MacBook Air M5でローカルLLMはどこまで動く?LM StudioでGemma3・Qwen3.5・gpt-ossを速度ベンチマーク
Aru
Aru's テクログ(Aruaru0)

この記事では、サウンドデータ(音や音声)をメルスペクトログラム(Mel Spectrogram)に変換してPyTorchの画像用のモデル(CNN)で学習・推論させる手順を解説します。音データもスペクトログラムに変換することで、画像と同じように処理可能です。以下では、音データの変換、トレーニング、推論のステップを詳しく解説し、音データを画像として取り扱うノウハウを紹介します。
この記事では、音声データ(サウンドデータ)をディープニューラルネットワーク(DNN)で学習・推論する方法について解説します。
実は、音声データもスペクトログラムに変換すれば画像として扱うことができ、画像用のモデルが利用できます。
画像用のモデルは多数存在しています。これらを使えるというのはかなり便利です。
以下、感情推定用の音声データセットを利用して、実際に音声データを画像に変換し、感情の学習と推定を実施します。

モデルはTIMMの既存の画像用のモデルを利用します。新たなモデルはつくりません。画像モデルを流用できる利点の1つです
音声データをディープラーニングで取り扱う参考になればと思います。
ここでは、RAVDESS Emotional speech audioというデータセットを利用します。
RAVDESSは、プロの俳優を用いて録音されたデータセットで、ニュートラル、穏やか、幸せ、悲しみ、怒り、恐怖、驚き、嫌悪の8種類の感情表現が含まれたデータセットです。
ここでは、このデータセットに含まれる音声データを利用します。
このデータセットはcurlコマンドでダウンロードすることができます。具体的には、以下のコマンドを実行します。
curl https://zenodo.org/records/1188976/files/Audio_Speech_Actors_01-24.zip?download=1 -o Audio_Speech_Actors_01-24.zipダウンロードが完了したら、dataというフォルダを作成し、unzipで、そこにデータセットを解凍します。
mkdir data
unzip -q Audio_Speech_Actors_01-24.zip -d data解凍すると、Actor_xxというフォルダが作成され中に*.wavファイルが格納されます。
このwavファイルのファイル名は以下の命名規則に沿って付けられています。
データセットの読み込みでは、このファイル名から感情ラベルを抽出します。
音声ファイルは03-01-01-01-01-01-01.wavのようなファイル名になっており、それぞれの数字は以下のような意味になります。
今回は、感情をラベルとして利用しますので、前から3番目のEmotionをラベルとして抜き出しています(後ろからみると5番目)。
必要なライブラリをインポートします。
今回は、torchaudioとlibrosaを利用します。インポートの部分は以下のようになります。
import glob
import torch, torchvision, torchaudio
import torch.nn as nn
import torch.nn.functional as F
import librosa
import random
import os
import matplotlib.pyplot as plt
import multiprocessing
import timm
from tqdm.notebook import tqdm次に、データセットを作成します。データセットでは、音声データをファイルから読み出して、メルスペクトログラム(画像)に変換しています。
