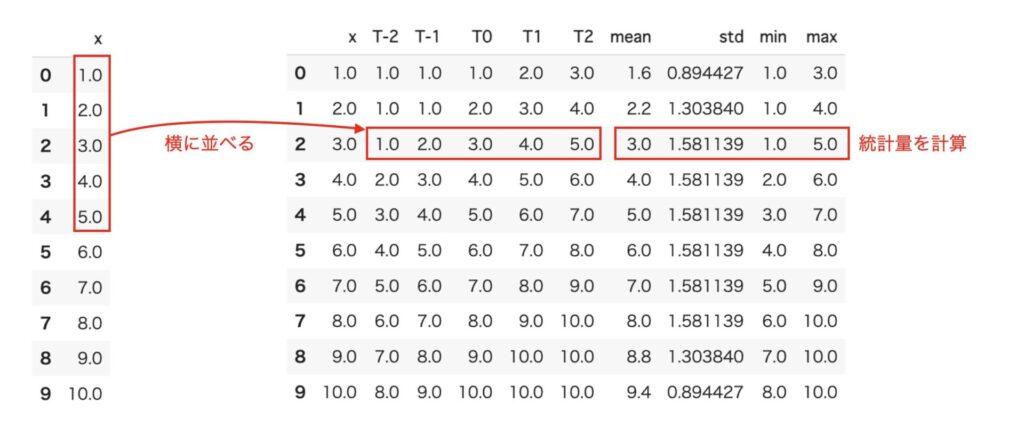
例えば、このデータを5個(現在時刻±2)の範囲でまとめて行に変換し、5個の平均・分散・最大値・最小値といった統計量を計算し、1行に集約する例を考えてみます。
データ分析では、このように1時刻ずつずらして1行に集約することが度々ありますので、変換方法を覚えておくとよいです。
サンプルのテーブルを作成します。テーブルは列xだけの簡単なものです。
import pandas as pd
import numpy as np
# サンプルのDataFrameを作成
data = {
'name': ['a', 'b', 'a', 'c', 'd', 'b', 'c', 'a'],
'val': [10.0, 20.0, 20.0, 10.0, 20.0, 4.0, 5.0, 22.0]
}
df = pd.DataFrame(data)
現在のxの値をTとして、T-2, T-1, T0, T1, T2という列を作成して追加します。T<N>の形の列はそれぞれ、-2, -1, 0, +1, +2行ずれたxの値になります。
この操作は、sfhitを使って行うことができます。shiftでは指定された分だけ行をシフトします。なお、シフトにより欠損する部分にはNaNが代入されます。
以下のプログラムは、先ほどの表に時間シフトを行った列を追加する例です。
# 前後2個選択
cols = []
for i in range (-2, 3, 1):
colname = f"T{i}"
df[colname] = df['x'].shift(-i)
cols.append(colname)range(-2, 3, 1)と指定して、-2, -1, 0, 1, 2というシフト量の値を生成し、T-2, T-1, T0, T1, T2という列名で追加しています。
埋める値はfill_valueパラメータで変更することも可能です
また、このプログラムでは列名をcolsに保存しています。これは、後で統計情報を計算するときに利用します。
shiftによりテーブルは以下のようになります。
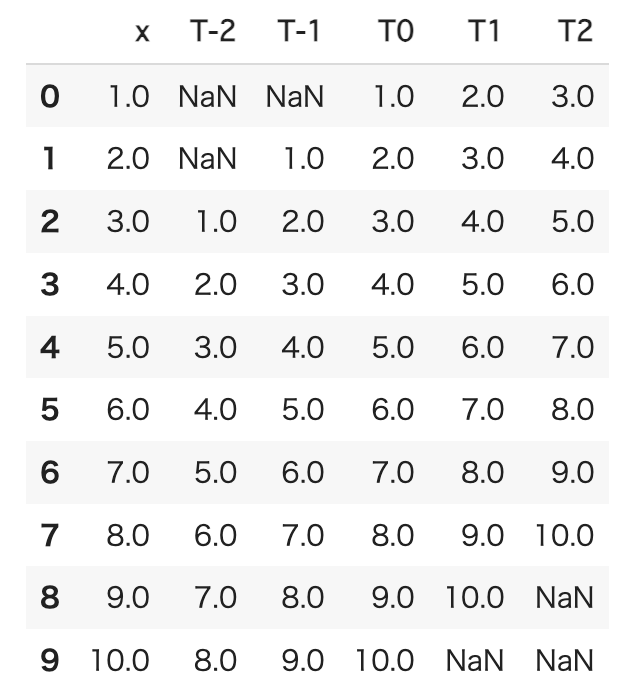
シフトによりNaNが挿入されているので、これを別の値で埋めます。
今回は、行の前後の値で埋めることにします。つまり、0より前の時刻はx[0]の値で、9より後の値はx[9]の値で埋めることを意味します。
