
大規模言語モデル(LLM)パラメータ「temperature, top_k, top_p」について【初級 深層学習講座】
Adaptive Pooling層の動きをわかりやすく解説【初級 深層学習講座】

Aru
timm(PyTorch Image Models)で用意されているモデルを利用した時、入力する画像のサイズが違っても問題なく動くことを不思議に思ったことはありませんか?この、任意の入力サイズに対応させる仕組みの1つが、Adaptive Poolingです。
この記事では、PyTorchのAdaptive Poolingの動きを確認しながら、任意の入力サイズに対応するトリックを見ていきたいと思います。
Contents
Adaptive Poolingとは
プーリング層(Pooling層)とは
Adaptive Poolingを説明する前に、一般的なPoolingについて説明します。
Pooling層は、畳み込みニューラルネットワーク(CNN)において、出力(特徴マップ)を集約する層です。

入力を間引いて出力する層と考えればわかりやすいかもしれません
この説明ではピンと来ないかと思いますが、要は100×100の特徴マップを入力して、2×2の領域で最大値・平均値などを取り、50×50の特徴マップを出力するといった処理になります。
プーリングを行うことで、特徴マップのサイズを小さくできるので、計算量を削減し、学習を効率よく行うことができるようになります。
プーリングの代表的は方法としては、以下のようなものがあります
- 最大値プーリング
各領域の最大値を代表値とする方法 - 平均値プーリング
各領域の平均値を代表値とする方法 - 中央値プーリング
各領域の中央値を代表値とする方法
Adaptive Pooling層とは
Pooling層は、特徴マップを集約する層ですが、プーリング領域のサイズで出力サイズが決まっていました。
一方、Adaptive Pooling(PyTorchの実装)では、出力のサイズを指定すると、出力サイズに合うようにプーリング領域のサイズが自動的に調整されます。
例えば、これまでのPooling層では、2×2の領域でプーリングを行う場合は、100×100の画像を入力すると出力サイズは50×50、150×150の画像を入力すると75×75となっていました。
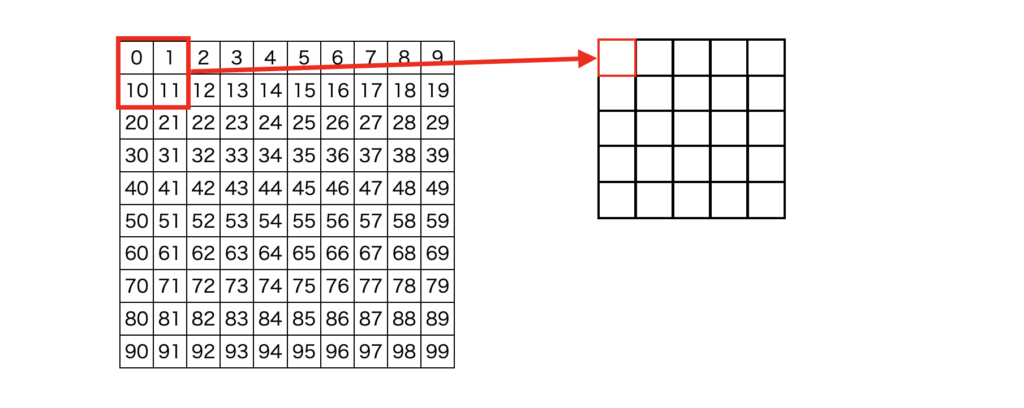
一方、Adaptive Pooling層は、出力サイズに50×50と設定すると、100×100の画像を入力すると2×2の領域で、150×150の画像を入力すると3×3の領域でプーリングが行われます。
このように、出力サイズを指定してプーリング領域のサイズが、入力と出力のサイズから適応的に決まり処理されるのがAdaptive Poolingになります。
この層の出力は、入力によらず一定になります
畳み込み層(CNN)の最後の出力の部分に、Adaptive Pooling層を挿入することで、CNNから出力される特徴マップのサイズを固定することが可能となります。
これが、入力画像サイズが違ってもtimmのモデル動作する理由です。
PyTorchで実際の動きを確認する
ここでは、PyTorchのAdaptive Pooling層の動きを確認してみます。
Pytorchのパッケージをインポート
Pytorchのパッケージをインポートします。torchだけインポートすればOKです。
import torch追加で、入力データを用意しておきます。今回の入力データは1×10×10のデータで、0から100までの連続した値とします。
x = torch.tensor([float(i) for i in range(100)]).reshape(1, 10, 10)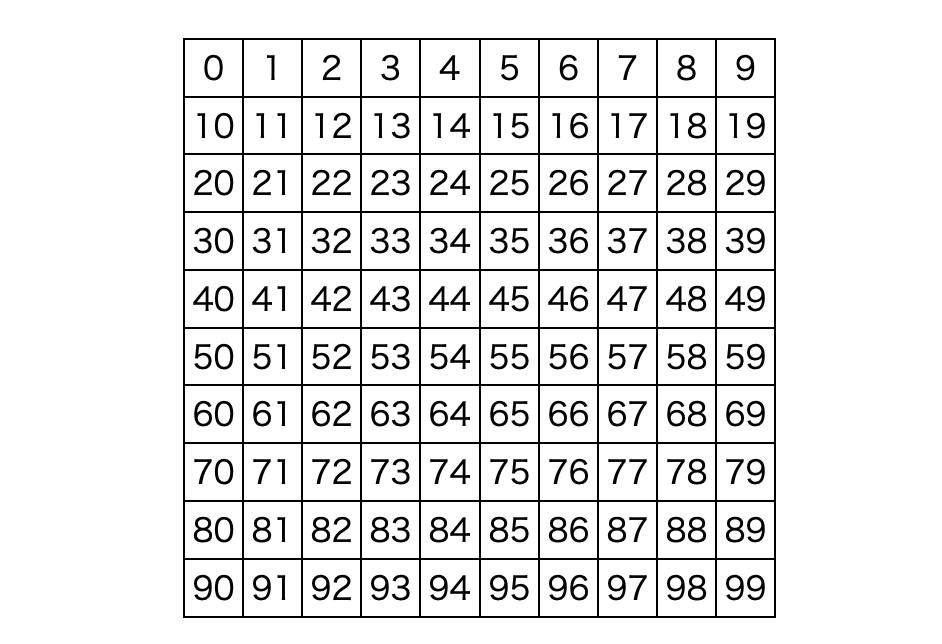
PyTorchのAdaptive Pooling層
Adaptive Poolingには、AdaptiveAvgPool2dとAdaptiveMaxPool2dの2つがあります。
- AdaptiveAvgPool2d 平均値プーリング
- AdaptiveMaxPool2d 最大値プーリング
AdaptiveAvgPool2d
AdaptiveAvgPool2dは平均値プーリングです。以下では、10×10を2×2の領域ごとに平均値を求めて5×5に縮小しています。
avepool = torch.nn.AdaptiveAvgPool2d((5, 5))
y = avepool(x)
y.shape, y最初の要素は5.5になっていますが、(0 + 1 + 10 + 11)/4 = 5.5なので、平均値になっていることがわかります。
(torch.Size([1, 5, 5]),
tensor([[[ 5.5000, 7.5000, 9.5000, 11.5000, 13.5000],
[25.5000, 27.5000, 29.5000, 31.5000, 33.5000],
[45.5000, 47.5000, 49.5000, 51.5000, 53.5000],