詳しくは、以下の記事を参照してください
メルスペクトログラムへの変換については、以下の記事で詳しく解説しています。

librosa.loadで音声データを読み出し、trimで無音部分をカットしています。次に、y = librosa.util.normalize(y)として音量の正規化を行なっています。その後、self.secで指定される秒数分のデータを抜き出しています。
感情ラベルは、label = int(filename.split("-")[-5])-1として取り出しています。labelは、8種類の感情表現に対応して、0から7の値となります (0 = neutral, 1 = calm, 2 = happy, 3 = sad, 4 = angry, 5 = fearful, 6 = disgust, 7 = surprised)。
感情ラベルは0から7としています。元は1~8なので注意してください
self.melで音声データをメルスペクトログラムに変換しています。
最後にunsqueeze(0)をして、高さx幅のデータをデータをch(1)x高さx幅のデータに変換し、1チャネル(グレースケール)の画像データにして終了です。
以下のプログラムがデータセットの定義になります。
class AudioDataset(torch.utils.data.Dataset) :
def __init__(self, path, mode, sr=16000, hop_length=512, sec=2) :
self.files = glob.glob(os.path.join(path,"*/*"))
self.mel = torchaudio.transforms.MelSpectrogram(
sample_rate=sr, hop_length=512, n_fft=1024, f_max=sr/2, power=1) # 1 for magnitude, 2 for power
self.sr = sr
self.hop_lenght = hop_length
self.sec = sec
# データ拡張用の変換列などを定義しておく
if mode == "train" :
self.mode = 1
elif mode == "eval" :
self.mode = 2
else:
self.mode = 0
def __len__(self) :
return len(self.files)
def __getitem__(self, idx) :
filename = self.files[idx]
y, sr = librosa.load(filename, sr=self.sr)
yt, _ = librosa.effects.trim(y)
# trimして不足したら先頭yにする
if len(yt) > self.sr*self.sec : y = yt
# 正規化する(正規化した方が今回のデータでは良さそう)
y = librosa.util.normalize(y)
if self.mode == 1 or self.mode == 2 :
start = random.randint(0, len(y)-self.sr*self.sec)
else:
start = 0
y_sel = y[start:start+self.sr*self.sec]
label = None
if self.mode == 1 or self.mode == 2:
# ここで、ノイズ付加などのデータ拡張を行う
label = int(filename.split("-")[-5])-1
mel_spec = self.mel(torch.tensor(y_sel))