この操作は、interpolate()を利用して行うことができます。limit_directionパラメータはbothを指定すれば、前後の値で補間され意図した結果を得られます。
limit_directionには'forward', 'backward', 'both'の3つが指定できます。
# nanを前後の値で埋める
df = df.interpolate(limit_direction = "both")補完後の結果は以下になります。これでNaNが消えました。
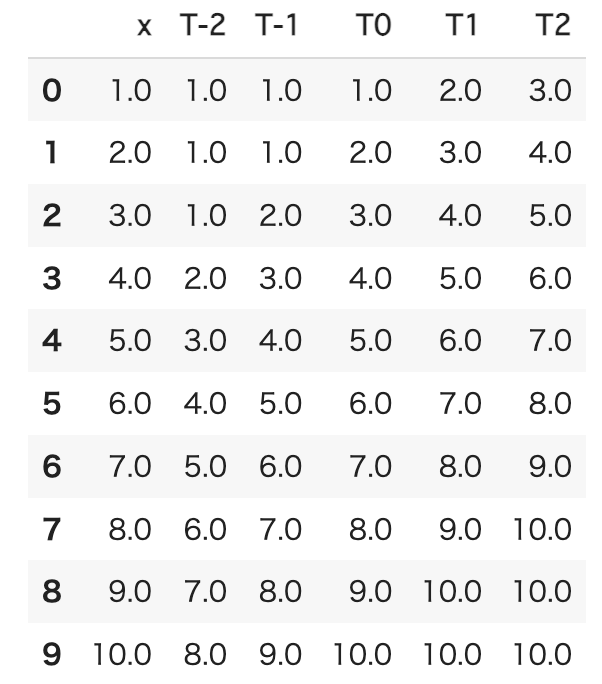
各行のT-2, T-1, T0, T1, T2の平均・分散・最小・最大を計算して列に追加します。colsに計算の対象とする列リストを保存していたので、これを利用して計算します。
# 平均、分散、最大値、最小値を追加
df['mean'] = df[cols].mean(axis=1)
df['std'] = df[cols].std(axis=1)
df['min'] = df[cols].min(axis=1)
df['max'] = df[cols].max(axis=1)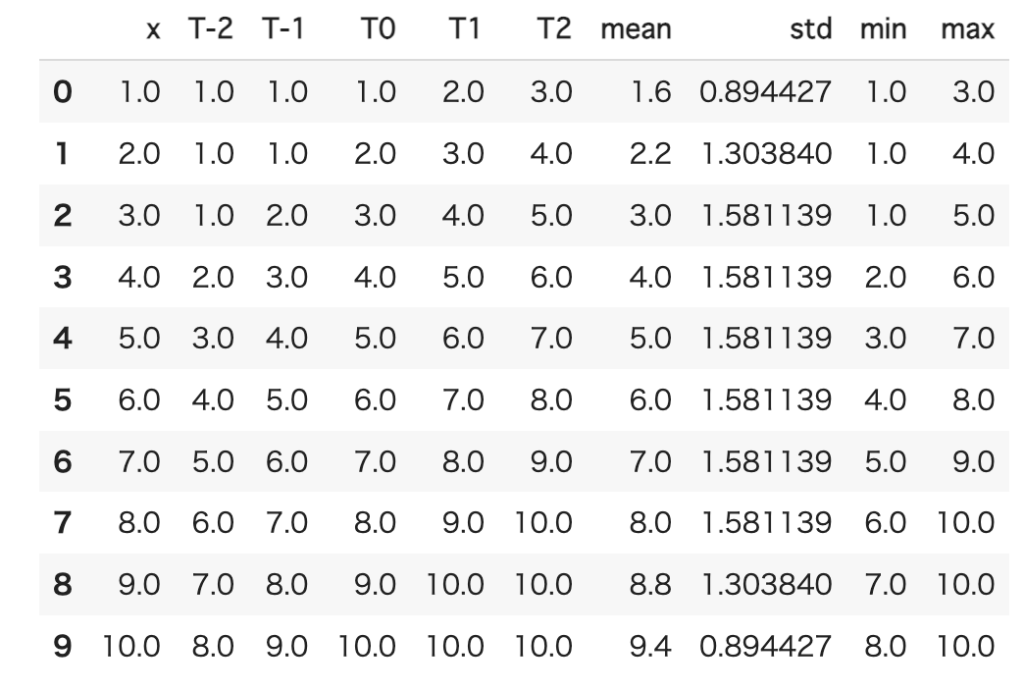
以上で、時系列で並んだxを5つずつ行にまとめて、統計情報を計算した行の作成が完了です。
この処理は、平均、分散、最小、最大を特徴量とした分析を行う場合などに重宝します。
このように変形することで時系列データを、行単位のテーブルデータとしてlightGBMなどで使って取り扱うことが可能です。意外と活用シーンは多いです。
ここでは、列の値(属性)が同じものを1つの行に集約する方法を説明します。例えば、元のデータが購買データなどで、ユーザIDと購入商品の組みを1行としているものから、ユーザ毎の購入商品群を作る場合などに利用します。
ここでは、列nameが同じvalを1行にまとめる処理を例に解説します。
nameごとに出現する行数が違いますが、足りないものにはnanを挿入する形で行にまとめます。

サンプルのテーブルを作成します。テーブルはnameとvalのあるもので、同じnameの行が複数あるものです。
例えば、売上伝票で「X日にaさんが購入した合計金額」などの情報が行で並んでいるようなものを考えるとイメージしやすいかもしれません。
この表を、nameでまとめていきます。
import pandas as pd
import numpy as np
# サンプルのDataFrameを作成
data = {