[65.5000, 67.5000, 69.5000, 71.5000, 73.5000],
[85.5000, 87.5000, 89.5000, 91.5000, 93.5000]]]))AdaptiveMaxPool2d
AdaptiveMaxPool2dは最大値プーリングです。先ほどと同様に、10×10を2×2の領域ごとの最大値を求めて5×5に縮小しています。
maxpool = torch.nn.AdaptiveMaxPool2d((5, 5))
y = maxpool(x)
y.shape, yこちらも、1つ目の要素を見るとmax(0, 1, 10, 11)=11なので、最大値になっていることが確認できます。
(torch.Size([1, 5, 5]),
tensor([[[11., 13., 15., 17., 19.],
[31., 33., 35., 37., 39.],
[51., 53., 55., 57., 59.],
[71., 73., 75., 77., 79.],
[91., 93., 95., 97., 99.]]]))Adaptive Poolingを試す
以下、AdaptiveAvgPool2dを使ってプーリングのパターンをいくつか試してみます。
パターン1(縮小)
先ほどのAdaptiveAvgPool2dの例と同じです。2×2の平均値が計算され5×5に縮小されています。
pooling = torch.nn.AdaptiveAvgPool2d((5, 5))
y = pooling(x)
y.shape, y(torch.Size([1, 5, 5]),
tensor([[[ 5.5000, 7.5000, 9.5000, 11.5000, 13.5000],
[25.5000, 27.5000, 29.5000, 31.5000, 33.5000],
[45.5000, 47.5000, 49.5000, 51.5000, 53.5000],
[65.5000, 67.5000, 69.5000, 71.5000, 73.5000],
[85.5000, 87.5000, 89.5000, 91.5000, 93.5000]]]))パターン2(同一サイズ)
出力が入力と同じサイズの場合はどうなるか確認しました。
結果としては、同じサイズの場合は入力の値がそのまま出力されます。
想定した動作です
pooling = torch.nn.AdaptiveAvgPool2d((10, 10))
y = pooling(x)
y.shape, y(torch.Size([1, 10, 10]),
tensor([[[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.],
[10., 11., 12., 13., 14., 15., 16., 17., 18., 19.],
[20., 21., 22., 23., 24., 25., 26., 27., 28., 29.],
[30., 31., 32., 33., 34., 35., 36., 37., 38., 39.],
[40., 41., 42., 43., 44., 45., 46., 47., 48., 49.],
[50., 51., 52., 53., 54., 55., 56., 57., 58., 59.],
[60., 61., 62., 63., 64., 65., 66., 67., 68., 69.],
[70., 71., 72., 73., 74., 75., 76., 77., 78., 79.],
[80., 81., 82., 83., 84., 85., 86., 87., 88., 89.],
[90., 91., 92., 93., 94., 95., 96., 97., 98., 99.]]]))パターン3(拡大)
入力に対して、出力サイズが大きい場合の動作も確認してみました。
縦横2倍のサイズの場合、同じ値が複製されて20×20の出力が行われました。
PytorchのAdaptive Poolingは、入力サイズ<出力サイズのパターンにも対応しています
pooling = torch.nn.AdaptiveAvgPool2d((20, 20))
y = pooling(x)
y.shape, y(torch.Size([1, 20, 20]),
tensor([[[ 0., 0., 1., 1., 2., 2., 3., 3., 4., 4., 5., 5., 6., 6.,
7., 7., 8., 8., 9., 9.],
[ 0., 0., 1., 1., 2., 2., 3., 3., 4., 4., 5., 5., 6., 6.,
7., 7., 8., 8., 9., 9.],
[10., 10., 11., 11., 12., 12., 13., 13., 14., 14., 15., 15., 16., 16.,
17., 17., 18., 18., 19., 19.],
[10., 10., 11., 11., 12., 12., 13., 13., 14., 14., 15., 15., 16., 16.,