return mel_spec.unsqueeze(0), label今回は行っていませんが、データ拡張をすることでロバスト性を向上できます。音声データのデータ拡張についてはこちらを参考にしてください。

ハイパーパラメータなどの各種パラメータを設定し、データセット、データローダーを生成しています。
EPOCHS = 20
BATCH_SIZE = 8
NUM_CLASSES = 8
cpus = multiprocessing.cpu_count()
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
dataset = AudioDataset('data', mode="train", sec=2)
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size = BATCH_SIZE, shuffle=True, num_workers=cpus)一旦、データローダーの動作を確認してみます。
以下のコードでは、最初のバッチ分を読み出して、画像に変換された音声データを表示しています。
fig, ax = plt.subplots(2, 4, figsize=(10, 8))
for inputs, labels in train_dataloader:
for n, x in enumerate(inputs) :
i = n//4
j = n%4
ax[i][j].imshow(x[0])
ax[i][j].set_title(labels[n])
break
plt.show()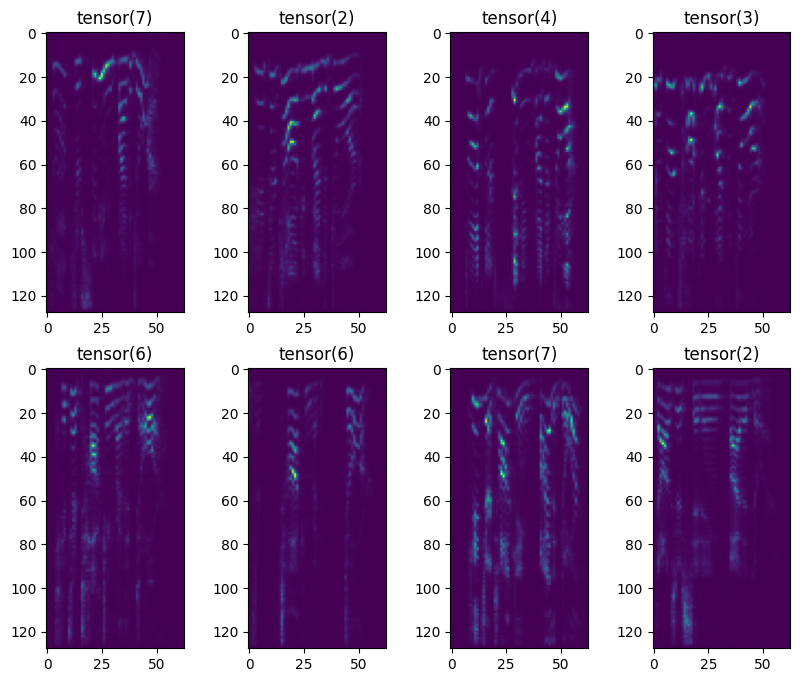
結果を見ると、データを読み出してメルスペクトログラムへ変換する処理は問題なさそうです。
モデルを生成します。今回はTIMMのefficientnet_b0を利用しています。
入力が1chなのでチャネルを1に、8分類なので8クラスを設定しています。
また、クラス分類なので損失関数にはCrossEntropyLossを指定しました。
model = timm.create_model("efficientnet_b0", pretrained=True, in_chans=1, num_classes = NUM_CLASSES).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.005)ある程度はcreate_modelの引数で調整できます。今回の場合は、新たにレイヤーを追加せずに対応できています。
TIMMの使い方については以下の記事(チートシート)を参考にしてください

以下、学習ループです。画像に変換して処理していているので、基本は画像のトレーニングループとほぼ同じです(というか、PyTorchの場合は、以下のようなループがテンプレです)。
model.train()
losses = []
acc = []
for epoch in range(EPOCHS) :
train_loss, train_acc = 0.0, 0.0
with tqdm(train_dataloader) as pbar:
pbar.set_description(f'[Epoch {epoch + 1}/{EPOCHS}]')
for inputs, labels in pbar:
optimizer.zero_grad()
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.detach().item()
preds = outputs.argmax(axis = 1)
train_acc += torch.sum(preds == labels).item() / len(labels)
pbar.set_postfix({'loss': loss.item(), "acc":torch.sum(preds == labels).item() / len(labels)})