'name': ['a', 'b', 'a', 'c', 'd', 'b', 'c', 'a'],
'val': [10.0, 20.0, 20.0, 10.0, 20.0, 4.0, 5.0, 22.0]
}
df = pd.DataFrame(data)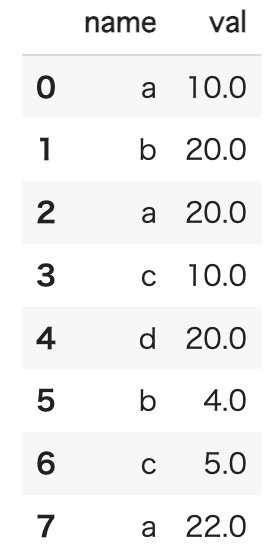
groupbyを使うと、nameでまとめることが可能です。
以下のコードでは、nameでvalをまとめて、それをlistに変換しています。
# name列を基準にグループ化し、各グループに対してval列の値を取得
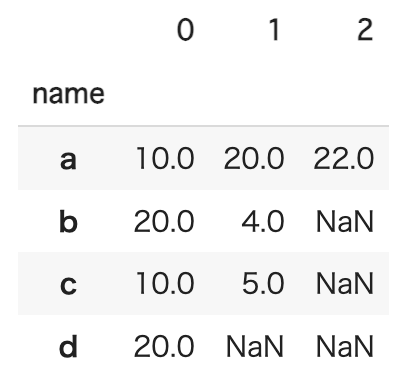
grouped = df.groupby('name')['val'].apply(list).reset_index()結果は以下のようになります。nameごとにvalがリスト型でまとめられています。

この状態のまま使うこともあります。
上記のデータから、valを分割した表を作成します。
grouped['val'].values.tolist()を実行すると、valの値がリストに変換されます。具体的には、以下のようになります
[[10.0, 20.0, 22.0], [20.0, 4.0], [10.0, 5.0], [20.0]]
これを引数としてDataFrameを作成します。
# 各グループの値をDataFrameに配置
new_df = pd.DataFrame(grouped['val'].values.tolist(), index=grouped['name'])作成されたデータフレームは以下のようになります。
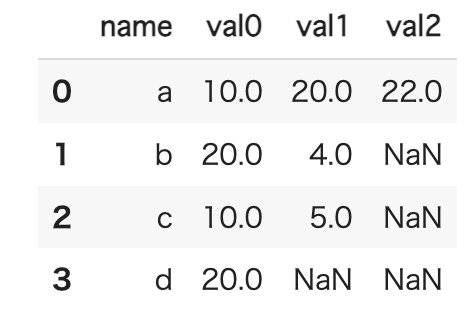
indexがnameになっているので、これを列に変換します。また、列名が0,1,2になっているのでこれもval0, val1, val2に変更します。
# 列名を設定
new_df.columns = [f'val{i}' for i in range(len(new_df.columns))]
# インデックスを列に変更
new_df.reset_index(inplace=True)これで、目的のテーブルが完成しました。
行方向に並んだデータの一部を、列方向に移動させて新しい表を作成する方法を2つ解説しました。データ分析では結構利用するテクニックなので覚えて置いて損はないと思います。