17., 17., 18., 18., 19., 19.],
[20., 20., 21., 21., 22., 22., 23., 23., 24., 24., 25., 25., 26., 26.,
27., 27., 28., 28., 29., 29.],
[20., 20., 21., 21., 22., 22., 23., 23., 24., 24., 25., 25., 26., 26.,
27., 27., 28., 28., 29., 29.],
[30., 30., 31., 31., 32., 32., 33., 33., 34., 34., 35., 35., 36., 36.,
37., 37., 38., 38., 39., 39.],
[30., 30., 31., 31., 32., 32., 33., 33., 34., 34., 35., 35., 36., 36.,
37., 37., 38., 38., 39., 39.],
[40., 40., 41., 41., 42., 42., 43., 43., 44., 44., 45., 45., 46., 46.,
47., 47., 48., 48., 49., 49.],
[40., 40., 41., 41., 42., 42., 43., 43., 44., 44., 45., 45., 46., 46.,
47., 47., 48., 48., 49., 49.],
[50., 50., 51., 51., 52., 52., 53., 53., 54., 54., 55., 55., 56., 56.,
57., 57., 58., 58., 59., 59.],
[50., 50., 51., 51., 52., 52., 53., 53., 54., 54., 55., 55., 56., 56.,
57., 57., 58., 58., 59., 59.],
[60., 60., 61., 61., 62., 62., 63., 63., 64., 64., 65., 65., 66., 66.,
67., 67., 68., 68., 69., 69.],
[60., 60., 61., 61., 62., 62., 63., 63., 64., 64., 65., 65., 66., 66.,
67., 67., 68., 68., 69., 69.],
[70., 70., 71., 71., 72., 72., 73., 73., 74., 74., 75., 75., 76., 76.,
77., 77., 78., 78., 79., 79.],
[70., 70., 71., 71., 72., 72., 73., 73., 74., 74., 75., 75., 76., 76.,
77., 77., 78., 78., 79., 79.],
[80., 80., 81., 81., 82., 82., 83., 83., 84., 84., 85., 85., 86., 86.,
87., 87., 88., 88., 89., 89.],
[80., 80., 81., 81., 82., 82., 83., 83., 84., 84., 85., 85., 86., 86.,
87., 87., 88., 88., 89., 89.],
[90., 90., 91., 91., 92., 92., 93., 93., 94., 94., 95., 95., 96., 96.,
97., 97., 98., 98., 99., 99.],
[90., 90., 91., 91., 92., 92., 93., 93., 94., 94., 95., 95., 96., 96.,
97., 97., 98., 98., 99., 99.]]]))パターン4(割り切れないサイズ)
入力に対して割り切れないサイズの出力を設定しても問題なく動作します
pooling = torch.nn.AdaptiveAvgPool2d((3, 3))
y = pooling(x)
y.shape, y(torch.Size([1, 3, 3]),
tensor([[[16.5000, 19.5000, 22.5000],
[46.5000, 49.5000, 52.5000],
[76.5000, 79.5000, 82.5000]]]))ここまでのまとめ
以上のように、入力のサイズに関係なく、指定した出力サイズで出力できることがわかりました。このようにAdaptive Poolingを使うと、出力サイズを決めてプーリングを行うことができます。
timmのモデルのどこに使われているか調べてみる
resnet18で確認
実際にtimmのresnet18のモデルの、どの部分にAdaptive Pooling層が使われているのか確認してみました。以下は、確認に使ったコードです。
import timm
model = timm.create_model('resnet18')
print(model)確認すると、fc直前のglobal_poolに使われています。