train_loss /= len(train_dataloader)
train_acc /= len(train_dataloader)
losses.append(train_loss)
acc.append(train_acc)
print(f"epoch {epoch+1}: loss = {train_loss:.4f} acc={train_acc:.4f}")今回はエポック数を20にして学習させました。GPUを使って1エポック29秒程度でした。
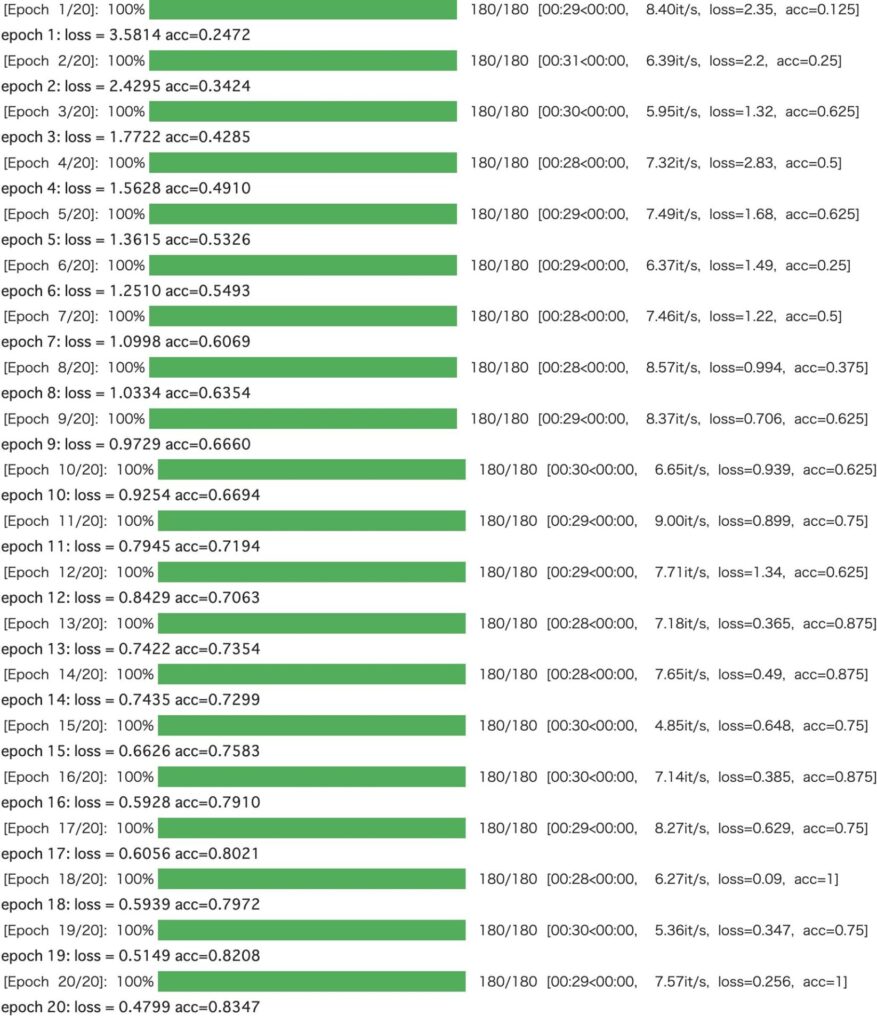
Lossをプロットしてみます。ロスをみると、まだ下がりそうな雰囲気があります。
plt.plot(losses, 'ro--')
plt.show()
精度もプロットしてみました。こちらもまだ上がりそうです。
plt.plot(acc, 'ro--')
plt.show()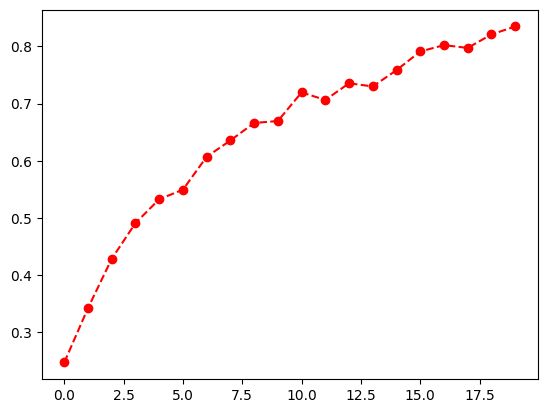
推論を試してみます。本来は学習したデータとは別のデータを用意した方がよいのですが、今回は学習したデータと同じデータを使っていますが許してください。
test_dataset = AudioDataset('data', mode="eval", sec=2)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size = BATCH_SIZE, shuffle=False, num_workers=cpus)
gt = []
pred = []
model.eval()
with tqdm(train_dataloader) as pbar:
pbar.set_description(f'[Epoch {epoch + 1}/{EPOCHS}]')
for inputs, labels in pbar:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad() :
outputs = model(inputs)
p = outputs.argmax(axis = 1)
# print(p, labels)
pbar.set_postfix({"acc":torch.sum(p == labels).item() / len(labels)})
pred += p.tolist()
gt += labels.tolist()
print("acc = ", sum([p == g for p, g in zip(pred, gt)]) / len(pred))精度は89%になりました。
acc = 0.8909722222222223混同行列も求めてみます。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(pred, gt)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=[i for i in range(8)])
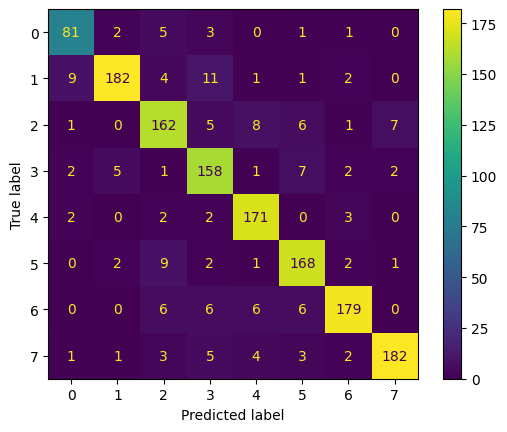
disp.plot()混同行列は以下のようになりました。どの感情も概ね正解しているようです。
音声データをディープニューラルネットワーク(DNN)で学習させる方法について解説しました。このように、メルスペクトログラムに変換することで、音声データを画像として学習できるようなり、画像用のネットワークを利用できます。
データ拡張などは画像と異なりますが、画像にしてしまえば画像と同じ手法が使えます。ちなみに、音声データだけでなく、時系列のモーションデータなども画像に変換して扱うことができます。