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
:(略)
(aa): Identity()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): ReLU(inplace=True)
)
)
(global_pool): SelectAdaptivePool2d(pool_type=avg, flatten=Flatten(start_dim=1, end_dim=-1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
ただ、PytorchのAdaptve Poolingとは異なる関数です。このSelectAdaptivePool2dはどのようなものでしょうか。
SelectAdaptivePool2dとは?
SelectAdaptivePool2dは、timmで用意されているAdaptive Poolingの関数になります。動作自体はPyTorchのAdaptive Poolingと似ていますが、機能が拡張されています。
1つは、プーリングの種類を以下から選ぶことができるようになっています。
- avg :
平均プーリング - max
最大プーリング - avgmax
平均プーリングと最大プーリングの合計、0.5 で再スケーリング - catavgmax
特徴次元に沿った平均プーリングと最大プーリングの出力の連結。フィーチャの寸法が 2 倍になることに注意。
使い方は以下のようになります。flattenは、出力の次元を平坦化する指定です。これを指定することで、出力次元の次元を減らすことができます。例では、5チャンネルの10×10の特徴量マップを、各チャンネル1×1にし、さらに平坦化して出力しています。
pooling = SelectAdaptivePool2d(output_size=1, flatten=torch.nn.Flatten(start_dim=1, end_dim=-1), pool_type="avg")
x = torch.tensor([float(i) for i in range(500)]).reshape(1, 5, 10, 10)
pooling(x)tensor([[ 49.5000, 149.5000, 249.5000, 349.5000, 449.5000]])入力の(1, 5, 10, 10)は、(Batch, Channel, Height, Width)です。Flattenではbatch毎に5つの値が出力されるように、最初の次元だけ平坦化していません。

(1, 5, 10, 10)→(1, 5)になる形ですね
resnet18での動きは?
resnet18のAdaptive Poolingの定義を見ると以下のようになっています。
SelectAdaptivePool2d(pool_type=avg, flatten=Flatten(start_dim=1, end_dim=-1))つまり、例で示したように(B, C, H, W)のデータを(B, C)の形に変換してます
チャネル数は上のConv2dが512チャネル出力なので、このAdaptive Poolingを通過すると、チャネル数分の出力に固定されます。
なので、入力サイズによらずプーリング層の出力は固定されます。
実際に試してみます。create_modelでは、num_classes=0を指定するとglobal_poolの結果がそのまま出力されるようになります。
まず、256×256を入力してみました。
import timm
import torch
model = timm.create_model("resnet18", num_classes = 0)
x = torch.randn(1, 3, 256, 256)
y = model(x)
print(y.shape)結果は(1, 512)です
torch.Size([1, 512])次に、1024×768のサイズを入力してみます。
import timm
import torch
model = timm.create_model("resnet18", num_classes = 0)
x = torch.randn(1, 3, 1024, 768)
y = model(x)
print(y.shape)結果は(1, 512)です
torch.Size([1, 512])このように、入力サイズが違っても、Adaptive Poolingにより最終的な特徴マップのサイズが固定されていることが確認できました。
まとめ
入力サイズ可変に対応させるトリック、Adaptive Poolingについて説明しました。
こういう仕組みのおかげで、入力サイズが多少違ってもモデルが動作するようになっています。



ディープラーニングに関する記事一覧はこちら

ディープラーニング関連の記事一覧
ABOUT ME

専門分野は並列処理・画像処理・機械学習・ディープラーニング。プログラミング言語はC, C++, Go, Pythonを中心として色々利用。現在は、Kaggle, 競プロなどをしながら悠々自適に活動中



